Che fine ha fatto l’Exchange Management Console in Exchange 2013 ?
SQL Alert: Problema "Non-Yielding Scheduler"
IMPORTANTE: Questo post è il primo di questo tipo, lo scopo è allertare i Clienti e tutti gli interessati su problemi non solo di una certa gravità ma anche di ampia diffusione.
Nelle due ultime settimane ho riscontrato il seguente problema da ben quattro clienti su installazioni SQL Server 2008 e SQL Server 2008 R2:
"Non-yielding Scheduler" error and SQL Server 2008 or SQL
Server 2008 R2 stops responding intermittently in Windows Server 2008 or in
Windows Server 2008 R2
http://support.microsoft.com/kb/2491214/en-us
Impatto: processo SQL Server non responsivo;
Condizioni di applicabilità: Utilizzo del SQL Native Client 10.0 da parte dell'applicazione;
Evidenza del problema: messaggi nell'ERRORLOG;
Workaround: SI, vedi articolo;
Fix:
- Cumulative update package 2 for SQL Server 2008 Service Pack 2
- Cumulative update package 6 for SQL Server 2008 R2
Per i dettagli, ovviamente leggete con attenzione l'articolo, in caso di dubbi, problemi o complicazioni contattate il Vostro Technical Account Manager (TAM).
Buon lavoro a tutti.
--Igor Pagliai--
SQL CLR Functions and parallelelism
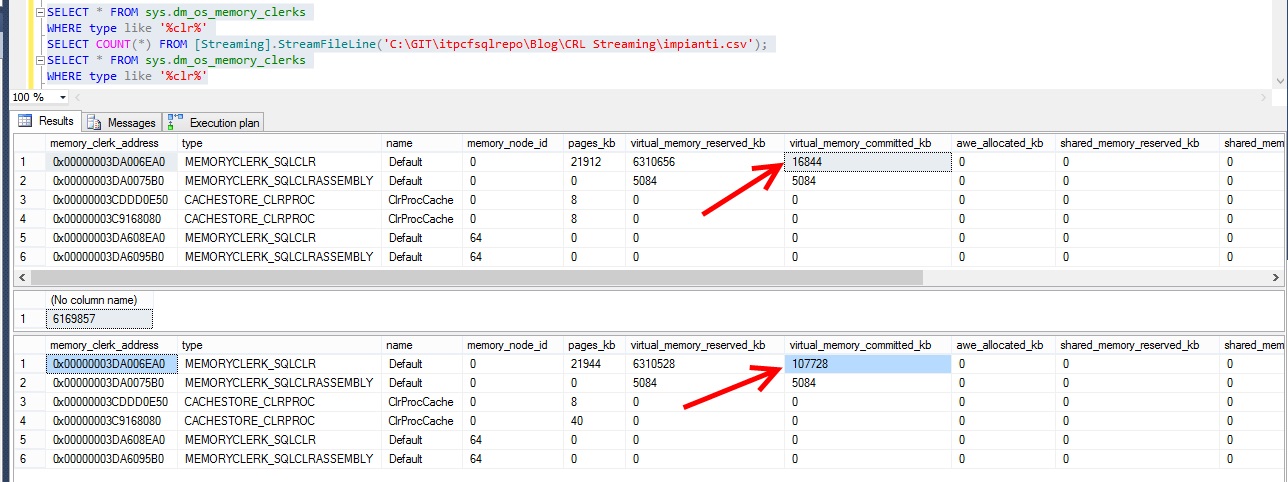
If you develop your own SQLCLR functions, you know you should decorate the method with this attribute class: [MSDN] SqlFunctionAttribute Class. You might wonder what these options will do. The DataAccess Property, according to the documentation, "Indicates whether the function involves access to user data stored in the local instance of SQL Server". You might be inclined to enable it regardless you actually need it. But what happens if you do? Let's try it first and then explain what happens.
First, create a SQLCRL Assembly with these two methods:
[SqlFunction (IsDeterministic = true, IsPrecise = true, DataAccess = DataAccessKind.None, SystemDataAccess = SystemDataAccessKind.None)] public static string NoAccess(string str) { return str.ToUpper(); } [SqlFunction (IsDeterministic = true, IsPrecise = true, DataAccess = DataAccessKind.Read, SystemDataAccess = SystemDataAccessKind.None)] public static string WithAccess(string str) { return str.ToUpper(); }
These functions are the same except for the DataAccess parameter. The NoAccess function sets it to None while the WithAccess one specifies Read. Now create a sample database and load the assembly in it:
CREATE DATABASE DemoCLR; GO USE DemoCLR; GO CREATE ASSEMBLY [Sample] FROM 'YourDLL.dll' WITH PERMISSION_SET=EXTERNAL_ACCESS; GO CREATE FUNCTION NoAccess (@txt NVARCHAR(MAX)) RETURNS NVARCHAR(MAX) EXTERNAL NAME [Sample].[Class].NoAccess; GO CREATE FUNCTION WithAccess (@txt NVARCHAR(MAX)) RETURNS NVARCHAR(MAX) EXTERNAL NAME [Sample].[Class].WithAccess; GO CREATE TABLE tbl(ID INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, SomeTxt NVARCHAR(255) NOT NULL); GO INSERT INTO tbl(SomeTxt) SELECT name FROM sys.objects; GO INSERT INTO tbl(SomeTxt) SELECT SomeTxt FROM tbl; GO 14
Now we can use them as in this TSQL:
SELECT SomeTxt FROM tbl WHERE dbo.NoAccess(SomeTxt) LIKE '%pip%';
The execution plan is this:
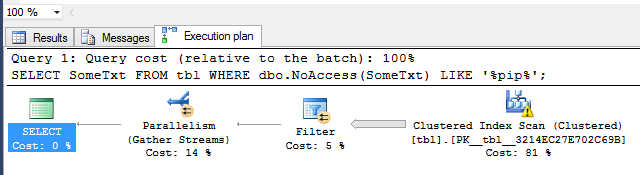 Note how SQL choose to parallelize this query. It makes sense since we wrote a non-sargable predicate leading to a full scan.
Note how SQL choose to parallelize this query. It makes sense since we wrote a non-sargable predicate leading to a full scan.
Let's look at the STATISTICS TIME too:
SQL Server Execution Times:
CPU time = 27831 ms, elapsed time = 4357 ms.
Note the elapsed time compared to the CPU time. Since our function is CPU bound having more than one core working in parallel speeded up our query (remember, CPU time is core cumulative).
Now try to do execute the same query with the WithAccess function:
SELECT SomeTxt FROM tbl WHERE dbo.WithAccess(SomeTxt) LIKE '%pip%';
It will take a while longer and the execution plan will be:
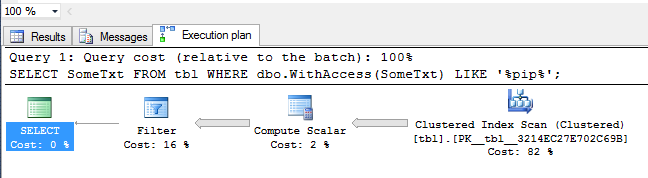
This is interesting: no parallelism was chosen by SQL Server. It's reflected in the STATISTICS TIME result too:
SQL Server Execution Times:
CPU time = 15584 ms, elapsed time = 15639 ms.
Here the elapsed time is bigger than the CPU Time (and the elapsed time is bigger than before). The moral of the story here is: allowing a SQLCLR function to access data context prevents the SQL Server optimizer from picking a parallel operator. So be careful when decorating your functions :). You might wonder why SQL Server would not execute your function in parallel in this case. Think about this: when you access data in your SQLCLR function you're expected to reuse the existing connection (called context connection). It's very efficient; you can read more about it here: [MSDN] Context Connection. The context connection is always one (and, no, MARS isn't supported). This means that SQL Server cannot call in parallel your function since only one instance at a given time can "own" the context connection.
Happy Coding,
Francesco Cogno
PS: Can you guess my sys.dm_os_schedulers configuration? ;)
SQL Server 2014 and Windows Azure Blob Storage Service: Better Together
Just a quick post to point you to this new SQL Server 2014 whitepaper: SQL Server 2014 and Windows Azure Blob Storage Service: Better Together. You will find many interesting best practices and a WSFC-like framework.
Summary:
SQL Server 2014 introduces significant new features toward a deeper integration with Microsoft Azure, thus unlocking new scenarios and provide more flexibility in the database space for IaaS data models. This technical article will cover in depth SQL Server 2014 Data Files on Azure Blob storage service, starting from step-by-step configuration, then providing guidance on scenarios, benefits and limitations, best practices and lessons learned from early testing and adoption. Additionally, a fully featured example of a new (Windows Server Failover Clustering) - like feature will be introduced to demonstrate the power of Microsoft Azure and SQL Server 2014 when combined together.
Happy coding,
Francesco Cogno
SQL Server 2014 Dynamic-link library load
Have you ever wondered how SQL Server 2014 accomplishes the "Native compilation" feature? In this post I'll show you how to inspect what SQL Server is doing behind the scenes while "compiling" your native code. This will be a deep post that will require a non production instance since we will restart it many times.
In order to inspect sqlservr.exe we will use a powerful tool called Dependency Walker. You can find it in many Microsoft distribution kits; the author, however, keeps an update page with the latest binaries: you can get them here: http://dependencywalker.com/.
Dependency walker allows you – among other things - to inspect dynamic DLL handling by user code. That is exactly what SQL Server is doing when loading your native compiled code into its own address space.
SQL Server will perform these tasks:

For each natively compiled entity. Note that is just an oversimplification meant to show what happens in that specific moment. There is a lot more involved before (Mixed Abstract Trees, Pure Imperative Trees, etc…) and afterwards of course.
First, we need to start dependency walker and ask it to open the main SQL Server executable. If you have trouble finding the right exe you can use the SQL Configuration Manager:
Once open Dependency walker will show you the module linked by the executable. You will find the familiar DLLs here:
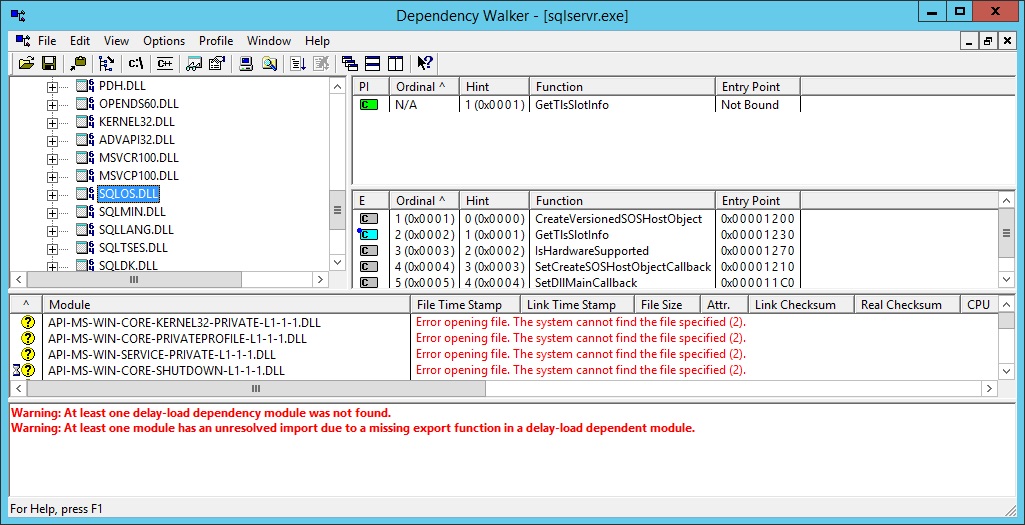
This is, however, the static representation of sqlservr.exe. Dependency walker is able to inspect a running instance of that executable much like a debugger does. This is very helpful since we want to show what happens during a native compilation.
Select Start profile from Profile menu:
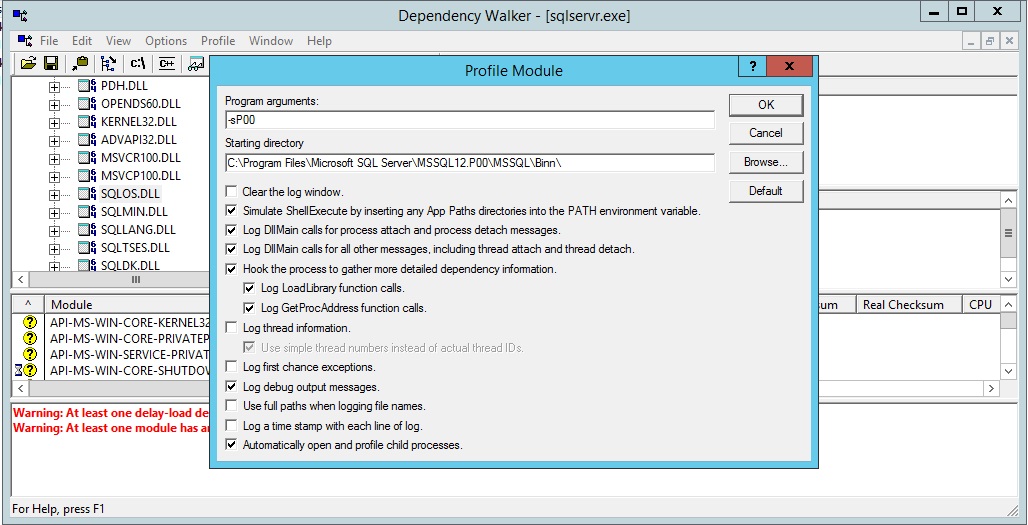
As you can see we are starting sqlservr.exe from scratch. You will need to shut down the running instance first (there cannot be two instances owning the same files) and copy the relevant parameters from the configuration manager. If you want more details on how to start SQL Server from command line please refer here: http://technet.microsoft.com/en-US/library/ms180965(v=SQL.105).aspx.
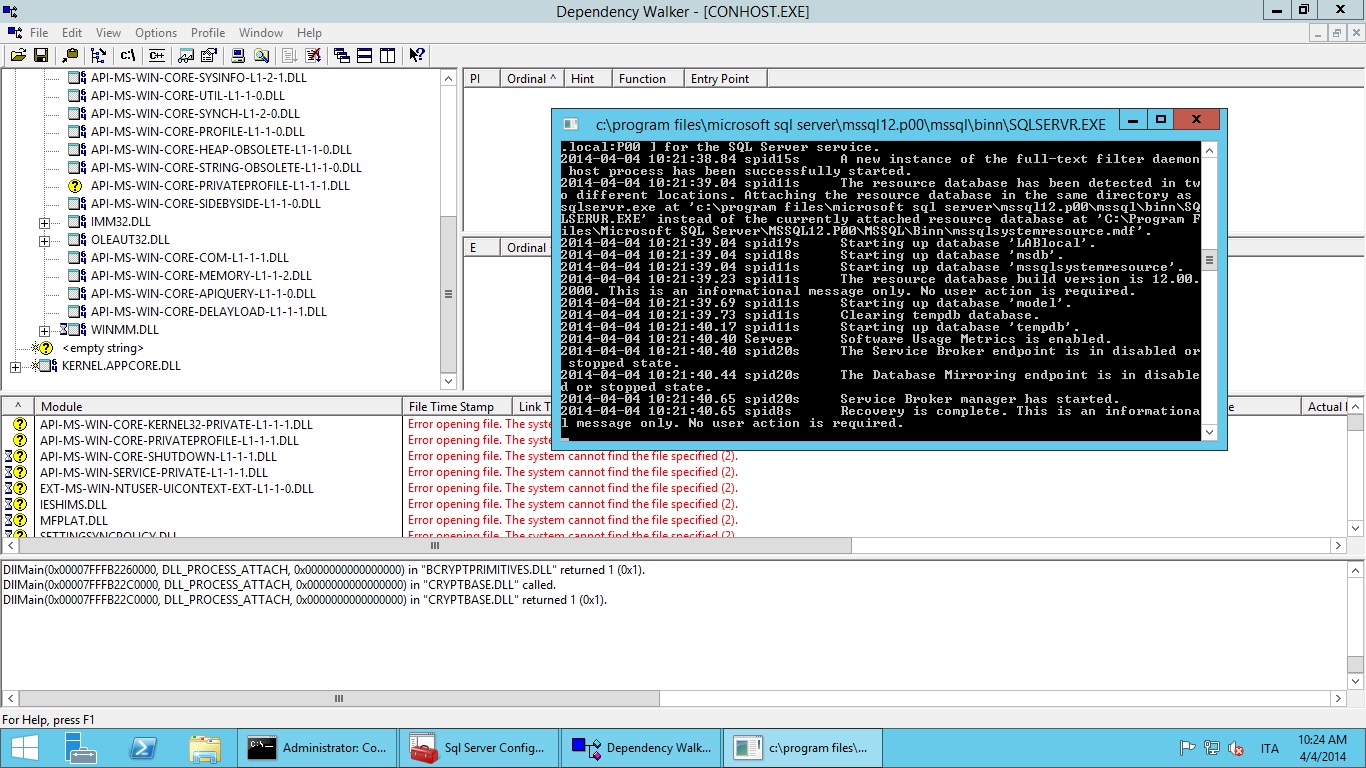
You will see the console popping out: just wait for SQL Server to finish its initialization (note: if you already have many natively compiled entities the startup will take a while; this is normal and the reason of if should become clear in a moment).
Before proceding further let's look at the Window menu of Dependency Walker:
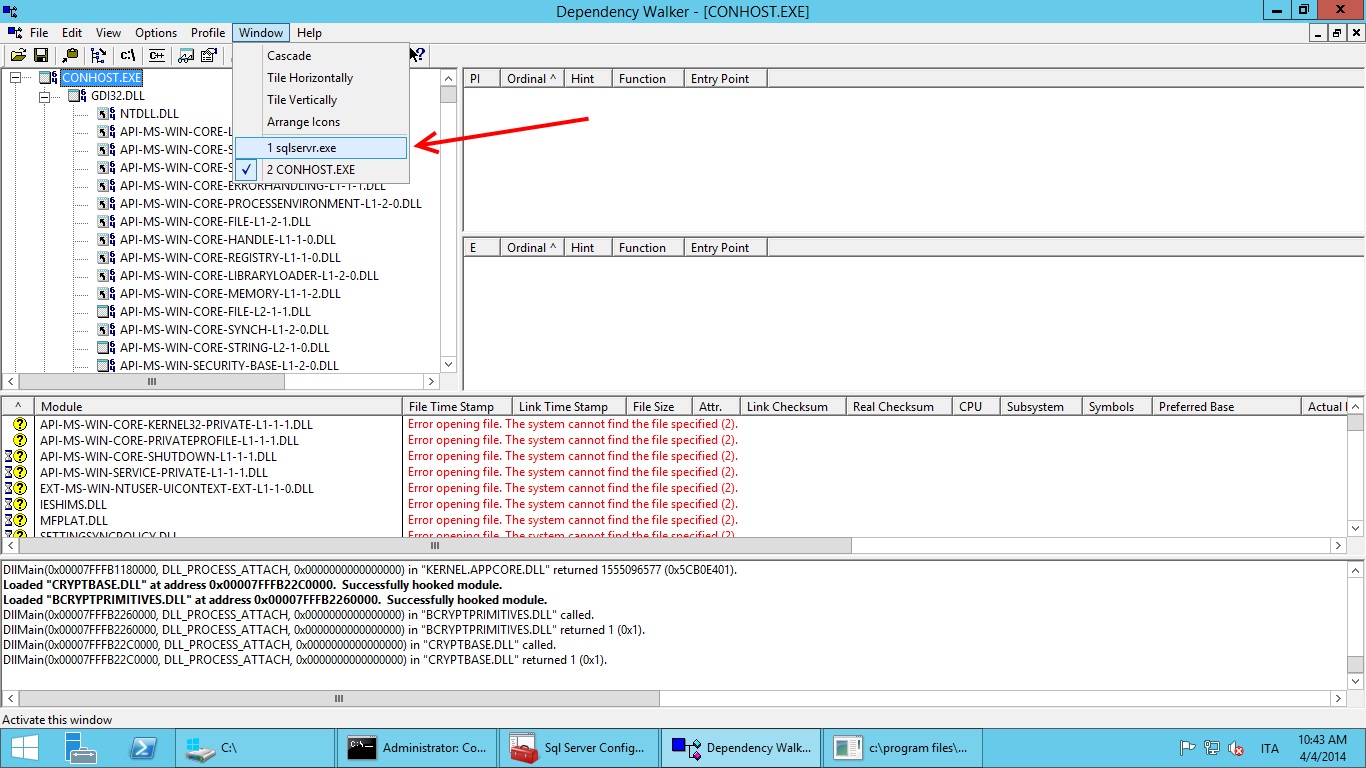
Notice that SQL Server has spawned another process during its startup: CONHOST.exe. DW will show the latest process spawned as default so we need to select sqlservr.exe back before proceeding further.
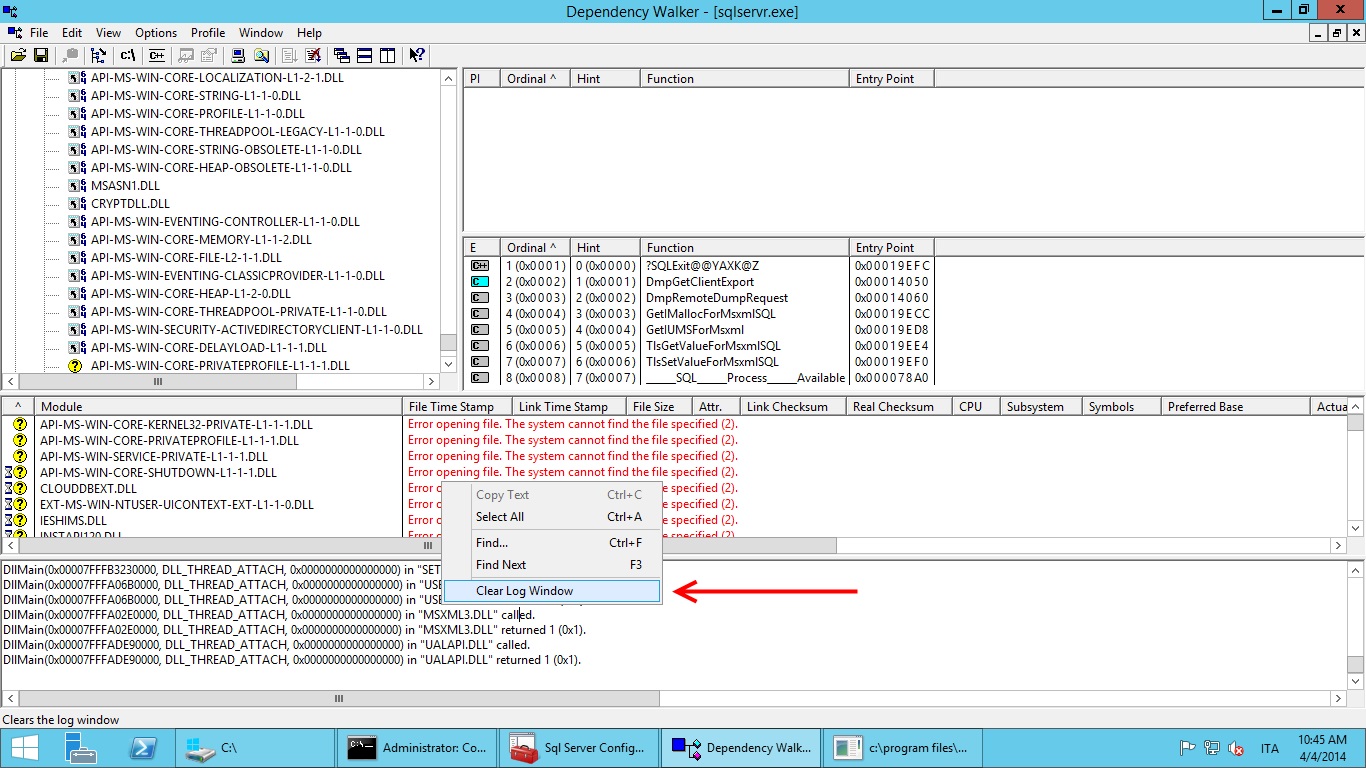
If you want you can clear the Dependency Walker's log window now:
 Now that our instance is running and Dependency Walker is actively monitoring it we can create a demo database on it (we can use SSMS, sqlcmd, whatever you like):
Now that our instance is running and Dependency Walker is actively monitoring it we can create a demo database on it (we can use SSMS, sqlcmd, whatever you like):
CREATE DATABASE [NativeDemo] ON PRIMARY ( NAME = N'NativeDemo_data', FILENAME = N'C:\Demo\NativeDemo_data.mdf'), FILEGROUP [InMemoryOLTP_InMemory] CONTAINS MEMORY_OPTIMIZED_DATA ( NAME = N'NativeDemo_memopt', FILENAME = N'C:\Demo\NativeDemo_memopt') LOG ON ( NAME = N'NativeDemo_log', FILENAME = N'C:\Demo\NativeDemo_log.ldf') GO
Now we try and create a natively compiled table. Note that as soon as we start the batch Dependency Walker will start to output info (that's what we wanted in the first place) and slow down the batch considerably:
USE [NativeDemo]; GO CREATE TABLE [Customer]( [PKIDBucketCount64] INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 64), [AnINTField] INT NOT NULL, [AVarchar200Field] VARCHAR(200) NOT NULL, [ANVarchar500Field] NVARCHAR(500) NOT NULL ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); GO
If all went well we should have our own table. Now go back to Dependency Walker and look at the Window menu:
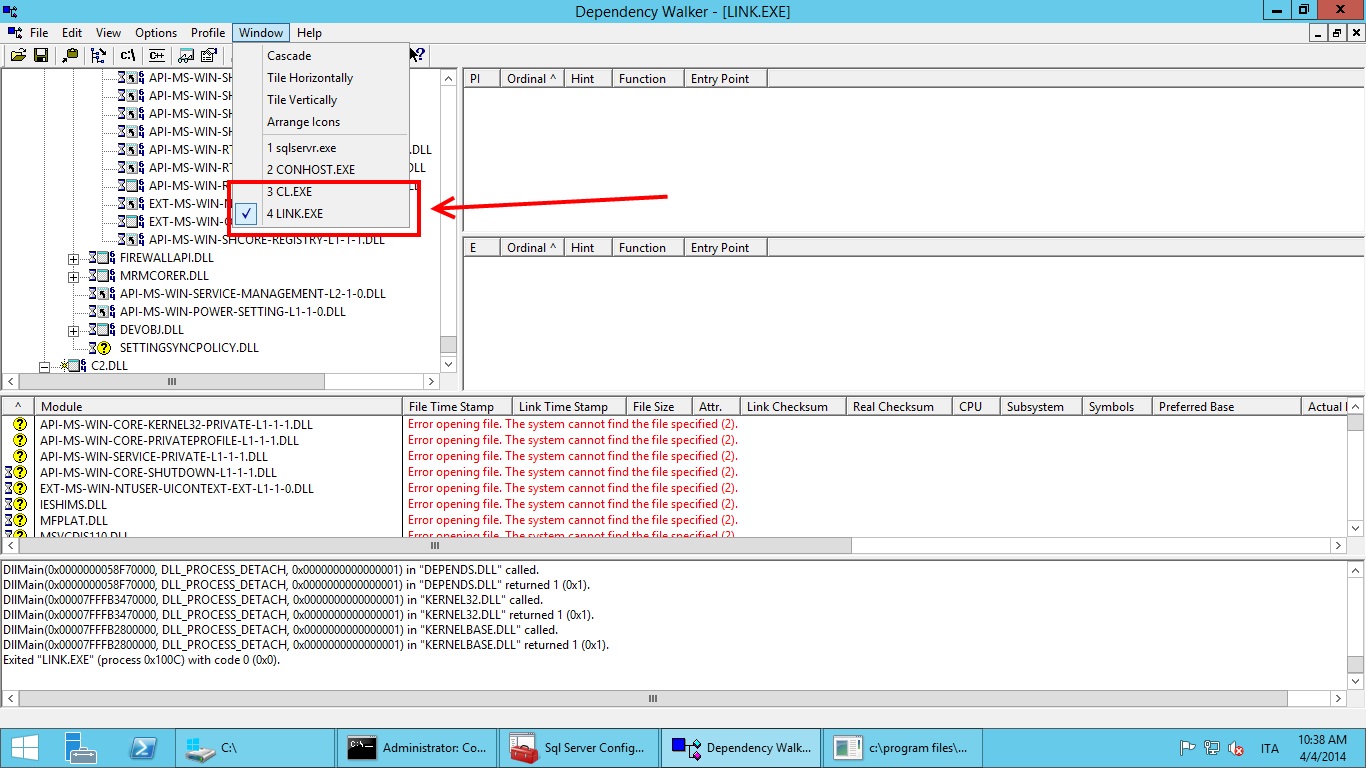
As we can see there are two new processes captured by Dependency Walker: CL.exe and LINK.exe. These are the compiler and the linker processes spawned by SQL Server for the native compilation of our table.
Let's start selecting CL.exe.
If we scroll all the way up in the log we will find something like this:
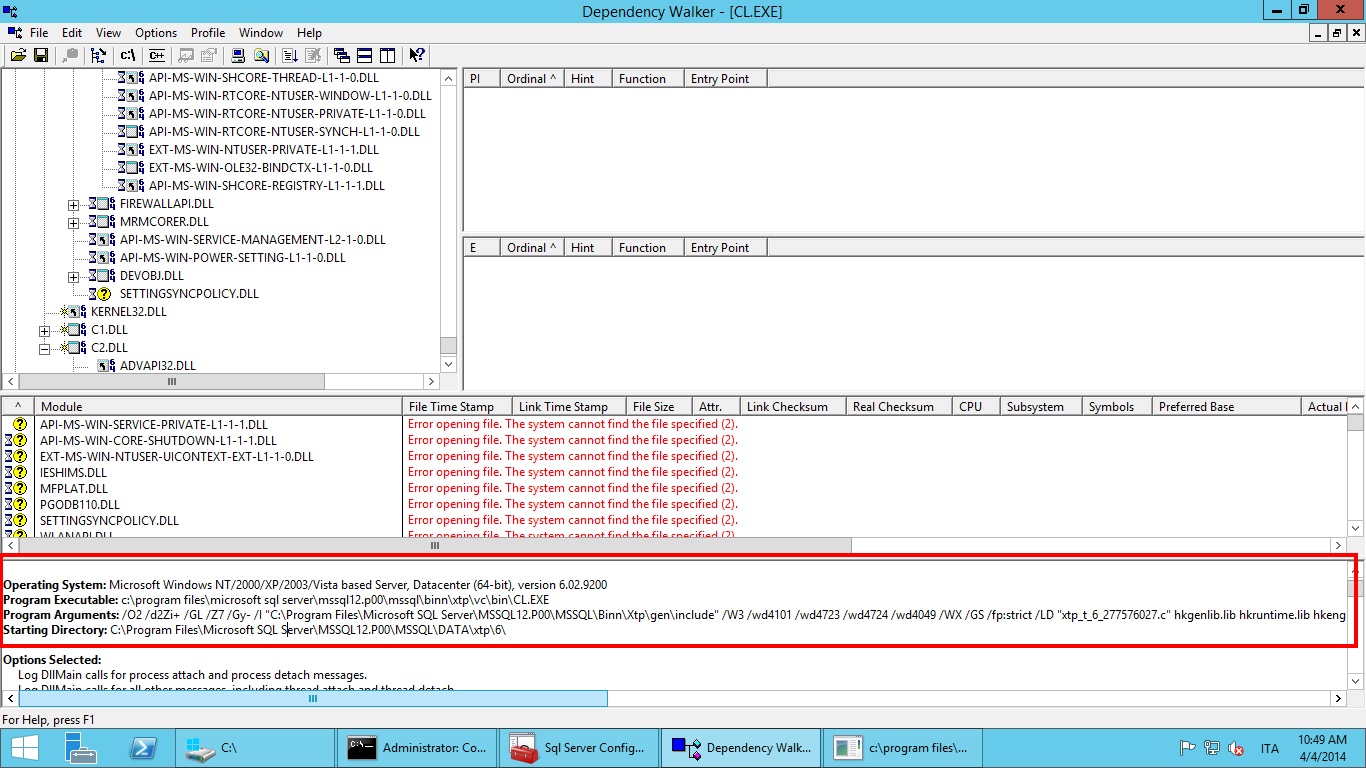
Worth noting here are the command line parameters. In my case they were:
Program Arguments: /O2 /d2Zi+ /GL /Z7 /Gy- /I "C:\Program Files\Microsoft SQL Server\MSSQL12.P00\MSSQL\Binn\Xtp\gen\include" /W3 /wd4101 /wd4723 /wd4724 /wd4049 /WX /GS /fp:strict /LD "xtp_t_6_277576027.c" hkgenlib.lib hkruntime.lib hkengine.lib hkgenexp.exp hkcrt.lib hkk32.lib hkversion.obj /link /LIBPATH:"C:\Program Files\Microsoft SQL Server\MSSQL12.P00\MSSQL\Binn\Xtp\gen\lib" /LIBPATH:"C:\Program Files\Microsoft SQL Server\MSSQL12.P00\MSSQL\Binn\Xtp\VC\lib" /noentry /nodefaultlib /incremental:no /ltcg /wx /FUNCTIONPADMIN
If you have experience in C Windows coding you will recognize many of them. Just to point a few, notice the /7Z flag that helps debugging; for the performance point of view notice the /O2 flag that asks the compiler to perform code optimization favoring speed over size (see http://msdn.microsoft.com/en-us/library/8f8h5cxt.aspx) while the /fp:strict flag forces the floating point operations to favor precision over speed (see http://msdn.microsoft.com/en-us/library/e7s85ffb.aspx).
Now if we switch to SQL Server process, we should see something like this:
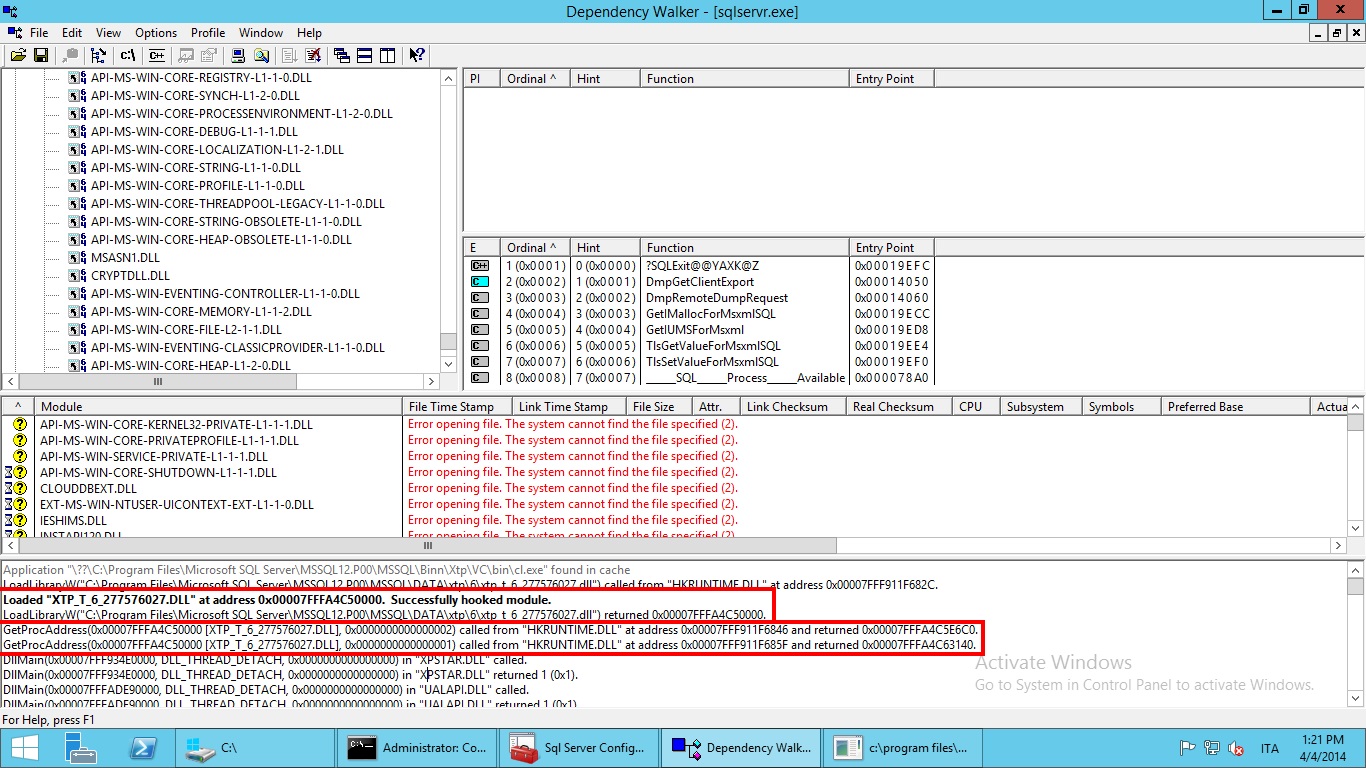
Notice two things here:
Now SQL Server 2014 can call the compiled functions just pointing at the (local) address given by GetProcAddress.
Happy Coding,
Francesco Cogno
SQL Server To Windows Azure helper library - A SQL Server open source CodePlex project
Hi all,
since my last SQLRally presentation in Amsterdam people kept asking for a working build of the SQLCLR Windows Azure REST API DLL. Many snippets of it can be found in this blog; however most of you don't really care about the implementation boilerplate. On the contrary, some of you might actually like to contribute to this library. In order to please everyone I've created - with the help of a fellow PFE Matteo Teruzzi - a GIT enabled open source project hosted on CodePlex. You can find it here (https://sqlservertoazure.codeplex.com/).
For those unfamiliar with CodePlex, just know that you can:
- Download a precompiled DLL to import in your Database (easy). You can also download a sample script to test the library in a matter of minutes.
- Download the source code to build your own copy (I'll explain in a moment why you should do that).
- Just browse come class straight from your browser.
- Post comments!
- Create issue tasks for the community to correct.
- Start a discussion for a feature to implement.
Right now the project needs - badly - a proper documentation (as it is now there's just an empty page) and a bunch of willful testers.
Please note that this is a pet project so I cannot guarantee any support. The full license is here (https://sqlservertoazure.codeplex.com/license); it's a the standard Mozilla Public License Version 2.0.
As I said the library can be used in its compiled form. I, however, encourage you to build you own version.
First of all you should replace the dummy snk file with your own. This is fairly straightforward, all you have to do is to right click every library and change the strong name key file:

If you don't have a strong name key file you can generate one using the sn.exe utility that ships with the Microsoft SDK. The syntax is just:
sn -k <output_file_name.snk>
Second if you want to use the [Azure.Embedded] schema you need to customize the Connections.xml file embedded into the library:
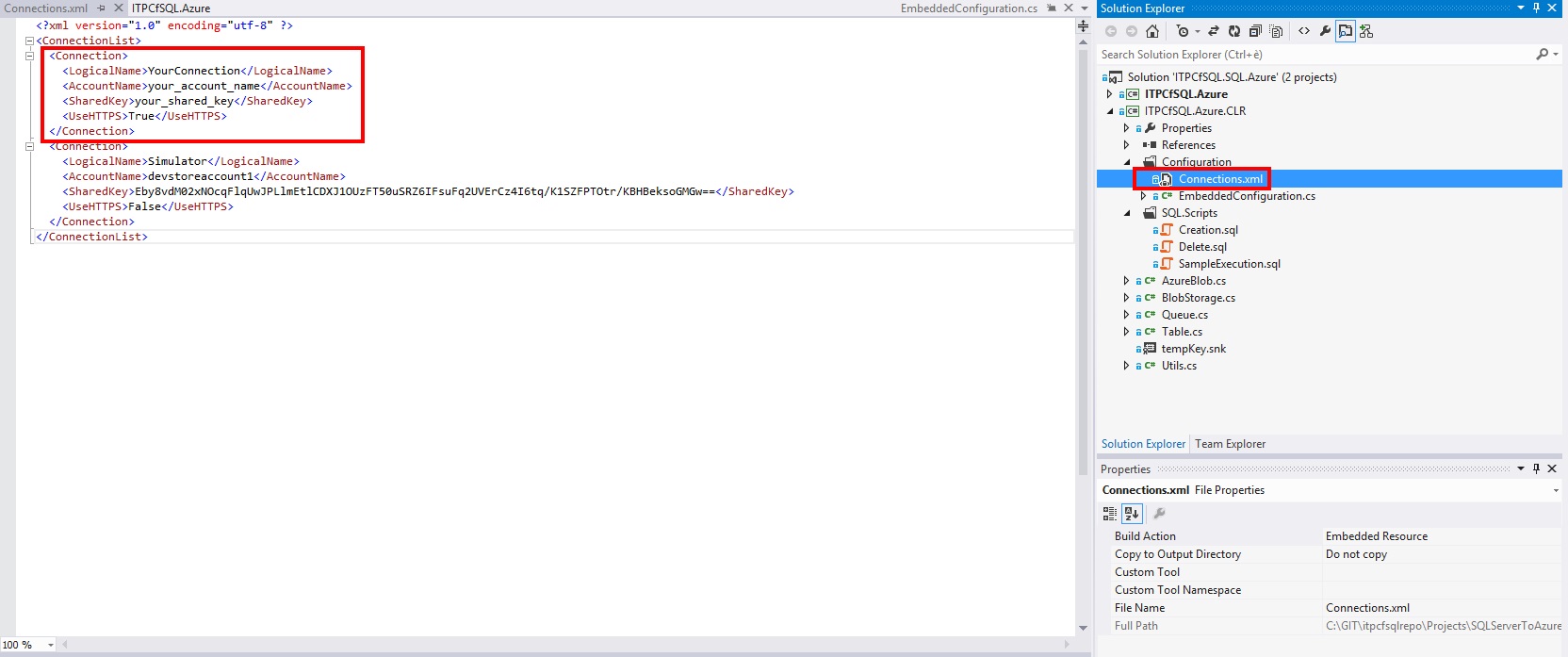
As you can see in the image above there are two account already configured (a dummy one and the simulator). All you have to do is to add a Connection section for each account you want to be able to address without specifying all the parameters in the T-SQL (as I've done in my SQLRally presentation). For example, if you have an Azure Storage account called myazurestorageaccount and one of your shared keys is Eby8vdM02xNOcqFlqUwJPLlmEtlCDXJ1OUzFT50uSRZ6IFsuFq2UVErCz4I6tq/K1SZFPTOtr/KBHBeksoGMGw== you can add a section like this one:
<Connection> <LogicalName>azurestorage</LogicalName> <AccountName>myazurestorageaccount</AccountName> <SharedKey>Eby8vdM02xNOcqFlqUwJPLlmEtlCDXJ1OUzFT50uSRZ6IFsuFq2UVErCz4I6tq/K1SZFPTOtr/KBHBeksoGMGw==</SharedKey> <UseHTTPS>True</UseHTTPS> </Connection>
Recompile your library, import it into SQL Server and you should be able to call the [Azure.Embedded] schema functions/SPs specifying azurestorage as logical connection name.
Note: you can find all those parameters in the Windows Azure management portal (https://manage.windowsazure.com) clicking the "Manage Access Keys button" in the lower bar:
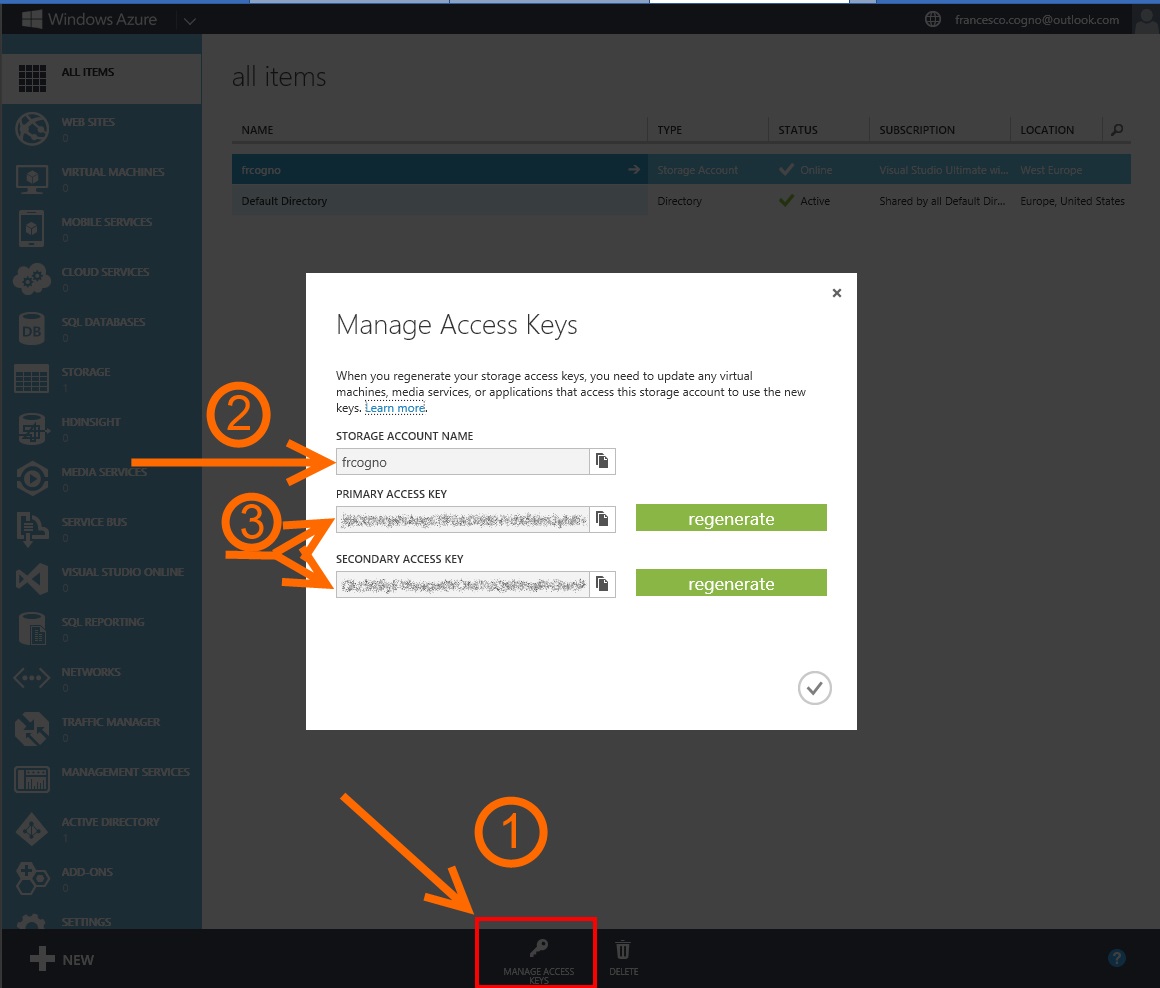
Third you might want to expose only a few selected methods/SPs instead of all of them. In order to do so all you have to do is to comment the relevant method in ITPCfSQL.Azure.CLR and recompile.
Happy coding,
Francesco Cogno
SQL vs. SEQUEL
Post un po' anomalo questo, ma visto che ultimamente sia clienti che colleghi mi hanno girato, in varie forme, la seguente domanda, perché non scriverci sopra due righe così la prossima volta girerò direttamente un link ?
La domanda è questa:
Perché l'acronimo SQL non viene pronunciato in stretta osservanza alla pronuncia inglese ?
In effetti è vero, il modo in cui viene pronunciato tale acronimo, che sta per "Structured Query Language" corrisponde al termine "SEQUEL" e non "SQL".
Dopo un attimo di smarrimento iniziale mi sono ricordato di quanto mi aveva detto il mio vecchio professore di informatica delle scuole superiori (grazie prof.Vasellini ! :-) ) e da buon ex-IBM mi svelò il mistero i cui dettagli potete trovare su Wikipedia e di cui qui riassumo la frase chiave:
http://it.wikipedia.org/wiki/SQL
"….L' SQL nasce nel 1974 ad opera di Donald Chamberlin, nei laboratori dell'IBM. Nasce come strumento per lavorare con database che seguano il modello relazionale. A quel tempo però si chiamava SEQUEL (la corretta pronuncia IPA è [ˈɛsˈkjuˈɛl], quella informale [ˈsiːkwəl]). Nel 1975 viene sviluppato un prototipo chiamato SEQUEL-XRM; con esso si eseguirono sperimentazioni che portarono, nel 1977, a una nuova versione del linguaggio, che inizialmente avrebbe dovuto chiamarsi SEQUEL/2 ma che poi divenne, per motivi legali, SQL."

Che dire ? Grazie Big Blue…. :-)
--Igor Pagliai—
SQLCLR: string or SqlString?
One of the most asked question regarding the SQL CRL is whether to use string instead of System.Data.SqlString (see [MSDN] SqlString Structure for further details). You might guess that, from a performance point of view, using string is better. Let's confirm (or reject) this assumption. First we need to create two very simple SQLCLR functions:
[SqlFunction( DataAccess=DataAccessKind.None, SystemDataAccess=SystemDataAccessKind.None, IsDeterministic=true, IsPrecise=true)] public static string UseString(string input) { return input; } [SqlFunction( DataAccess = DataAccessKind.None, SystemDataAccess = SystemDataAccessKind.None, IsDeterministic = true, IsPrecise = true)] public static SqlString UseSqlString(SqlString sqlinput) { return sqlinput; }
As you can see we just return the parameter received without even touching it. Note, however, the different types between the two functions.
In order to map there functions in our SQL Server instance we can use this code:
SET NOCOUNT ON; GO USE [master]; GO CREATE DATABASE DemoCLR; GO ALTER DATABASE DemoCLR SET RECOVERY SIMPLE; GO USE DemoCLR; GO CREATE SCHEMA [CLR]; GO CREATE ASSEMBLY [ClassLibrary1] FROM 'c:\yourpath\bin\Debug\ClassLibrary1.dll'; GO CREATE FUNCTION [CLR].UseString(@input NVARCHAR(255)) RETURNS NVARCHAR(255) AS EXTERNAL NAME [ClassLibrary1].[ClassLibrary1.Class1].UseString; GO CREATE FUNCTION [CLR].UseSqlString(@input NVARCHAR(255)) RETURNS NVARCHAR(255) AS EXTERNAL NAME [ClassLibrary1].[ClassLibrary1.Class1].UseSqlString; GO
This T-SQL batch will create a test DB and load the assembly in it.
Now, in order to test them we should create a dummy table:
CREATE TABLE tbl(ID INT IDENTITY PRIMARY KEY CLUSTERED, Txt NVARCHAR(255)); GO INSERT INTO tbl(Txt) VALUES(CONVERT(NVARCHAR, GETDATE())); GO 1000 INSERT INTO tbl(Txt) SELECT Txt FROM tbl; GO 10
This script will load a million rows in our table called tbl. Now the test code itself:
USE DemoCLR; GO DECLARE @dt DATETIME DECLARE @tbl TABLE(Txt NVARCHAR(255)); SET @dt = GETDATE() INSERT INTO @tbl(Txt) SELECT [CLR].UseString(Txt) FROM tbl; PRINT N'String ' + CONVERT(NVARCHAR(255), DATEDIFF(MS, @dt, GETDATE())) + N' ms.'; GO DECLARE @dt DATETIME DECLARE @tbl TABLE(Txt NVARCHAR(255)); SET @dt = GETDATE() INSERT INTO @tbl(Txt) SELECT [CLR].UseSqlString(Txt) FROM tbl; PRINT N'SqlString ' + CONVERT(NVARCHAR(255), DATEDIFF(MS, @dt, GETDATE())) + N' ms.'; GO
These two batches will call the function for each row. The results, in my case, are like these:
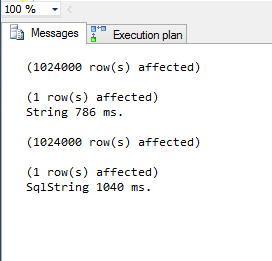
Notice the higher time for the SqlString function, as expected. Notice, however, that the time difference is fairly small. Given that – even slight – time advantage you may not want to use the string directly. But, in fact, what's the purpose of SqlString anyway? The purpose is, as explained in the MSDN in the Remarks session:
String always uses the default CultureInfo from the current thread, but SqlString contains its own locale Id and compare flags. The comparison result of two SqlString structures is independent of operating system and current thread locale.
In our SQL Server terms it means that SqlString is aware of the collation setting of your database. That's very important since we know that string comparison is always case sensitive but, in SQL Server, it depends of the collation settings.
In order to test that we add two more SQLCLR functions:
[SqlFunction( DataAccess = DataAccessKind.None, SystemDataAccess = SystemDataAccessKind.None, IsDeterministic = true, IsPrecise = true)] public static bool CompareString(string input1, string input2) { return input1.Equals(input2); } [SqlFunction( DataAccess = DataAccessKind.None, SystemDataAccess = SystemDataAccessKind.None, IsDeterministic = true, IsPrecise = true)] public static SqlBoolean CompareSqlString(SqlString input1, SqlString input2) { return input1.Equals(input2); }
In this case we just test for equality (question: will using the = operator yield the same result?).
Now use them to compare two strings: Test and TEST.
If we use a case sensitive collation:
use [master] GO ALTER DATABASE DemoCLR COLLATE SQL_Latin1_General_CP1_CS_AS ; GO USE DemoCLR; GO SELECT collation_name, [CLR].CompareString('Test', 'TEST') AS 'StringCompare', [CLR].CompareSqlString('Test', 'TEST') AS 'SqlStringCompare', IIF('Test' = 'TEST', 1, 0) AS 'SQLCompare' FROM sys.databases WHERE name = 'DemoCLR'; GO
The result is:

Both string and SqlString return false. But what about a case insensitive collation?
use [master] GO ALTER DATABASE DemoCLR COLLATE SQL_Latin1_General_CP1_CI_AS ; GO USE DemoCLR; GO SELECT collation_name, [CLR].CompareString('Test', 'TEST') AS 'StringCompare', [CLR].CompareSqlString('Test', 'TEST') AS 'SqlStringCompare', IIF('Test' = 'TEST', 1, 0) AS 'SQLCompare' FROM sys.databases WHERE name = 'DemoCLR'; GO
In this case the result is:

So in this case only SqlString comparison behaved as expected: using SqlString shielded our code from the collation complexities!
Happy coding,
Francesco Cogno



{kind=link}
Comments
Post a Comment