Skip to main content
Exchange 2013 High Availability
SQL Server chez les clients – Self-Service BI et Microsoft Azure Machine Learning

Analyse de données et Machine Learning
Les métiers et professionnels ont un besoin croissant d'analyse de données diverses mais au-delà de la simple analyse nous devons de plus en plus comprendre nos données, les extrapoler, en déduire des prédictions, analyser le passé pour comprendre le futur, en déduire des comportements et prendre des actions ou décisions.
Microsoft s'intègre dans cette vision Big Datas et compréhension de la donnée de différentes façons toutes adaptées à différents usages :
- Microsoft HDInsightplatform
- Microsoft Hortonworks
- Microsoft Azure Machine Learning
- Microsoft Analysis Services DataMining
Nous n'allons pas faire une nouvelle description du big datas, chacun pourra intégrer cette notion à son projet suivant différents axes qui lui sont propres, mais nous allons parcourir les nouveaux usages et expliquer les fondements du machine learning au travers de la self-service BI connecté à la nouvelle plateforme Microsoft Azure Machine Learning.
Concept de "Machine Learning"
Le Machine Learning est une science qui permet de créer des systèmes qui vont apprendre des données, qu'elles soient connues, non connues et externes.
Le ML est une approche par les données répondant à une problématique métier. La résolution repose sur des patterns non connus, à découvrir, entrainer et optimiser.
Les process sous-jacents vont apprendre des données internes, externes et surtout vont s'adapter à d'éventuels changements de paramètres externes.
Le cœur de la technologie repose sur un ensemble d'algorithmes complexes, certains déjà présent dans certains outils par exemple Analysis Services depuis plusieurs versions.
Les quatre caractéristiques principales d'un système de machine learning performant sont les suivantes :
- Accurate : Plus le système absorbe de données plus la précision du modèle sera élevée
- Fast : Le système doit pouvoir exposer des interfaces pour soumettre des données et obtenir des réponses rapidement
- Scalable : Un tel système doit être scalable donc pouvoir croitre au fur et à mesure que le volume de données à traiter augmente
- Automated : Lors de la soumission d'une nouvelle entrée le système estime une réponse dans un workflow automatisé
Une définition du Machine Learning peut-être décrite par le schéma suivant:
X = les variables en entrée, y = les variables en sortie et h les variables cachées.
Les algorithmes de machine learning permettent de découvrir les relations entre les variables du système, qu'elles soient en entrée, sortie ou cachée depuis un extrait des données du système.
Ci-après vous trouverez plusieurs types de Machine Learning
- Learning association : Trouver des relations entre les données (market basket analysis)
- Supervised Learning : Classification ,Regression
- Unsupervised Learning : Seules les données en entrées sont disponibles et nous cherchons les régularités dans ces données
- Reinforcement Learning : Chercher un comportement qui associe un état à une action
- Etc.
L'approche Microsoft Azure Machine Learning
Microsoft accompagne ses clients en mettant à disposition à disposition des services Cloud permettant aux utilisateurs de mieux comprendre leurs données et d'en faire naitre des scénarios complexes pour des prises de décisions basées sur des analyses prédictives.
Pour illustrer l'approche nous allons par exemple étudier la classification à l'aide d'un algorithme de Clustering de type k-means.
La compréhension de cet algorithme est la suivante :
Sélection des entrées Sélection des k clusters (training datas)


Attribution sur le centre le plus proche et mise à jour des centres des clusters
Réassignation des entrées et répétition jusqu'à obtenir la convergence

Cette approche va permettre de classifier des données (clients, produits, etc.) suivant un nombre finit d'attributs. Dès lors Microsoft Azure Machine Learning permet d'exposer la fonction de classification sous la forme d'un web service qui sera accessible pour classifier en temps réel une nouvelle donnée entrante.
Pour avoir une présentation de l'interface de Microsoft Azure Machine Learning vous pouvez accéder à l'url suivante qui vous donnera plus de détail :https://azure.microsoft.com/en-us/campaigns/machine-learning/
Ce qui est intéressant c'est de croiser l'utilisation de Microsoft Azure ML avec de la Self-Service BI, mais comment faire ?
Imaginons que nous voulions classifier une ensemble de céréales suivant leurs apports caloriques, taux de graisse, etc. (nous pouvons extrapoler cette approche à des besoins plus business oriented).
Les étapes sont les suivantes :
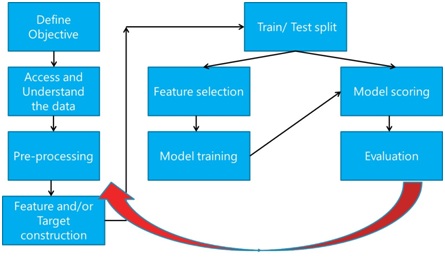
Mais concrètement comment cela se passe ? Il vous suffira de suivre les étapes suivantes :
1. Déployer le dataset sur Microsoft Azure ML
Dans cette première étape nous prendrons un fichier .csv au format suivant:

2. Définir le modèle, c'est à dire spécifier dans l'interface Microsoft Azure ML les attributs qui vont participer à la classification des éléments.
3. Intégrer l'algorithme de k-meansclustering comme algorithme à appliquer à nos données
4. Entrainer le modèle
5. Evaluer le modèle
6. Consulter les résultats de classification
7. Dès lors des résultats sont visibles sous la forme de courbes statistiques. Le point intéressant est de consommer ces données en sortie directement dans notre solution de self-service BI.
Nous avons pour l'instant un dataset sur Azure, une solution qui permet de faire ma classification et nous choisissons en interface de sortie un blob storage azure que nous pouvons parcourir à l'aide de Microsoft Management Studio.
Cet Azure Storage Account dispose de l'ensemble des simulations de clustering faites du dataset en entrée préalablement chargé et analysé.
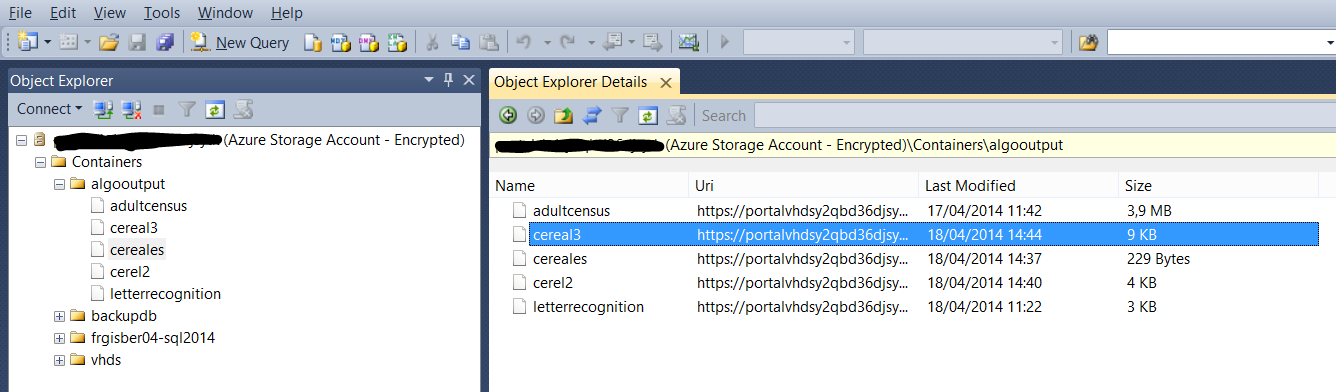
Le format de sortie est spécifié dans la destination, celui-ci se présente de la façon suivante :
"N","C",70,4,1,130,10,5,6,280,25,3,1,0.33,68.402973,1,"100%_Bran","N","C",70,4,1,130,10,5,6,280,25,3,1,0.33,68.402973
"Q","C",120,3,5,15,2,8,8,135,0,3,1,1,33.983679,0,"100%_Natural_Bran","Q","C",120,3,5,15,2,8,8,135,0,3,1,1,33.983679
"K","C",70,4,1,260,9,7,5,320,25,3,1,0.33,59.425505,1,"All-Bran","K","C",70,4,1,260,9,7,5,320,25,3,1,0.33,59.425505
"K","C",50,4,0,140,14,8,0,330,25,3,1,0.5,93.704912,1,"All-Bran_with_Extra_Fiber","K","C",50,4,0,140,14,8,0,330,25,3,1,0.5,93.704912
"R","C",110,2,2,200,1,14,8,-1,25,3,1,0.75,34.384843,4,"Almond_Delight","R","C",110,2,2,200,1,14,8,-1,25,3,1,0.75,34.384843
"G","C",110,2,2,180,1.5,10.5,10,70,25,1,1,0.75,29.509541,4,"Apple_Cinnamon_Cheerios","G","C",110,2,2,180,1.5,10.5,10,70,25,1,1,0.75,29.509541
"K","C",110,2,0,125,1,11,14,30,25,2,1,1,33.174094,4,"Apple_Jacks","K","C",110,2,0,125,1,11,14,30,25,2,1,1,33.174094
"G","C",130,3,2,210,2,18,8,100,25,3,1.33,0.75,37.038562,4,"Basic_4","G","C",130,3,2,210,2,18,8,100,25,3,1.33,0.75,37.038562
"R","C",90,2,1,200,4,15,6,125,25,1,1,0.67,49.120253,4,"Bran_Chex","R","C",90,2,1,200,4,15,6,125,25,1,1,0.67,49.120253
"P","C",90,3,0,210,5,13,5,190,25,3,1,0.67,53.313813,1,"Bran_Flakes","P","C",90,3,0,210,5,13,5,190,25,3,1,0.67,53.313813
"Q","C",120,1,2,220,0,12,12,35,25,2,1,0.75,18.042851,4,"Cap'n'Crunch","Q","C",120,1,2,220,0,12,12,35,25,2,1,0.75,18.042851
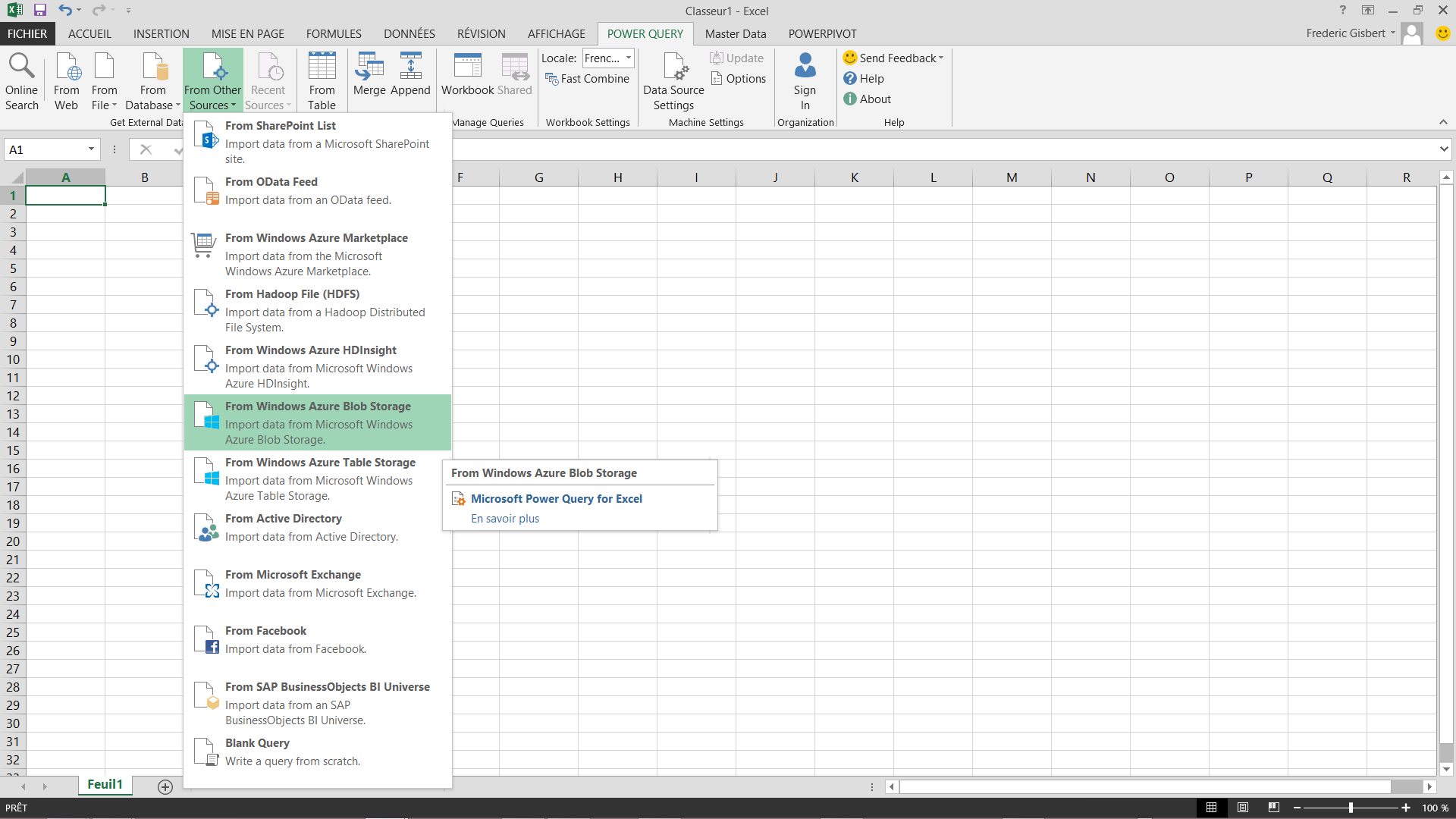
L'intégration avec la BI en libre service Microsoft
Nous utilisons maintenant Microsoft PowerQuery pour consommer directement le résultat depuis le blob storage azure.
On ajoute maintenant le résultat de la requête au modèle Microsoft PowerPivot. Nous avons alors chargé les produits de céréales avec leur classification.
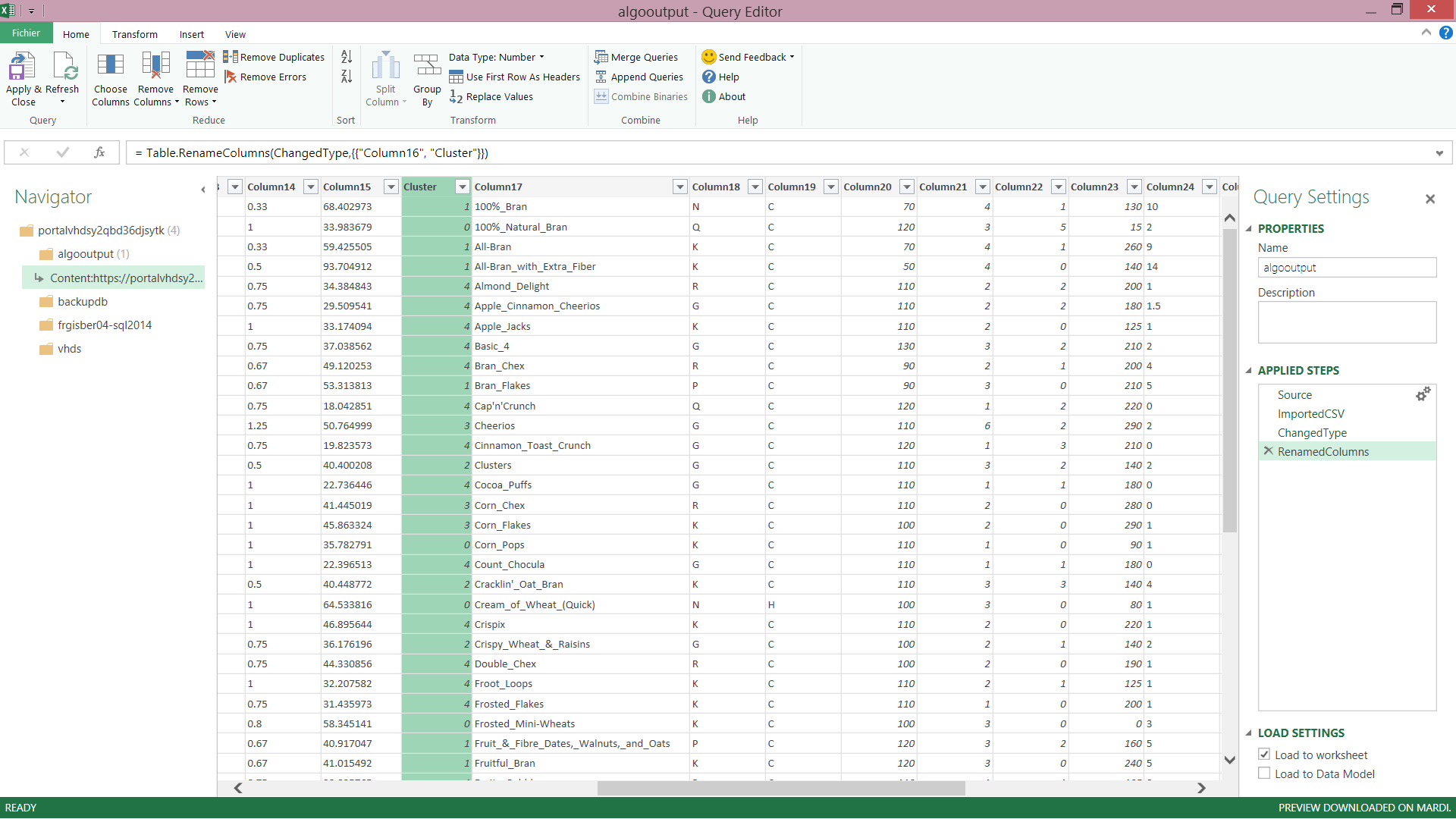
Il n'y a plus qu'à consommer ce modèle dans PowerView directement avec Excel 2013 et laisser place à l'analyse
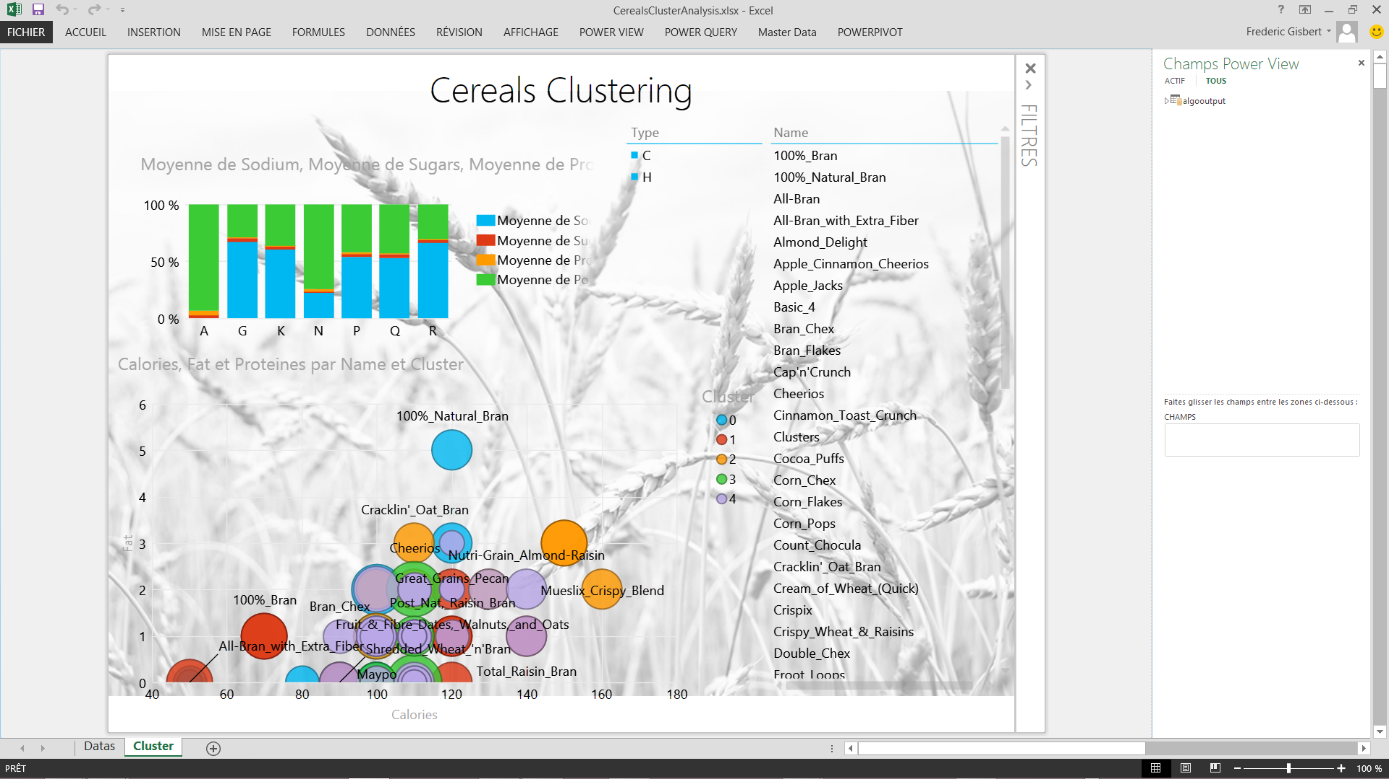
Vous pouvez alors filtrer sur les différents clusters, ici de 0 à 4, et voir se représenter les articles positionnés dans ceux-ci. Bien sûr vous aurez ainsi accès à toutes les mesures définies dans votre dataset caractérisant chacun des produits.
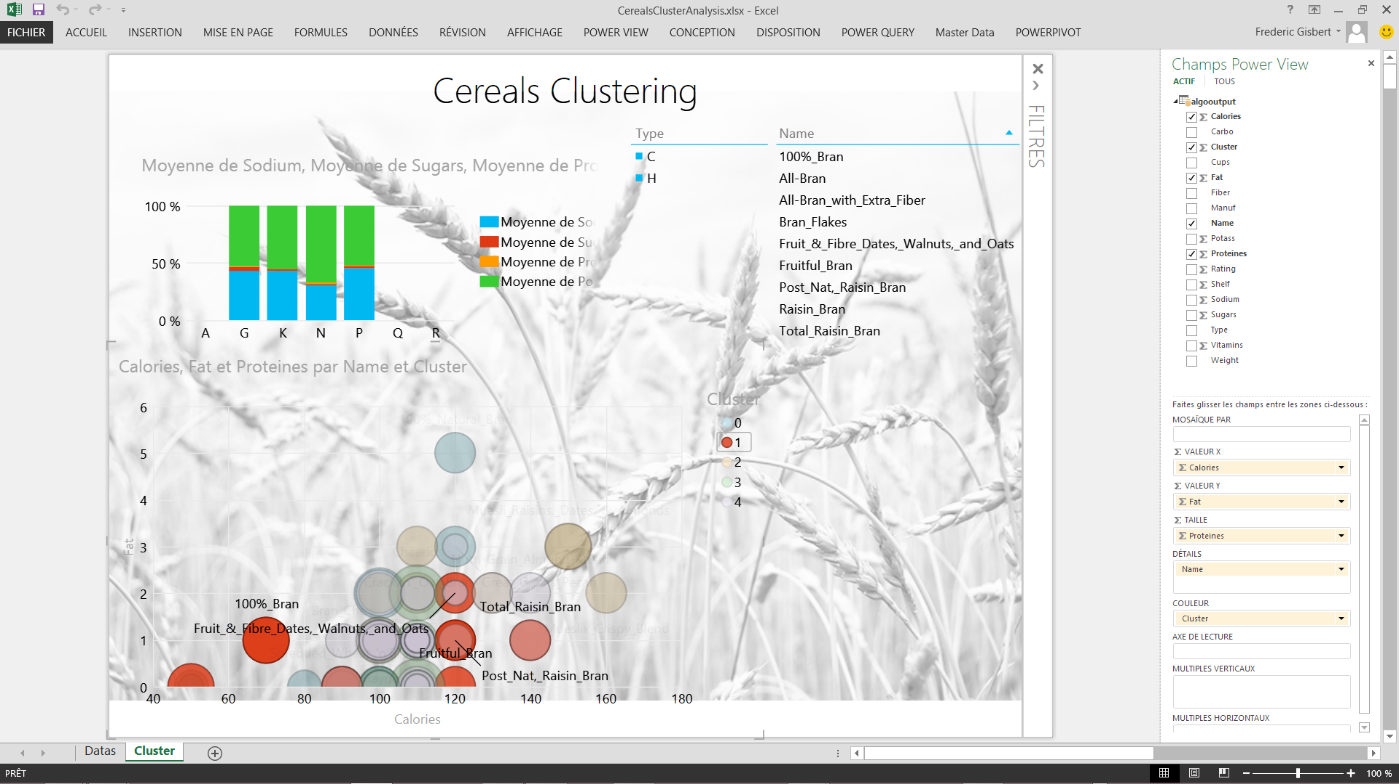
Ceci est un avant-gout de l'apport d'une solution Microsoft Azure Machine Learning couplée à de la self-service BI.
Pour plus d'informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d'informations sur les blogs « SQL Server chez les clients ».
 | Frédéric Gisbert, Architecte BI/SQL/Big Data Microsoft Consulting Services J'interviens en clientèle sur des problématique BI, Big Data et plus globalement de gestion de données (MDM, CEP, SharePoint) en tant que lead technique et architecte. Le but premier d'un architecte solution est d'intégrer la suite SQL Server dans des environnements hétérogènes en considérant toutes les spécificités de chacun de nos clients. J'interviens aussi dans des problématiques Big Data sur nos solutions Hortonworks (Hadoop). Certification : Analysis Services MAESTRO |
SQL Server chez les clients – Simplifiez vos stratégies de Backup et Disaster Recovery avec SQL 2014

La mise en oeuvre de solutions métiers dans les entreprises requiert un alignement avec les défis posés par le monde de affaires actuel : une disponibilité et une accessibilité maximale, des pics de montée en charge, une croissance des volumes de données...
La version 2014 de SQL Server expose une gamme de fonctionnalités de Cloud Hybride permettant de répondre à ces défis, notamment à travers des solutions de haute disponibilité flexibles et de protection de données basées sur Windows Azure.
Problématique
- Exploiter les bénéfices du Cloud computing afin de répondre aux enjeux des applications métiers en entreprise
- Gérer les problèmatiques liées au stockage des sauvegardes des bases de données
Bénéfices
- Des solutions de Cloud Hybride, qui s'adaptent aux besoins de flexibilité et de disponibilité des entreprises
- Une gestion des sauvegardes de bases de données facilitée, à travers Windows Azure Storage
SQL Server AlwaysOn et le Cloud Hybride
AlwaysOn, solution 2 en 1, combinant à la fois haute disponibilité et Disaster Recovery, disponible à partir de SQL Server 2012 a fait l'objet de plusieurs articles de la série "SQL Server chez les clients" :
SQL Server 2014 combiné à Windows Server 2012 R2 met à disposition 3 solutions de Haute Disponibilité et Disaster Recovery :
- Failover Cluster Instances
- AlwaysOn Availability Groups
- Replicas Hyper-V
En outre, certaines combinaisons de ces solutions sont possibles dans certains scénarios pour garantir une meilleure haute disponibilité et davantage d'optimisations des coûts. Sans doute en raison de la flexibilité inhérente à cette solution, les groupes de haute disponibilité d'AlwaysOn sont envisagés pour un large éventail de scenarii et d'implémentations.
Par ailleurs, avec les possibilités récemment ajoutées « d'extension des Replicas AlwaysOn sur Azure IaaS (Infrastructure As A Service) », la possibilité d'utiliser les ressources de Windows Azure pour répondre aux besoins de croissance des clients SQL Server présente un avantage majeur.
Il est possible d'envisager des scénarii d'intégration hybride IT cloud / onpremise. Cela implique la création d'un tunnel VPN entre le cloud et les réseaux privés.
Il existe 2 typologies de scenarii hybrides
- Créer un réplica "On Premise" pour étendre un Availability Group déjà présent sous Windows Azure
Cela peut s'avérer être un scénario de HADR particulièrement rentable, plus particulièrement pour des organisations considérant Azure IaaS comme leur site principal tout en disposant d'un réplica secondaire On Premise, qui pourra prendre le rôle de serveur primaire en cas de panne.
Pour les environnements de business intelligence lourds, incluant des Data Warehouses volumineux, cela peut être une option attrayante pour diminuer les coûts et augmenter la performance avec la sécurité et le confort garantis par l'utilisation de Windows Azure.
- Créer un réplica dans Windows Azure pour étendre un Availability Group déjà présent "On Premise".
Ce scénario plus fréquemment rencontré, permet une transition vers Windows Azure. Tout en conservant un environnement On Premise, il est possible de bénéficier d'un ou plusieurs réplicas On Premise dans Azure IaaS. Cela permet de compléter une infrastructure existante de façon rentable et fiable.
Chacune de ces configurations peut être mise en œuvre en créant un tunnel VPN de site à site entre les réseaux on premise et le réseau virtuel Windows Azure.
Une autre méthode possible pour créer une passerelle entre les serveurs Azure et Onpremise est le nouveau tunnel VPN « point-to-site », qui consiste à installer une application cliente sur chaque poste susceptible de se connecter au réseau virtuel Windows Azure.
Les prérequis de mise en oeuvre
Les prérequis suivants doivent être respectés afin de pouvoir implémenter une architecture hybride de haute disponibilité et de Disaster Recovery.
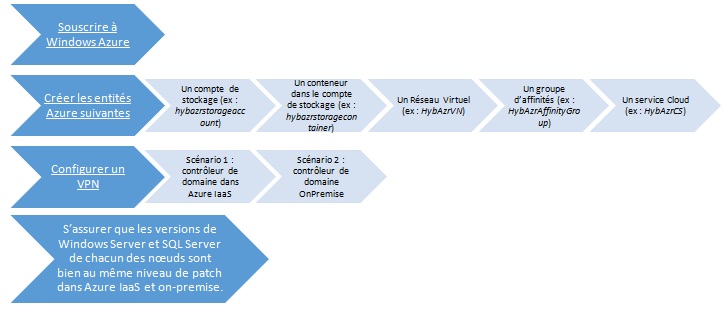
Pour aller plus loin:
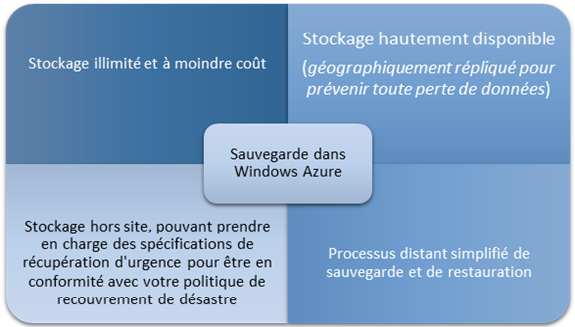
L'enjeu du stockage croissant des données
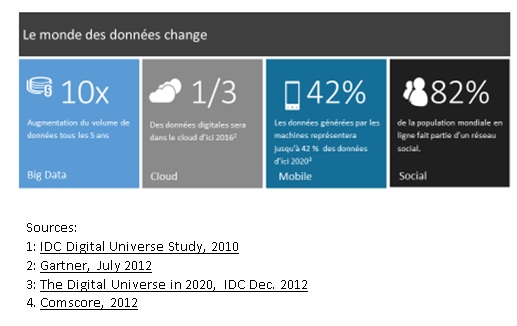
L'avantage du stockage dans le Cloud
Dans le monde actuel où les données ne cessent d'évoluer, aussi bien en termes de quantité croissante que de typologie, il est nécessaire de proposer une plateforme présentant davantage de flexibilité et d'adaptabilité.
L'évolution de SQL 2014 proposant des possibilités de scénarios hybrides et de backups dans le Cloud va dans ce sens.
Les principaux avantages de backup dans Windows Azure sont présentés ci-dessous:
Les sauvegardes SQL Server gérées dans Windows Azure
SQL Server Managed Backup dans Windows Azure permet de gérer et automatiser les sauvegardes des bases SQL Server dans le service de stockage Windows Azure Blob Storage. Ce mécanisme de sauvegarde s'appuie sur des paramètres de durée de conservation des données et d'activité des bases afin de définir la configuration la plus adaptée.
Cette fonctionnalité prend en charge les opérations de restauration "point of time" en fonction de la durée de rétention définie, et peut être utilisée dans des environnements "On Premise", mais également dans des machines virtuelles Windows Azure.
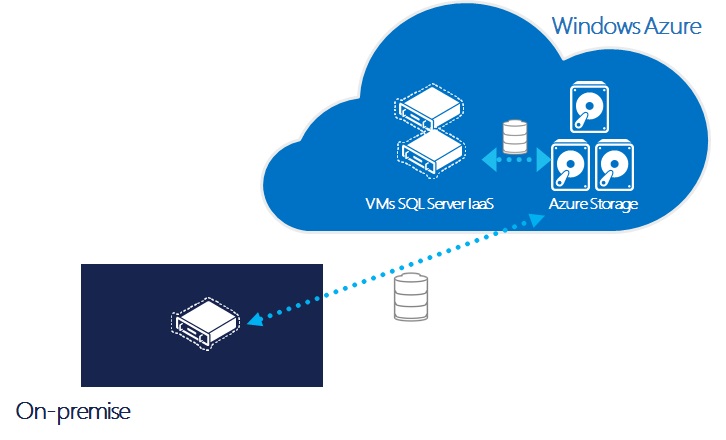
Il est possible d'activer la gestion des sauvegardes SQL Server dans Windows Azure, soit au niveau d'une base en particulier, soit au niveau de l'instance pour gérer la sauvegarde de l'ensemble des bases.
Les sauvegardes peuvent être effectuées dans Azure Storage soit depuis une VM hébergée dans Windows Azure, soit depuis un serveur On Premise, comme le montre le schéma ci-dessous:
L'outil SQL Server Backup to Windows Azure Tools , permettant un processus distant simplifié de sauvegarde et de restauration, vous permet de gérer:
- Vos sauvegardes dans Windows Azure Blob Storage
- L'encryption des données
- La compression des backups SQL stockés en local ou dans le Cloud
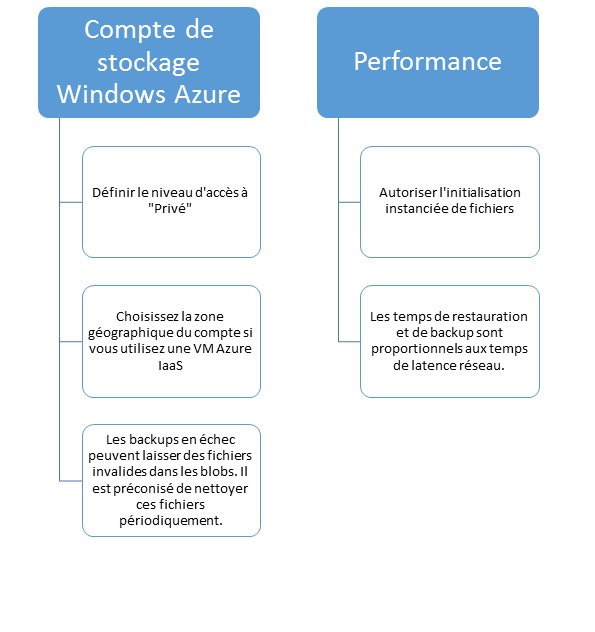
Vous trouverez ci-dessous quelques points clés à retenir lors de l'implémentation de vos backups dans le Cloud:
 Plus d'informations sur les sauvegardes SQL Server dans Windows Azure Blob Storage.
Plus d'informations sur les sauvegardes SQL Server dans Windows Azure Blob Storage.
L'expertise Microsoft Consulting Services au service de ses clients
Les consultants et architectes de l'équipe MCS SQL/BI sont formés pour mettre en œuvre des projets engageant SQL Server 2014 et WIndows Azure
MCS travaille déjà étroitement sur plusieurs projets avec des clients dans les domaines de la Banque, Assurance ou Telecom.
Pour plus d'informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d'informations sur les blogs « SQL Server chez les clients ».
 | Sophie Bismuth, Consultante BI/SQL &Dynamics CRM, Microsoft Consulting Services J'interviens dans le cadre de projets décisionnels s'articulant autour de la stack BI de Microsoft ou d'une brique Dynamics CRM. J'aborde également les thématiques d'architecture, de Disaster Recovery et d'optimisations de performance. |
SQL Server chez les clients – SQL as a Service

Introduction
SQL as a Service (SQLaaS) propose d'utiliser une base de données SQL Server sans avoir toute la charge de gestion et de maintien en conditions opérationnelles de la plateforme.
L'architecture SQLaaS repose sur un catalogue de services, établi à partir des besoins et contraintes spécifiques de chaque entreprise. Ce catalogue recense l'ensemble des services proposés et fonctions incluses (en tant que services intégrés).
SQLaaS permet à une équipe réduite, dédiée, d'assurer la mise à disposition du service dans un délai court, en proposant des bases de données standardisées. Cette équipe est en mesure de maintenir la plateforme dans un état de service opérationnel avec une surveillance 24h/24h. Ce modèle permet de réduire à la fois les coûts et les délais de mise en œuvre.
Catalogue de services
Le catalogue de services type peut proposer les services suivants :
- Provision d'une base de données
- Modification d'une base de données
- Suppression d'une base de données
- Provision d'une instance
- Modification d'une instance
- Suppression d'une instance
Et inclut les fonctions suivantes :
- Des tableaux de bord pour surveiller la base de données
- Un tableau de bord pour la facturation du service
- Une garantie de ressources CPU et d'espace et de ressources disque (avec SQL Server 2014)
- Une surveillance du service
- Une continuité en cas de défaillance unique d'un des éléments de la plateforme
- Une gestion de l'application des correctifs.
Des exemple d'un service de provision de base de données :
Service | Environnement | Dimensions techniques | Services intégrés |
Provision d'une base | Production | Performance : Garantie d'un minimum CPU (3 niveaux de performance) Stockage : Espace de stockage maximum (3 niveau de stockage) Version : Choix entre version SQL supportées Collation : Choix entre les collations supportées Service de PRA sur site de secours | Sauvegarde quotidienne Continuité de service en cas de défaillance simple (un serveur ou une baie de disques ou un site) RPO = 0, RTO < 5 minutes Tableaux de bord permettant de suivre l'usage de la base de données Tableaux de bord permettant la refacturation du service Surveillance de la plateforme Mise à jour de la plateforme suivant un calendrier préétabli |
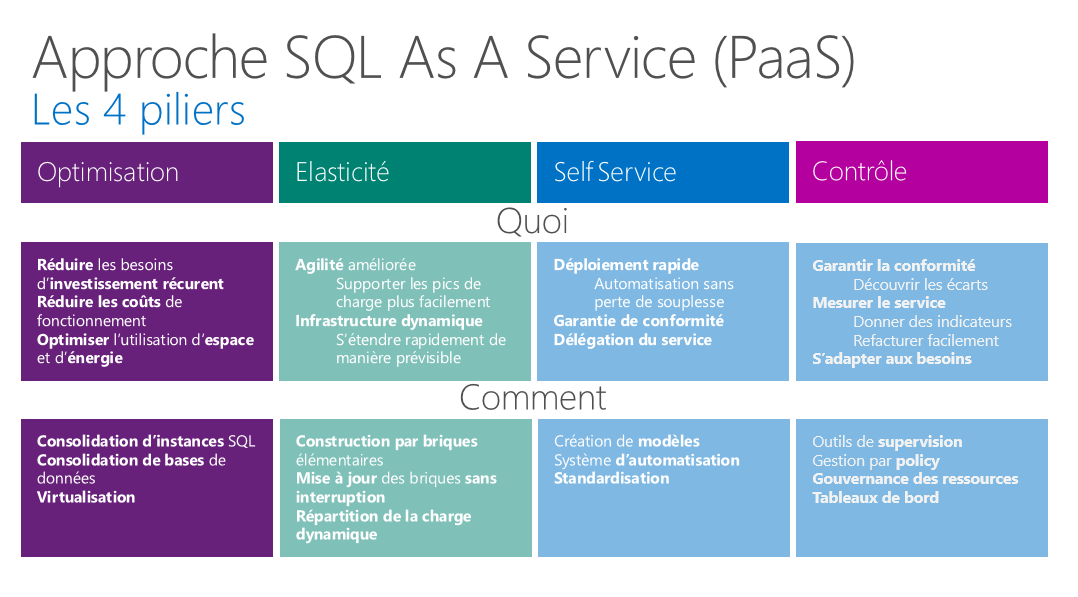
Les 4 piliers
SQLaaS consiste à construire un « cloud privé » de type PaaS reposant sur 4 piliers :
Optimisation
Il s'agit de réduire les coûts de fonctionnement de la plateforme SQL en mutualisant les ressources. La mise en œuvre de SQLaaS n'implique pas obligatoirement de virtualiser l'infrastructure ni de disposer d'un IaaS. De façon générale, SQLaaS est agnostique vis-à-vis de l'infrastructure.
L'idée directrice de l'optimisation est de pouvoir opérer plus de bases SQL Server avec moins de ressources matérielles et humaines afin de réduire les coûts. La réduction des ressources matérielles peut s'appuyer sur des techniques classiques de consolidation d'instances ou base de données et/ou de la virtualisation, les deux approches pouvant être combinées en fonction du contexte.
Elasticité
Ce pilier recouvre 2 notions :
L'agilité , qui est la capacité à changer la répartition des instances ou des machines virtuelles entre les différents hôtes de la plateforme avec une interruption minimale. Cela permet de réaliser des opérations de maintenance sur le matériel, le système d'exploitation ou les instances avec une interruption de service minimale voire nulle.
Sa mise en en œuvre s'appuie sur l'utilisation (éventuellement combinée) de :
- Hyper-V Live Migration pour déplacer une machine virtuelle d'un hôte à l'autre sans interruption
- System Center Operation Manager associé à System Center Virtual Machine Manager pour déclencher automatiquement le déplacement d'une machine virtuelle entre deux hôtes (par exemple en cas de pic de charge sur l'un des hôtes)
- SQL Server Failover Cluster Instance pour déplacer une instance entre 2 machines (par exemple pour appliquer un correctif sur une instance avec une interruption de service minimale).
Une infrastructure dynamique, qui peut évoluer au fur et à mesure que les besoins augmentent. L'idée est de commencer « petit » afin de réduire l'investissement initial au minimum et de faire croître l'infrastructure par unités d'extension afin de répondre aux nouveaux besoins en termes de ressources.
Self-Service
Il s'agit de pouvoir déléguer un service à un tiers.
L'objectif est de minimiser le temps de mise à disposition du service en s'appuyant sur des briques d'automatisation.
Une telle approche permet, par exemple, de déléguer la création d'une base de données aux études sans passer par l'équipe DBA.
Ce fort degré d'automatisation permet de standardiser les installations d'instance et de bases de données et garantit la conformité avec les normes de l'entreprise. L'ensemble du processus de Self-Service s'articule autour d'une interface utilisateur matérialisée en général par un portail web, d'une brique d'orchestration telle que System Center Orchestrator et une brique d'automatisation constituée d'un ensemble de scripts Power Shell.
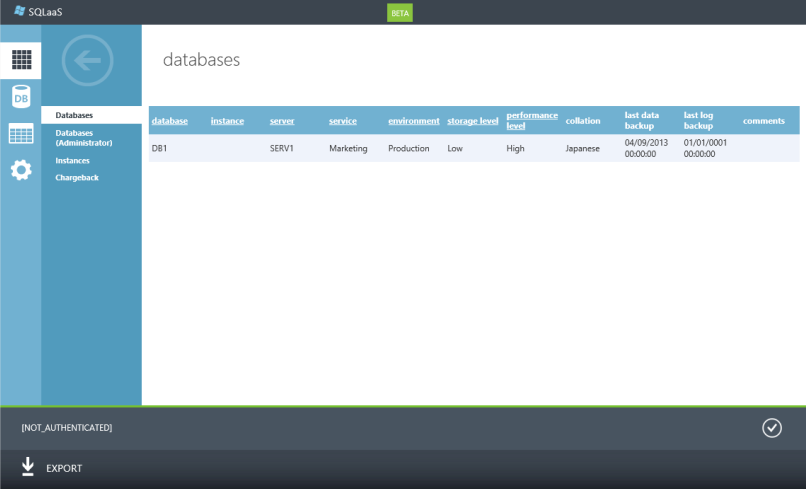
Le portail
Contrôle
Il s'agit de garantir la conformité des instances et bases provisionnées et le cas échéant à découvrir les écarts. La mesure du service est également essentielle pour pouvoir s'adapter au besoin. Des indicateurs permettent également de refacturer un service au client. System Center Operation Manager associé aux fonctionnalités de Policy Based Management de SQL Server permet d'implémenter le contrôle de la plateforme SQLaaS.
Plusieurs approches sont envisageables pour refacturer un service :
- Une approche a posteriori qui consiste à mesurer dynamiquement les ressources consommées (CPU, IO, Disque) par une instance ou une base de données et à refacturer le client en conséquence.
- Une approche a priori qui consiste à contraindre les ressources disponible pour chaque client ou application en fonction des propriétés choisie pour le service par exemple l'espace disque, le nombre IOPS garantis ou le %CPU garanti. La garantie de ressource peut être adressée nativement par Hyper-V, Windows Server Resource Manager ou SQL Server Resource Gouvernor selon qu'il s'agisse des ressources d'une instance ou d'une base de données.
Disponibilité immédiate et puissance infinie
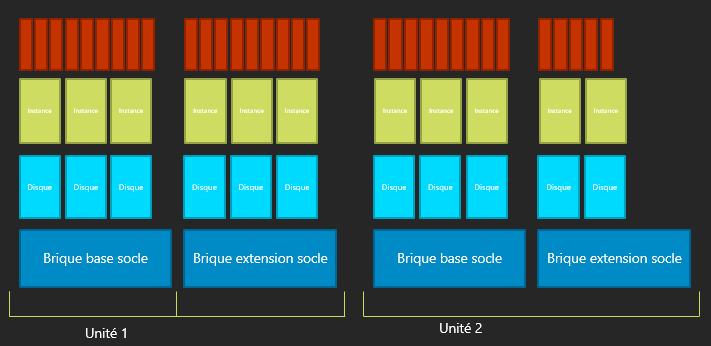
Unité d'extension
L'architecture SQLaaS se veut modulaire et peut s'étendre en fonction des besoins.
Le principe d'architecture dynamique consiste à provisionner en avance et de façon asynchrone les différentes ressources en prérequis du provisionnement d'une instance ou d'une base de données qui, elles, sont provisionnées de manière synchrone. L'utilisation d'unités d'extension permet d'effectuer la mise à l'échelle nécessaire à l'accueil de nouvelle instances ou de bases de données supplémentaire lorsque les unités existantes ont atteint un certain seuil (de CPU, d'IO ou d'espace disque).
Conclusion
Si vous souhaitez :
- Rationnaliser votre plateforme SQL Server
- Améliorer la souplesse
- Déployer à la demande
- Standardiser, mesurer et refacturer à vos métiers
Alors, l'approche SQL as a Service mérite votre attention.
L'approche SQLaaS a été mise en œuvre et est à l'étude chez nos clients :
- Grandes banques françaises
- Organisme de prévoyance
- Industrie automobile
Microsoft Services propose une offre de services vous permettant de définir votre plateforme SQL as a Service.
Pour plus d'informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d'informations sur les blogs « SQL Server chez les clients ».
 | Sébastien Grosbois, Consultant BI/SQL, Microsoft Consulting Services Après quelques années passées dans un cabinet de conseil spécialisé en bases de données, j'ai rejoint Microsoft Services en 2001. Je suis actuellement Consultant Senior SQL Server & BI. |
SQL Server chez les clients – Un référentiel de données fiable et maitrisé avec MDS et DQS
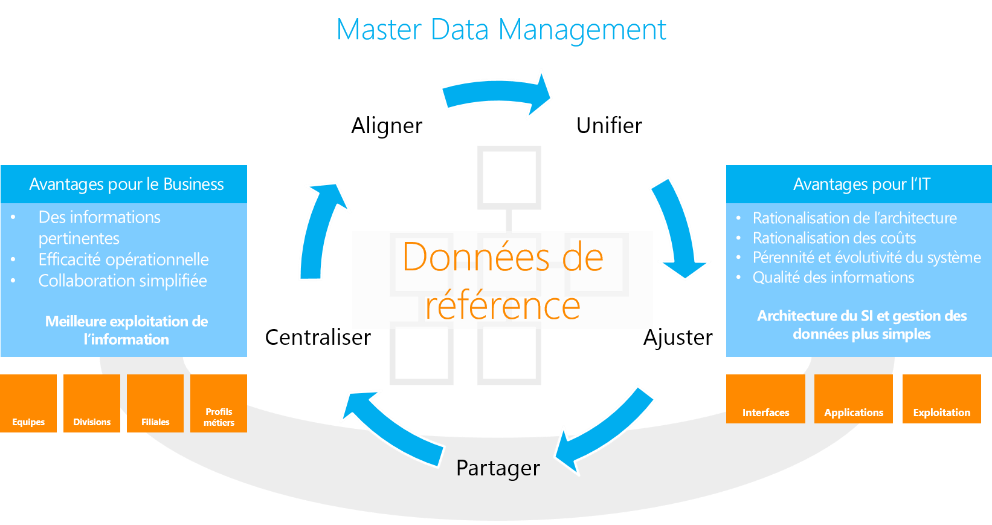
La gestion des données de référence, ou Master Data Management (MDM) est une discipline permettant aux organisations de travailler sur un socle consolidé et fiable pour les informations référentes. SQL Server Master Data Services (MDS) est une plateforme de gestion des données de référence, qui peut être combinée avec Data Quality Services (DQS) , pour la gestion de la qualité de donnée.
Cet article est le troisième d'une série consacrée à l'EIM, et fait suite aux articles « Solution EIM pour Dynamics CRM » et « Une gestion flexible de la qualité des données avec DQS et SSIS ».
Dans ce billet, nous allons montrer comment injecter de la qualité dans un référentiel de donnée grâce à l'utilisation combinée des outils MDS et DQS.
Problématique
Avec l'explosion de la production des donnée et les besoins croissants d'analyse qui en découlent, les entreprises sont de plus en plus souvent confrontées aux problématiques suivantes :
- Garantir la cohérence des données au travers de l'ensemble du SI
- Permettre le croisement des données entre les différents Systèmesafin de répondre aux besoinsde Reporting
- Assurer une gestion de la qualité des données
- Définir des processus de gouvernance des données qui soit à la fois simples et efficaces
Bénéfices
- Centralisation : La rationalisation entraine une simplification et une baisse des coûts de gestion
- Unification : Les référentiels uniques permettent aux systèmes de consommer des références consolidées
- Alignement : Le rapprochement rend possible le croisement des données entre les systèmes
- Ajustement : Les données corrigées, formatées et enrichies répondent aux besoins métiers
- Partage : L'ensemble des Systèmes y accèdent de manière autonome et sécurisée
Master Data Services
Master Data Services, est spécifiquement conçu pour gérer les données de référence. Ses fonctionnalités principales sont reprises dans le schéma ci-dessous:
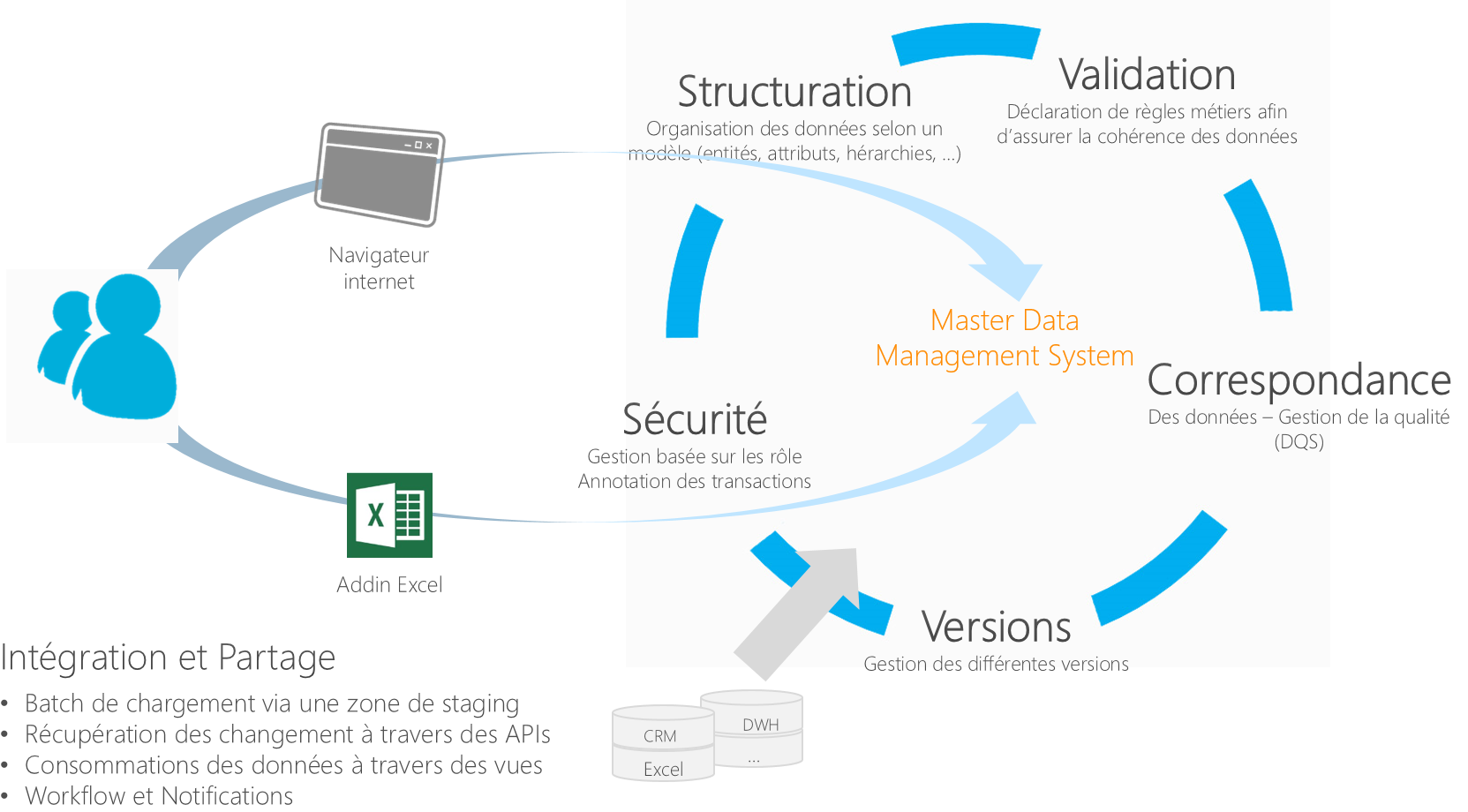
Correspondance et Gestion de la qualité :
Nous allons nous pencher sur cette brique de Master Data Services et voir en détail comment l'interfacer avec DQS pour répondre aux problématiques de gestion de la qualité dans un référentiel de donnée.
Cette interface entre les deux produits va être réalisée par le biais de SSIS (SQL Server Integration Services), afin de s'appuyer sur l'ensemble des briques EIM intégrés dans SQL Server (MDS/DQS/SSIS).
Intégrer des données de qualité dans un référentiel MDS via SSIS
MDS et DQS s'interfacent par le bais de SSIS pour construire une solution d'alimentation automatisée, avec contrôle de qualité dans un référentiel MDS.
La première étape consiste à créer un package SSIS, qui va assurer l'automatisation du nettoyage et de la correspondance des données lors de l'alimentation du référentiel.
Pour ce faire nous allons créer un projet SSIS, puis y ajouter une étape de type « DataFlow » dans lequel les opérations d'extraction, de nettoyage et de chargement vont être effectuées.
Dans notre exemple nous allons ajouter une source de données de type Excel au DataFlow, puis faire pointer cette source de donnée vers le fichier de donnée fournisseur (Nous aurions pu choisir parmi les nombreuses sources de données disponible dans SSIS).
Nous allons également ajouter une transformation de type DQS Cleansing. Cette transformation permet de confronter des données aux règles d'une base de connaissances DQS (A configurer en amont).
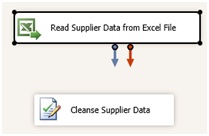
Configurer la tâche DQS pour qu'elle pointe vers votre instance DQS et utilise la base de connaissances souhaitée (Suppliers dans notre cas).

Dans l'onglet "Mapping", il suffit de sélectionner les colonnes du flux que nous souhaitons analyser et de les mapper avec les domaines correspondants de la base de connaissances DQS.

Il faut ensuite séparer les lignes saines (correctes ou corrigées) des lignes en anomalie, car nous ne chargerons uniquement les lignes saines dans le référentiel (les lignes en anomalie peuvent être également redirigées pour un traitement spécifique).
Pour ce faire nous pouvons utiliser une transformation de type "Conditional Split".
Le Conditional Split permet de router les lignes vers des sorties distinctes en fonction de conditions définies.
La condition que nous allons mettre en œuvre va tester le contenu de la colonne [RecordStatus] pour chacune des lignes.
La colonne [RecordStatus] étant directement enrichie par la tâche DQS, elle retourne le statut de la ligne suite à la confrontation de celle-ci aux règles de la base de connaissance.
Il suffit ensuite de regrouper ces lignes dans un même flux, grâce à une transformation de type Union All.
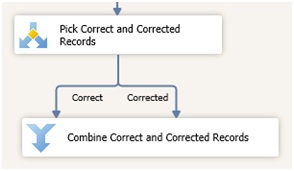
Nous devons également enrichir les lignes avec des informations nécessaires au chargement dans MDS.
Pour ce faire nous utiliserons une transformation de type DerivedColumn.
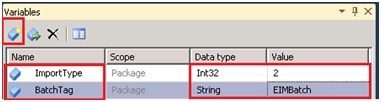
MDS requiert deux informations pour le chargement par batch, ImportType et BatchTag :
- ImportType correspond au type d'import à réaliser
- BatchTag correspond au nom que nous souhaitons donner au chargement, (On retrouvera cette information par la suite dans l'interface Master Data Manager).
Le tableau ci-dessous récapitule les différentes valeurs pour ImportType :

Pour réaliser l'opération, nous allons définir ces deux valeurs comme variable de package pour ensuite les utiliser dans la transformation DerivedColumn.
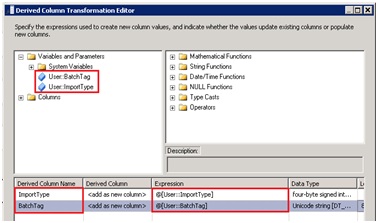
Utilisation des deux variables dans la transformation DerivedColumn :
Il ne nous reste plus qu'à écrire les lignes dans les tables de Staging d'MDS.
Nous allons donc utiliser un composant destination de type OLE DB, le faire pointer vers l'instance MDS et sélectionner la table de Staging à alimenter.
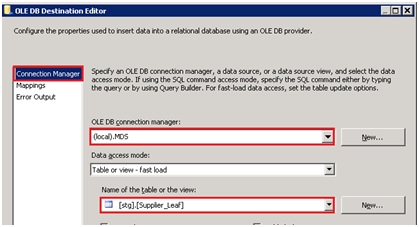
Configurer le mapping pour faire coïncider les données en entrée avec les données en destination :
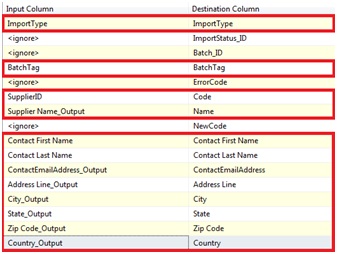
Voici donc la structure finale du DataFlow :
- Extraction des données à partir d'un fichier Excel
- Confrontation des données aux règles de la base de connaissance DQS
- Dissociation des lignes saines (Correctes + Corrigées) des lignes en anomalie
- Regroupement des lignes dans un flux de données unique
- Enrichissement des lignes avec les informations requises par MDS en vue de leur intégration
- Alimentation en base de Staging MDS
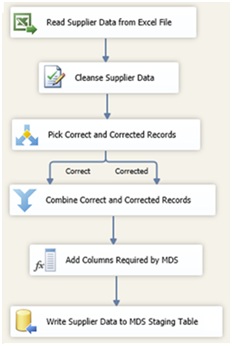
Une fois chargée en zone de Staging, nous pouvons automatiser l'alimentation effective du référentiel.
Ce déclenchement peut être effectué par le biais d'une procédure stockée dont nous allons lancer l'exécution grâce à une simple tâche de type SQL Task.
Code SQL de lancement de la procédure :
USE [MDS_DB]
GO
EXEC[stg].[udp_Supplier_Leaf] @VersionName=N'VERSION_1',@LogFlag= 1,@BatchTag=N'EIMBatch'
GO
Cette procédure stockée, tout comme la table de staging, est crée lors de l'instanciation de l'entité dans MDS.
Nous pouvons à présent vérifier au sein de l'interface Master Data Services que l'intégration s'est déroulée correctement.
Dans l'interface Web "Master Data Manager", sous l'onglet Import Data, nous avons une vue sur les différents chargements ayant été effectué. On y retrouve entre autre le BatchTag que nous avons renseigné dans le package SSIS ainsi que l'entité ciblé (Supplier) et le nombre de ligne chargées.
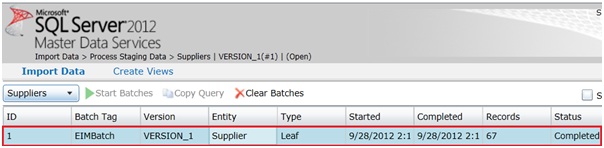
Les données nettoyées sont désormais chargées au sein de l'entité Supplier dans le référentiel de données.
Conclusion
Dans ce billet, nous avons vu comment il était possible d'alimenter un référentiel de données MDS de manière automatisée par le biais de SSIS tout en maitrisant la qualité de ses données à l'aide de DQS.
Ceci est un exemple typique de solution d'Enterprise Information Management (EIM) implémentée avec la plateforme Microsoft SQL Server.
L'expertise Microsoft Consulting Services au service de ses clients
MCS propose une offre de service packagée pour implémenter des solutions de Master Data Management sur des plateformes SQL Server & MSBI.
Cette méthodologie de mise en œuvre de solutions de Master Data Management a été éprouvée à travers des réalisations chez des clients grands comptes dont voici quelques exemples :
- Grandes Sociétés d'Assurance Françaises
- Grandes Banques Françaises
- Gestionnaire de flotte de véhicules
Elle peut aussi bien être mise en œuvre dans le cadre d'un projet géré par Microsoft Services, que dans le cadre d'une assistance technique sur certains aspects du projet (architecture, validation…).
Pour plus d'informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d'informations sur les blogs « SQL Server chez les clients ».
 | Jordan Doullé, Consultant Data Insights, Microsoft Consulting Services Spécialiste des problématiques EIM d'Intégration de donnée, de Gestion de Master Data, et de Qualité de donnée, j'interviens sur l'ensemble des phases des projets décisionnels de nos clients. |
SQL Server chez les clients – Une démarche décisionnelle maîtrisée et sécurisée
La qualité de mise en œuvre d'une solution décisionnelle est bien souvent critique pour une entreprise, qui a besoin de pouvoir analyser son activité, comprendre son marché, et prendre des décisions pour améliorer sa compétitivité.
De la maîtrise des concepts décisionnels à leur implémentation, en passant par le choix de la solution la plus adaptée au contexte et aux besoins métiers sont autant de facteurs qui permettront d'assurer la qualité de cette solution.
L'objectif de cet article est d'illustrer une démarche de mise en œuvre d'une solution décisionnelle à travers une expérience d'accompagnement de bout en bout de l'équipe SQL/BI Microsoft Consulting Services auprès d'un client grand compte dans les secteurs de la gestion de patrimoine et la banque privée.
Problématique
- Maîtriser les concepts décisionnels théoriques et techniques.
- Concevoir une architecture disposant d'une capacité de montée en charge adaptée.
- Activer les fonctionnalités et services Microsoft BI en fonction des besoins.
- Former les équipes (métiers, IT) aux outils Microsoft BI en cohérence avec le contexte métier.
Bénéfices
- Une solution décisionnelle Microsoft BI en phase avec les besoins et enjeux métiers de l'entreprise.
- Une architecture pérenne permettant de répondre aux besoins actuels et futurs.
- L'intégration des équipes métiers dans le choix des outils : un gage d'adhésion et de réussite du projet.
- Des utilisateurs opérationnels sur les outils Microsoft BI et les données décisionnelles de l'entreprise.
C'est à travers différentes activités et ateliers que ces problématiques sont abordées, afin de nous assurer que le projet décisionnel suit la bonne direction. Ces ateliers nous amènent des éléments qui nous permettent de prendre les bonnes décisions et conduire à la réussite du projet…
Avant tout, un projet...
Accompagner les clients dans toutes les phases de mise en œuvre de leur application décisionnelle est avant tout un projet dont les activités principales sont mises en avant dans la section « problématiques » ci-dessus qu'il convient d'adresser.

Grandes étapes d'un projet décisionnel
Chacune de ces grandes étapes inclut plusieurs activités (qui, pour certaines, peuvent être réalisées de manière itérative). Voici, à titre d'exemple, la liste des activités de l'étape « Mise en œuvre de la solution Microsoft BI » :
- Analyse des spécifications fonctionnelles
- Analyse (ou Réalisation) des spécifications techniques
- Modélisation relationnelle (Staging, ODS, Datawarehouse, Datamart…)
- Développement des flux d'alimentation (ETL)
- Développement des cubes d'analyse
- Développements des rapports et tableaux de bord
- Tests unitaire et tests d'intégration
- Validation fonctionnelle
- Déploiement
Un tel projet est jalonné de nombreux livrables qui correspondent à ce qui est produit avant, pendant et à l'issue (après adaptations) des activités présentées dans les sections qui suivent.
La maîtrise des concepts BI et la modélisation décisionnelle
Phase essentielle d'un projet de Business Intelligence, la modélisation décisionnelle apporte la matière qui permettra aux utilisateurs de la solution de réaliser les analyses métiers souhaitées de manière autonome, et de gagner dans le temps du processus de prise de décision.
Voici les étapes suivies durant cet atelier majeur :
- Objectifs du décisionnel
- Étapes de mise en œuvre d'un projet décisionnel
- Approches de modélisation décisionnelle
- Processus et schématisations de modélisation
- Implémentation dans Microsoft BI
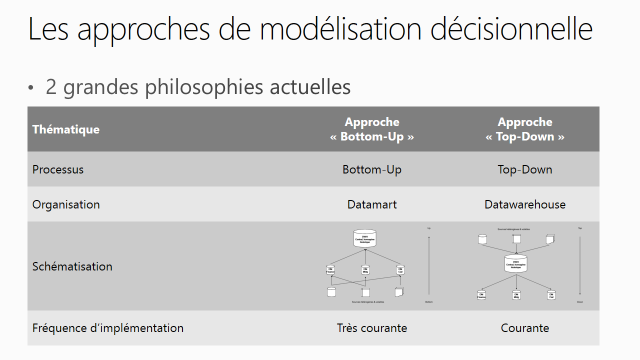
Approches de modélisation décisionnelle
L'intérêt est ici de s'assurer que les concepts décisionnels sont maitrisés, tout comme les principes d'implémentation dans les solutions Microsoft BI, et particulièrement auprès des populations qui utiliseront les outils de modélisation et d'intégration des données, tout comme ceux qui réaliseront les couches de présentation à destination des utilisateurs finaux (à savoir les « consommateurs du système BI »).
La connaissance des outils de la suite décisionnelle Microsoft Business Intelligence
La première étape, avant même d'aborder les outils Microsoft BI, consiste à recenser les besoins décisionnels des utilisateurs au sein de l'entreprise. De ce recensement nait une matrice des usages (ou « types de consommation » du système décisionnel) qui sert de fil conducteur et évolue tout au long du projet.
Toutes les organisations n'ont pas la même maturité, ni le même niveau de connaissances, de ce qu'il est possible de faire aujourd'hui en matière d'usages BI sur un système décisionnel.
L'approche consiste à présenter les « nouveaux usages » décisionnels et de les confronter à la matrice des usages BI de l'entreprise. Cette dernière peut naturellement évoluer et s'enrichir.
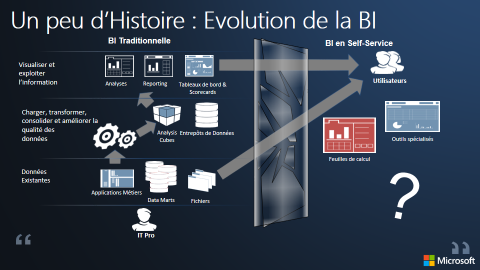
Évolution du décisionnel : les nouveaux usages
Les outils Microsoft BI ne se cantonnent pas aux seuls outils dits de « restitution » (tels qu'Excel, Excel Services, Power View, PerformancePoint…), d'autres utilisateurs (par exemple les « analystes », les utilisateurs « techniques », les « concepteurs », les « opérateurs »…) n'ont pas été oubliés et trouvent leur place dans le paysage des outils Microsoft BI.
C'est le cas des « concepteurs » du système décisionnel (développeurs sur les couches d'intégration de données, de présentation des données ou des rapports de restitution) qui utilisent (respectivement) les briques applicatives SSIS,SSAS et SSRS.
Tout comme les besoins en termes de gestion des données de référence de l'entreprise et la maîtrise de sa qualité (Master Data Management,Data Quality Management…) qui y trouvent naturellement leur place.
C'est pourquoi l'on parle de « plateforme » décisionnelle capable de couvrir l'exhaustivité des besoins décisionnels.
La présentation de la plateforme décisionnelle Microsoft BI permet de faire la transition depuis la « matrice des usages » vers la gamme des outils Microsoft BI.
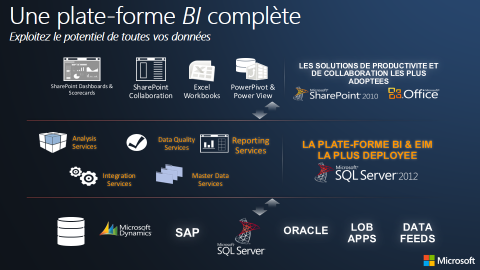
Plateforme décisionnelle de la suite Microsoft Business Intelligence
Conception d'une architecture décisionnelle Microsoft Business Intelligence, dans les règles de l'art
La connaissance de la matrice des usages décisionnels et de leur déclinaison dans les outils Microsoft BI, associée aux enjeux d'analyse des données métiers, permettent d'envisager l'architecture du système décisionnel cible.
Concevoir l'architecture décisionnelle Microsoft Business Intelligence demande systématiquement de se projeter vers une architecture évolutive, et tenant compte des accroissements de volumes de données mais également des usages.
Il convient donc de mesurer ces volumes de données et de se projeter dans leurs évolutions afin que l'architecture soit toujours en phase avec ces évolutions.
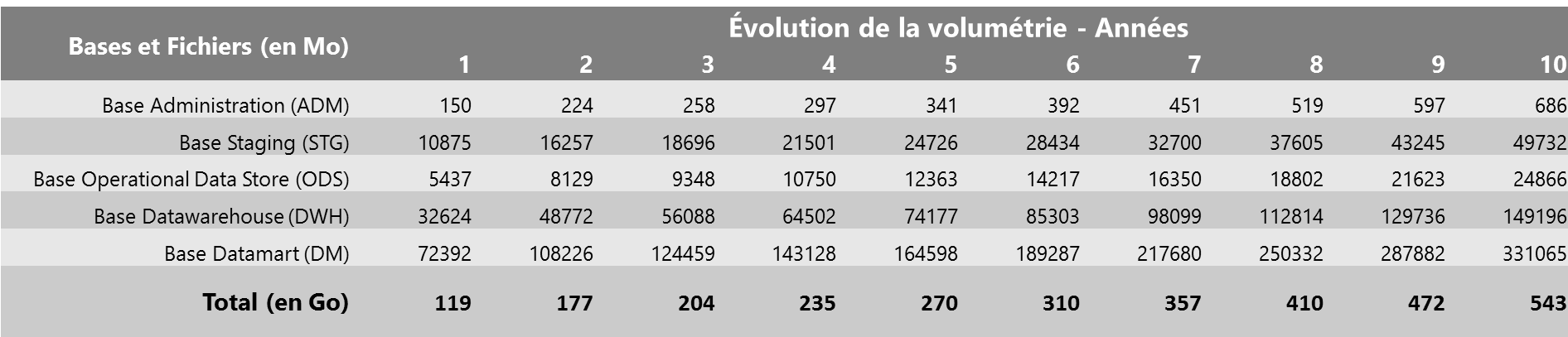
Exemple de tableau de calcul d'évolution de la volumétrie
La modularité de l'architecture des solutions Microsoft BI permet de s'adapter avec une grande réactivité face aux besoins d'évolution (telle l'augmentation des volumes de données ou l'accroissement du nombre de consommateurs du système BI).
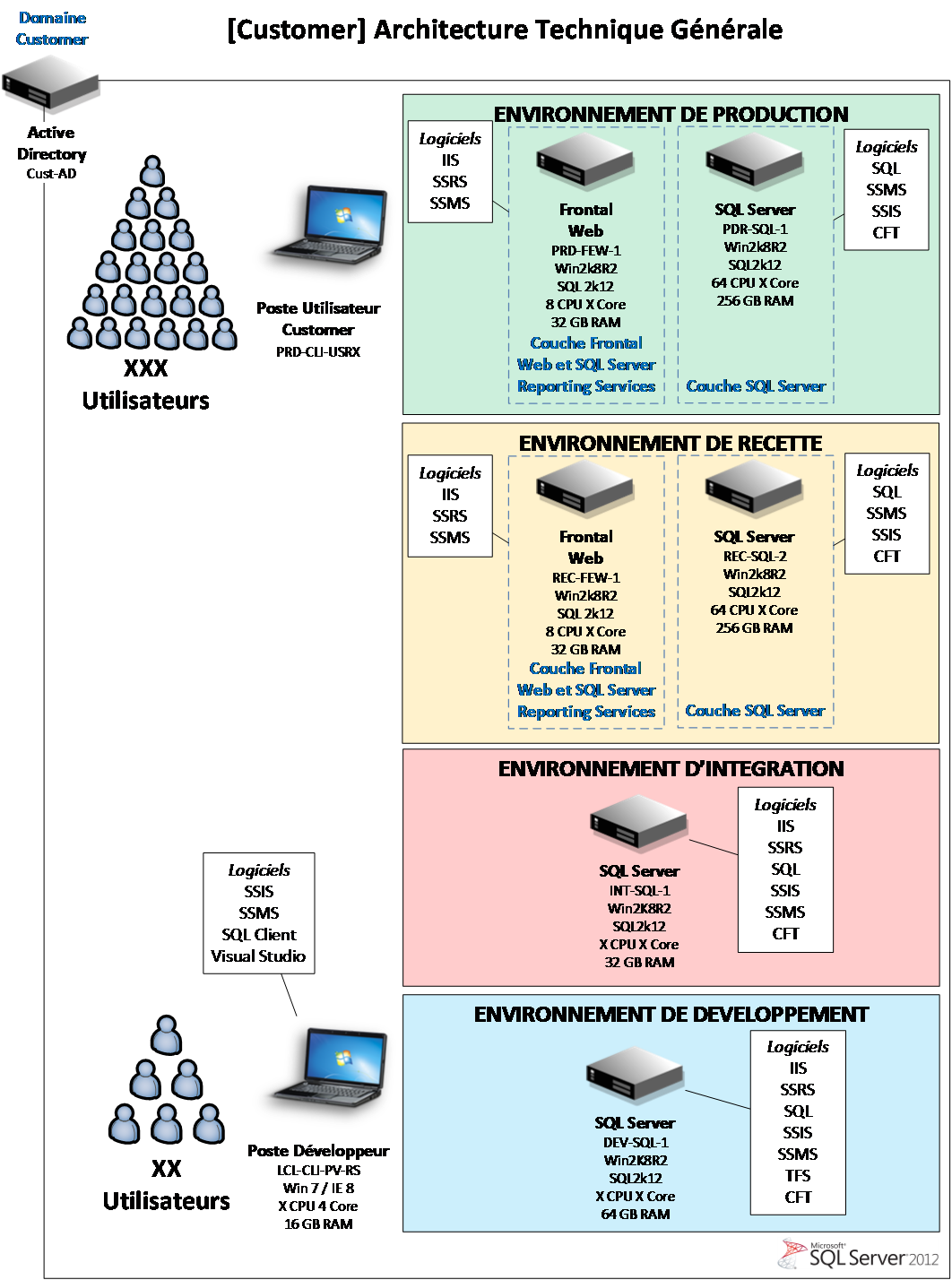
Exemple d'architecture générale des environnements Microsoft BI
L'implémentation d'une architecture décisionnelle Microsoft BI « dans les règles de l'art », passe par un atelier qui présente les bonnes pratiques en matière de mise en œuvre des solutions Microsoft SQL Server et des briques décisionnelles associées (SSIS, SSAS, SSRS, SharePoint BI…).
L'adhésion des utilisateurs, gage de réussite du projet décisionnel
L'un des facteurs clés de réussite d'un projet décisionnel est de s'assurer que les utilisateurs participent au processus de décision du choix des outils. Outils qu'ils seront amenés à utiliser au quotidien pour aider à piloter les activités de l'entreprise.
Quoi de mieux que de pouvoir manipuler les outils présélectionnés et de les confronter aux données métiers ?
De ces ateliers de formation ressortent les outils préférés de certains utilisateurs, et l'expérience montre que les différents services d'une entreprise n'adhèrent pas forcement aux mêmes outils.
L'expérience passée des utilisateurs (bien souvent aguerris sur des outils tels Excel par exemple), et celle acquise durant ces sessions de formation permettent d'affiner la sélection des outils MIcrosoft BI à mettre en oeuvre dans la solution décisionnelle.

Exemple de matrice des usages projetés sur les outils Microsoft BI
Exemple de programme suivi durant les formations (cible utilisateurs « consommateurs ») :
- Schéma général de la base décisionnelle
- Les outils Microsoft BI
- Excel (basique)
- Excel (avancé)
- PowerPivot
- Power Query
- Power Map
- Power View
- Reporting services
- Report Builder
- Report ManagerSharePoint BI
- SharePoint BI
- Excel Services
- PerformancePoint
D'autres formations, et accompagnements dans la montée en compétences sur les outils de conception (SSIS, SSAS, SSRS…) sont également délivrés selon les besoins.
L'expertise et le conseil de Microsoft Consulting Services au service de ses clients
L'équipe MCS SQL BI vous accompagne dans toutes les phases de vos projets décisionnels en s'assurant que les technologies Microsoft BI sont utilisées de manière optimale, et en cohérence avec vos besoins métiers, tout en formant vos utilisateurs aux outils.
Ces formations intègrent systématiquement la dimension « contextuelle » des données client.
Cette démarche d'accompagnement nous permet d'atteindre, avec succès, l'ensemble des jalons permettant la réussite des projets BI.
Voici quelques exemples :
- Filiale d'un groupe de services financiers, spécialisée dans la gestion de patrimoine et dans la banque privée
- Groupe multinational français dans la gestion de l'environnement
- Grand groupe bancaire français
- Grand groupe mondial dans le domaine de l'énergie (producteur d'énergie)
Ce type d'accompagnement peut être mis en œuvre dans le cadre d'un projet géré intégralement par Microsoft Consulting Services, tout comme dans le cadre d'une assistance sur certaines phases du projet (choix d'outils, architecture, formation…).
Voici d'autres sujets d'accompagnement associés:
L'équipe MCS SQL BI fait également profiter ses clients de sa grande proximité avec les équipes Premier (support) ainsi qu'avec le groupe Produit.
Pour plus d'informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d'informations sur les blogs « SQL Server chez les clients ».
 | Bruno Bornil, Consultant BI/SQL, Microsoft Consulting Services Au cœur des problématiques BI depuis l'année 2001, j'accompagne aujourd'hui nos clients dans la mise en œuvre de leurs projets décisionnels implémentés avec les solutions Microsoft Business Intelligence (MS BI). Qu'il s'agisse de clients effectuant leur premier projet décisionnel ou ceux désirant transformer leurs investissements BI actuels vers les solutions et technologies MS BI, j'ai la chance de les accompagner sur l'ensemble des phases de leurs projets BI. |
SQL Server chez les clients – Une gestion flexible de la qualité des données avec DQS et SSIS
Lorsque nous parlons de qualité de données avec les outils SQL Server, en général, les clients choisissent entre des règles techniques implémentées via SSIS pour un traitement automatique ou des règles fonctionnelles implémentées via DQS (DataQuality Services) pour une gestion accessible aux utilisateurs.
La solution DQS satisfait les clients par son accessibilité et le fait d'avoir la main sur les corrections, mais ne permet pas encore l'implémentation de tous les types de corrections.
La solution SSIS permet de mettre en place tous types de corrections mais ne donne pas la main aux utilisateurs, notamment pour la validation ou le rejet des corrections.
Cet article est le second d'une série consacrée à l'EIM, et fait suite à l'article « Solution EIM pour Dynamics CRM ».Il explique comment sur un projet en production chez un de nos clients grand compte, nous avons pu combiner les deux solutions.
Problématique
- Mettre en place toutes sortes de règles de gestion de la qualité des données
- Avoir la possibilité de valider, rejeter ou modifier des corrections proposées
Bénéfices
- Une gestion de la qualité des données flexible et accessible aux utilisateurs
Schéma des étapes de correction des données
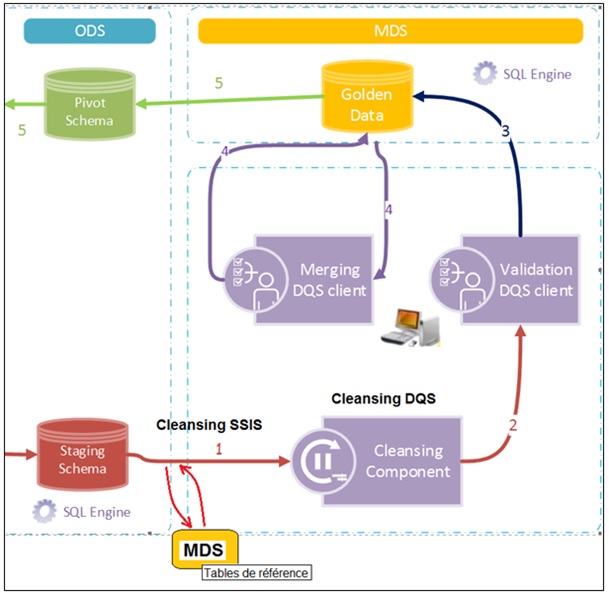
Gestion de la qualité des données avec SSIS
Il est impératif d'ajouter des commentaires au package, décrivant ses différentes étapes ainsi que la logique de leur enchaînement afin de permettre plus facilement à d'autres intervenants la compréhension de ce qui a été mis en place et la reprise de l'existant.
DQS permet d'évaluer la qualité des données et de faire certaines corrections mais ne permet pas les corrections telles que la suppression des espaces avant et après la donnée ou la comparaison de deux données contenues dans deux colonnes.
SSIS permet ce type de corrections mais ne permet pas à l'utilisateur d'avoir la main dessus afin de les valider, les corriger ou les rejeter.
La solution mise en place a donc été de combiner DQS et SSIS afin répondre aux deux exigences.
Dans la base de staging, une colonne a été ajoutée pour chaque attribut à corriger. Cette colonne contiendra la correction proposée par SSIS s'il y en a une.
Les règles mises en place sont les suivantes :
- Suppression de caractères,tels que caractères spéciaux et chiffres, se trouvant dans MDS et pouvant donc aisément être enrichie par les utilisateurs.
FirstName | ProposedFirstName |
Mathias_3 | Mathias |
- Suppressions d'espaces avant et après la donnée.
FirstName | ProposedFirstName |
Mathias | Mathias |
- Suppression de l'email2 s'il est égal à l'email 1.
Email1 | Email2 | ProposedEmail2 |
manon@microsoft.com | manon@microsoft.com | Null |
- Correction du format du numéro de téléphone en fonction du pays
Si Pays =FR et
0y xx xxxxxxavec y!=0 ou 00 33 y xx xxxxxxavec y!=0 ou +33 y xx xxxxxxavec y!=0
Alors (+33)yxxxxxxxxx
Gestion de la qualité de données avec DQS
Les règles de correction mises en place dans DQS sont les suivantes :
- Mettre en majuscule les noms
LastName | ProposedLastName |
Berne | BERNE |
- Mettre en Capitalize les prénoms
FirstName | ProposedFirstName |
Jean-marie | Jean-Marie |
Processus de validation des correction
DQS permet d'effectuer des corrections mais aussi d'avoir la possibilité de valider, modifier ou rejeter les corrections proposées, notamment par SSIS.
SSIS ne remplissant les colonnes Proposed que si une proposition de correction est faite, il a suffi de mettre en place une règle dans DQS stipulant que les champs Proposedne sont corrects que s'ils sont NULL.
De cette manière, dans le processus de classification des données par DQS, décrit par le schéma ci-dessous :
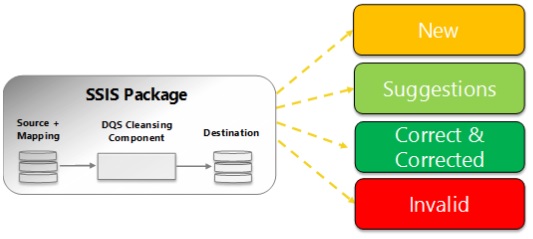
Les données pour lesquelles une correction a été proposée par SSIS apparaissent dans la catégorie « Invalid », ceux corrigés par DQS apparaissent dans la catégorie « Corrected » et ceux pour lesquels une suggestion de correction a été faite par DQS dans la catégorie « Suggested ».
Les utilisateurs peuvent donc vérifier les corrections proposées, les valider, corriger la proposition ou simplement rejeter la correction.
Les utilisateurs enregistrent le résultat et SSIS interprète les champs « Reason » et « Status » de DQS afin de savoir quelles corrections prendre en compte.
De cette façon, les clients peuvent avoir toutes les possibilités de correction des données offertes par SSIS ainsi que la main sur leur validation via DQS.
L'expertise Microsoft Consulting Services au service de ses clients
Nos expériences nous permettent d'adapter les principes de l'EIM pour répondre aux contraintes des secteurs d'activité comme la banque d'investissement et l'assurance.
Pour plus d'informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d'informations sur les blogs « SQL Server chez les clients ».
 | Manon B., Consultante BI/SQL, Microsoft Consulting Services Je suis consultante BI depuis 2007, principalement sur les technologies Microsoft BI. J'interviens chez des clients, en tant que leader technique. Je participe également à des missions de cadrage et d'avant-vente. Je suis spécialisée en intégration des données, gestion de la qualité des données et reporting. |
SQL Server dans les Virtual Machines Services de Windows Azure : toutes les ressources techniques
Le 16 avril était annoncée la disponibilité de Windows Azure Infrastructure Services , marquant le début d'une infrastructure entièrement pris en charge en tant que service dans Windows Azure, avec SQL Server comme composante majeure.
Les machines virtuelles SQL Server préinstallées sont disponibles pour un usage en paiement à l'heure dans la galerie Windows Azure. Actuellement les éditions Enterprise, Standard et Web de machines virtuelles fonctionnant sur ??Windows Server 2008 R2 SP1 sont disponibles, avec plus d'éditions SQL Server à venir. Les éditions de SQL Server fonctionnant sur des images de Windows Server 2012 sont également en préparation. Pour plus de détails sur les scénarios et les avantages de la gestion des workloads SQL Server sur Windows Azure Virtual Machines, visitez le blog de l'équipe SQL Server USA ici.
Nous sommes heureux d'annoncer que la documentation technique mise à jour pour le déploiement et l'exécution de SQL Server dans Windows Azure Infrastructures Services est maintenant disponible en ligne. Lors du déploiement de SQL Server sur Windows Azure Virtual Machines, nous vous recommandons de suivre les indications détaillées figurant dans le nouveau guide SQL Server dans Windows Azure Virtual Machines de la bibliothèque MSDN.
Cette documentation comprend une série d'articles et tutoriels qui fournissent des conseils détaillés sur:
Bonne lecture !

SQL Server + Visual Studio = recette gagnante pour un projet BI de qualité
Cette semaine au menu de l'émission Bon App ! de Visual Studio, Agilité & BI avec Benoit Launay, chef de produit Microsoft Visual Studio, et Jean-Pierre Riehl, responsable Data & Business Intelligence chez notre partenaire AZEO.
Qu'est-ce qu'un projet BI ? Quels sont les challenges rencontrés ? Comment industrialiser ce type de projet avec SQL Server, Visual Studio et Team Foundation Server ? Regardez pour en savoir plus !
...Et si on rajoutait du Big Data avec Windows Azure HDInsight ?
Téléchargez le Livre blanc HDInsight / Visual Studio / MSDN de DCube et Microsoft.
Ce livre blanc présente un usage concret de SQL Server associé à HDInsight au travers d'un cas client. Le cas étudié repose sur un système réalisé pour GlobeCast (société de gestion et livraison de contenus multimédias) par notre partenaire DCube, dans le cadre d'une solution de distribution de contenus cinématographiques dans des salles de cinéma.
Alternatif bir mobil cihaz erişimi
EAS (Exchange ActiveSync) mobil cihazlardan mailboxlara istenildigi zaman ve istenildigi yerden ulasilmasina imkan veren bir iletisim protokolüdür.
Bu protokol cihazlarda direct push teknolojisini kullanir ve mailbox ile cihaz arasinda sync islemini yapar. Direct Push (over-the-air) encrypted HTTPs baglantisi kurar böylece sunucu ve mobil cihaz arasinda email ve diger verileri sync eder. Daha ayrintili bilgi için buraya gözatabilirsiniz.
Microsoft-Server-ActiveSync virtual directory'si Client Access sunucu rolünde kurulmus Web Server (IIS) rolüyle görülebilir. Bu klasörün içerisinde bulunan XML/XSD semasiyla handshake islemi gerçeklesecektir. Ilgili fonksiyon dosyalari C:\Program Files\Microsoft\Exchange Server\V14\ClientAccess\sync\Xsd\v14.1
altindan görülebilir.
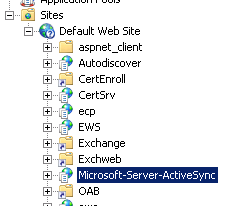
Exchange 2007 ve Exchange 2010 versiyonlarinda Activesync protokolü varsayilan olarak etkin halde gelir. Bu ayar sistem yöneticileri tarafindan kaldirilabilir.
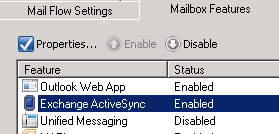
Kullanicilar mobil cihazlarindan EAS disinda EWS (Exchange Web Services) kullanarak ta mailboxlarina erisilebilirler. Client Access sunucu rolü ile EWS etkinlesmektedir. EWS ile EAS 'in çalisma yöntemleri birbirinden farklidir. EWS XML tabanli bir protokoldür ve SOAP standartlarinda hazirlanmis veri paketleriyle HTTPs protokolü araciligiyla islem yapar. Daha ayrintili bilgi için buraya bakabilirsiniz.
Nasil ki EAS devre disi birakilabiliyorsa EWS kullanimi da Exchange 2010 da devre disi birakilabilir. Ancak bu Exchange 2007 de mümkün degildir. Devre disi birakmak için asagidaki komut kullanilabilir.

Bu nedenle EWS kullanarak sync yapan cihazlara sistem yöneticileri dikkat etmelidirler. Bazi mobil cihazlar ve yine bazi uygulamalar kullanilarak EAS etkisiz hale gelse bile, eposta alip atmaya devam eder.
Uygulamanin EAS in etkisiz hale gelmesi durumunda EWS kullanarak epostalari indirmeyi basarir. EWS kullanirken de indirmeyi MSRPC kullanarak yaptigini
görebiliriz.
Bu uygulama Outlook Anywhere kullanarak EWS ile MSRPC gönderir ve verileri çeker. Bunun için EAS in etkisiz hale geldigini düsünmek yeterli degildir.
Örnek bir IIS logu:
1269 2011-06-01 06:47:09 172.10.10.10 POST /Microsoft-Server-ActiveSync/default.eas User=domain%5Ctest-user1&Cmd=FolderSync&DeviceId=615352495048485148515548545350&DeviceType=xxx&Log=Error:UserHasBeenDisabled_ 443 domain\test-user1 212.212.212.10 yyy (MSRPC)/6.5.0002 403 0 0 0
000547 2011-06-10 00:00:23 172.20.20.20 POST /ews/exchange.asmx SoapAction=GetEvents ;Version=0;RpcC=0;RpcL=0;LdapC=3;LdapL=0; 443 domain\test-user1 2.212.212.72 MSRPC 200 0 0 234
Bunu engellemek için ISA/TMG sunucuda /ews/* in publish edildigi kural üzerinde HTTP filtering yapilarak uygulamanin imzasini engelleyebiliriz.
ISA/TMG üzerinde /ews/* publish edilen kural üzerinde sag tiklayarak "Configure HTTP" seçip "Signatures" alaninda "Response Body" "GetItem" seklinde filtreleme yaptigimizda ilgili uygulamanin eposta alip verme isleminin durmasi saglanir.
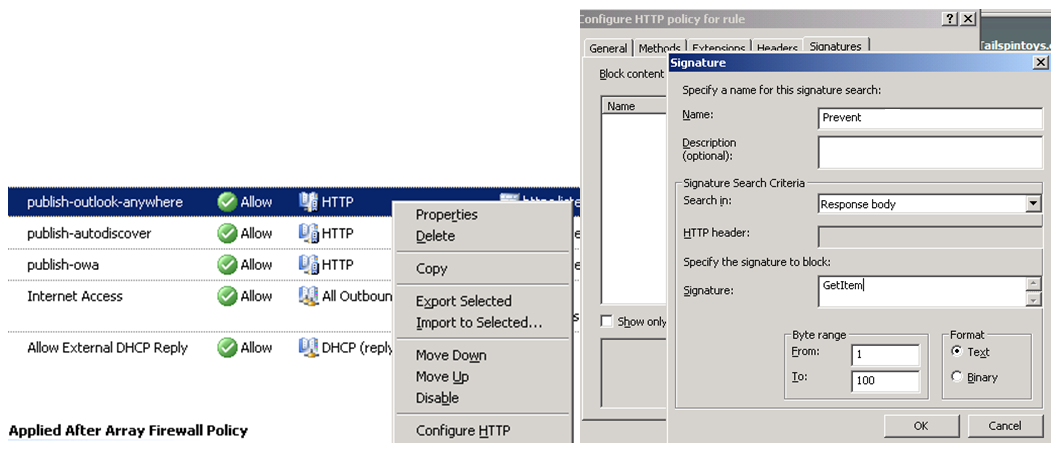
ISA Server 2004 Filtering ile ilgili buradan daha ayrintili bilgiye ulasabilirsiniz.
C. Sinem Tosun
Direct Booking'e karşı Auto Accept Agent
Exchange Resource Mailbox kavrami ile özdeslesen Room Mailbox'lar sirketlerde oldukça yogun kullanilan ve is akisinda önemli roller üstlenen bir özelliktir. Geçtigimiz haftalarda room mailbox'larla epey bir hasir nesir oldugum için bu konuda kisa bir makale yazmak istedim. Direct booking nedir? Auto accept agent'dan farki nedir? Hangisini kullanmak daha avantajlidir? Her ortamda kullanilabilir mi? gibi sorulara cevap bulabileceginizi umdugum bir yazi olacak. Bir Outlook teknolojisi olan direct booking, resource mailbox'in direk olarak rezerve edilmesine dayanir. Organizatörün kullandigi Outlook bu noktada yapilan tüm islemlerden sorumludur; toplanti saatlerindeki çakismadan tutun ilgili istegin resorce mailbox'in takvimine islenmesine kadar. Bu teknoloji artik Outlook tarafinda vazgeçilmeye çalisilan bir teknoloji ve Outlook 2010'da registry'de bir degisiklik yapmadiginiz sürece desteklenmemektedir.
Direct booking için gerçeklestirilmesi gereken adimlar:
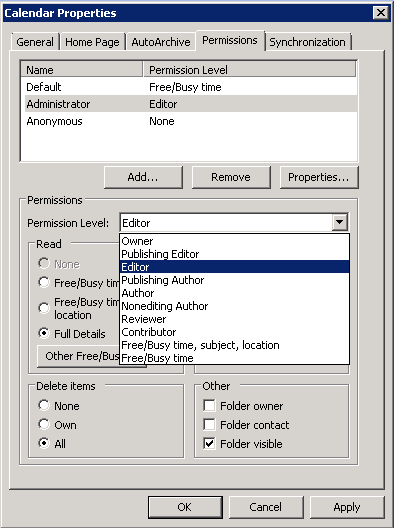
- Organizatörün resource mailbox üzerinde en az Editor hakkinin olmasi gerekmektedir.
- Resource mailbox'in gelen toplanti isteklerine otomatik olarak kabul veya çakisma durumunda red olarak dönmesi için ilgili resource mailbox'i Outlook'da açin ve File>>Options>>Calendar>>Resource Scheduling altinda yer alan iki checkbox'i isaretleyin.
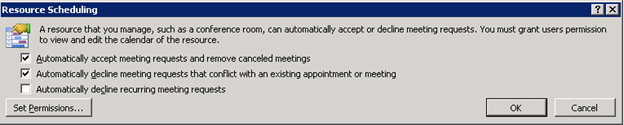
- Organizatörün resource mailbox'i ilgili toplanti isteginde"Resources" alaninda belitmesi gerekir, "Required" veya "Optional" bunun için yeterli gelmeyecektir.

- Outlook 2010 kullaniyorsaniz ve direct booking ile çalismak istiyorsaniz registry'de asagidaki makalede belirtilen registry degisikligi yapilmali:
Direct Booking does not successfully book a resource in Outlook 2010
Exchange 2003 SP1'den bu yana kullanabileceginiz Auto Accept Agent ise Direct Booking'in yerine geçmis durumda. Bu agent resource mailbox'in free/busy bilgisini degil bizzat calendar schedule durumunu kontrol ederek toplanti isteklerini kabul eder veya reddeder. Böylece free/busy bilgisinin güncellenmesinde yasanan bir gecikmede
Auto Accept Agent durumdan etkilenmeyecektir. Ayrica islemlerin server-side yapilmasi önemli bir avantaj sunar.
Exchange 2007 ve 2010'da ise daha mailbox olusturulurken "Room Mailbox" seçimini yaparak diger mailbox'lardan farkli attribute'lara sahip farkli türde bir mailbox olusturmus oluyoruz. Böyle bir mailbox'a ait user, interactive logon'a engel olmak için disable edilir ve user account password'ü otomatik olarak Exchange tarafindan belirlenir. Set-CalendarProcessing ve Set-MalboxCalendarSettings (Exchange 2007'de) komutlari resource mailbox ayarlarini yapmak için kullanabilecegimiz bazi komutlardir. Örnegin direct booking'de oldugu gibi toplanti isteklerinin otomatik cevabi için asagidaki gibi auto accept agent'in enable edilmesi gerekir:
Set-CalendarProcessing "Room Mailbox" -AutomateProcessing AutoAccept

Exchange 2010'da resource mailbox ve Set-CalendarProcessing komutu ayrintili ele alinmasi gereken bir konu oldugu için daha fazla detaya inmeyecegim. Ancak merak edenler için asagidaki technet sayfasini incelemelerini öneririm.
https://technet.microsoft.com/en-us/library/dd335046.aspx
Sevgi Sifyan
Distribution Group 'a atılan mailer için otomatik yanıt nasıl alınır?
Distribution Group özelliklerinde böyle bir ayar yer almadigi için farkli yöntemlerle bu isi basarabiliyoruz. Bu sekilde otomatik reply mesaji alabilmenin iki yolu bulunuyor:
Kullanicilarin mailleri DG'a degil, bir user mailbox'a göndermeleri. Bunun için user mailbox'da 2 kural olusturmak gerekir:
Birinci kural gelen tüm mailleri DG'a forward veya redirect edecek >>> Inbox rule olarak olusturabiliriz, yani Outlook'un açik kalmasina gerek kalmaz
Ikinci kural gelen tüm mailleri bir template ile yanitlayacak >>> Inbox rule olarak olusturulamiyor. Ancak OOF içerisinde bir kural olusturularak sablon ile yanitla seçenegi mevcut ve Outlook açik olmasa da her gönderilen maile bu sekilde yanit veriliyor.
Burada birinci workaound'un avantaji otomatik yanitla kurali OOF içerisinden yapildigindan sirket içinden gelenlere uygulayip, digerlerine uygulamayabilirsiniz.
Test ortaminda ilk çözüm metodunu uygulamayi deneyelim:
User Mailbox : HelpDesk
Distribution Group: DGTest
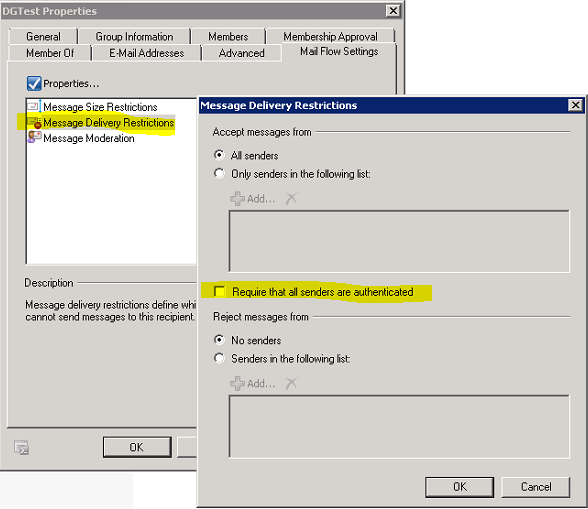
User Mailbox'daki ilk kuralimi EMS veya Outlook üzerinden olusturabilirim. Ben EMS'den asagidaki sekilde olusturarak, HelpDesk'e gelen tüm maillerin DGTest distribution group'una redirect edilmesini istedim:

Ufak bir dipnot verecek olursak, Redirect isleminin Forward'dan farki, mailin header'indaki "from", "to" gibi alanlarin degismeden ilgili kisinin inbox'ina teslim edilmesi. Yukarida olusturdugum kural ile mesaj redirect edilecegi için DG'da asagidaki alanin isaretli olmamasi gerekir:
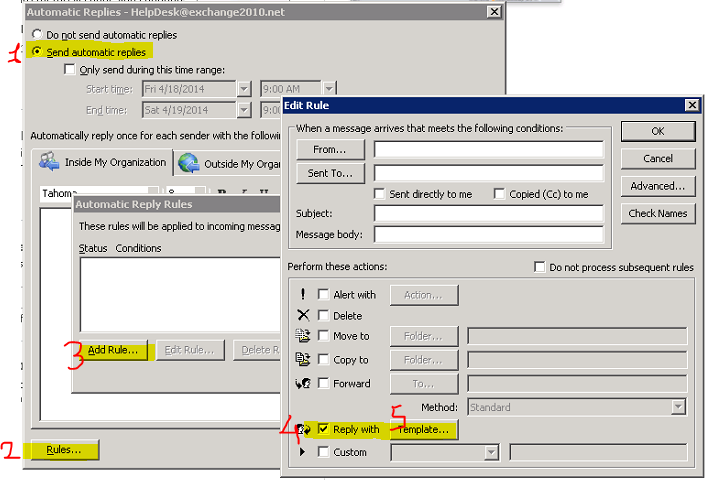
Ikinci kuralim için Outlook'da File>>Automatic Replies altinda OOF'I etkin hale getirerek "Rules" içerisinden AutoReply kuralimi olusturuyorum:
Muhtemelen çok sayida mail alan bir mailbox olacagindan, mailbox size'ini ona göre belirlemeniz gerekecek. Hatta archiving uygularsaniz gereksiz büyümenin önüne geçmis olursunuz.
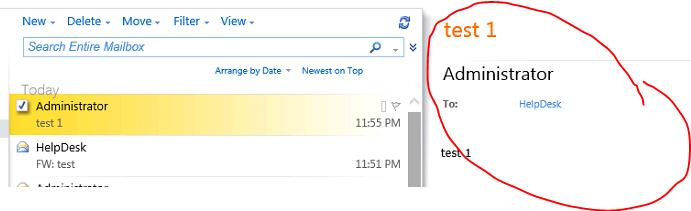
Böylece HelpDesk'e atilan tüm mailler DGTest distribution group'una üye kullanicilara redirect edilecek ve maili atanlara bir sablon ile reply yapilmis olacak. Redirect ettigimiz için gelen mesajlar DG üyelerine "from" ve "to" alanlari orginal haliyle korunarak iletilecek:
*************************************************************************************
Ikinci workaround'umuz kullaniicilarin mailleri bir mail enabled public folder'a göndermeleri. Ve yukaridaki ilk workaroundaki iki kuralin benzer sekilde olusturulmasi:
Birinci kural gelen tüm mailleri DG'a forward / redirect edecek veya maili attachment olarak da gönderebilir.
Ikinci kural gelen tüm mailleri bir template ile yanitlayacak
Test ortaminda ikinci çözüm metodunu uygulamayi deneyelim:
E-mail enabled PF : PFHelpDesk
Distribution Group: DGTest
PFHelpDesk adinda bir PF olusturduktan sonra bunu mail enabled hale getiriyorum ve kurali olusturacak kisiye PF üzerinde "send as" ve "owner" yetkisi veriyorum:
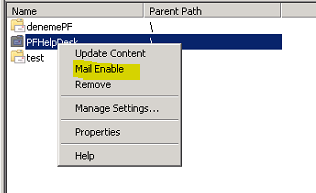
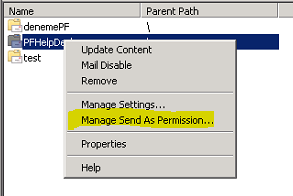
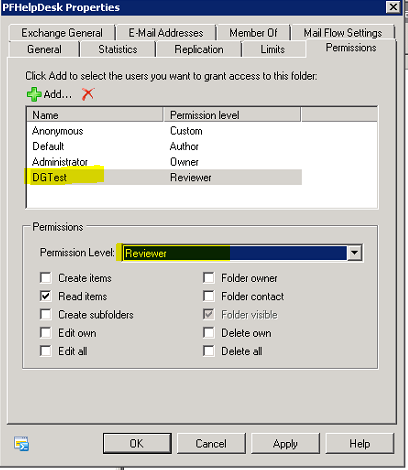
DG üyelerinin gelen mailleri ilgili PF altinda da görüntüleyebilmeleri için gruba "Reviewer" hakki veriyorum:
PF üzerinde SendAs ve Owner yetkisi verdigim kisi ile Outlook'u açip ilgili PF'un özelliklerine giriyorum ve kurallari olusturmak için "Folder Assistant"i tikliyorum:
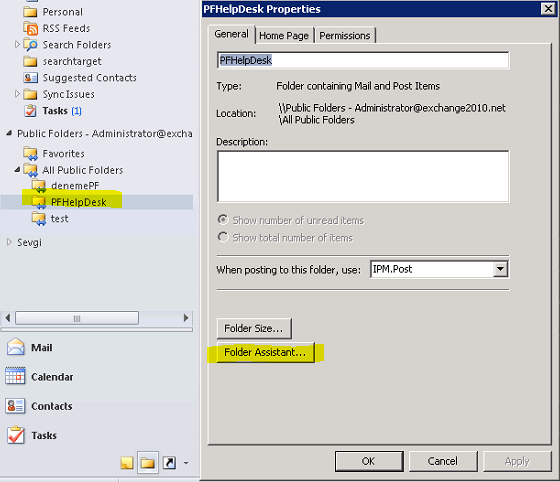
Iki kurali da (forward ve reply with template) gelen ekranda olusturuyorum.
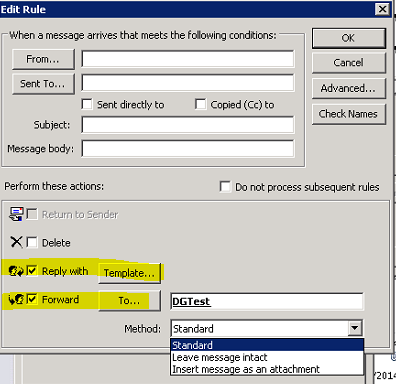
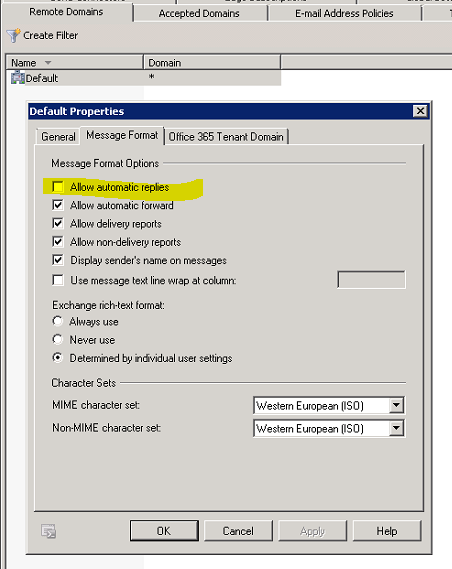
Burada önemli bir nokta, eger disaridan gönderilen mesajlara otomatik yanit dönülmesini istemiyorsaniz Exchange üzerinde Organization Conf.>>Hub Transport>>Remote Domains altinda "Allow automatic replies"in isaretini kaldirmalisiniz. Yalniz unutmayin, bu ayar organizasyonunuzdaki tüm autoreply mesajlara izin vermeyecektir.
Bu yazida dagitim listesine gönderilen maillere otomatik yanit alabilmenin yollarindan bahsettik. Iki çözüm metodundan ortaminiza en uygun olani tercih ederek uygulamaya geçebilirsiniz.
Sevgi Sifyan
Exchange 2007 autodiscover servisi - 1
Autodiscovery servisi outlook 2007 client'lar için otomatik profile konfigürasyonu ve offline address book gibi client baglantilarinda ihtiyaç duyulan ek URL'leri saglayan servisin adidir. Bir windows servisi olarak çalismaz ancak Client Access Server (CAS) rolünün bir alt fonksiyonu olarak exchange 2007 ile birlikte gelir.
Exchange 2007 kuruldugunda self signed sertifika edinir. Bu nedenle autodiscover dis baglantida çalismaz ve exchange üzerinde ek konfigürasyona ihtiyaç duyulur. Iç networkten ise kurulum sonrasinda küçük eksiklikler ile de olsa genellikle çalisacaktir. Bunun nedeni sirket içi baglantilarda autodiscover erisiminin Service Connection Point (SCP) üzerinden yapilabilmesidir.
Dis baglantinin dogru biçimde çalisabilmesi için tipki Outlook Anywhere'de oldugu gibi sertifika hatasinin hiçbir sekilde bulunmamasi gerekir. Bu nedenle CAS server'lara dogru biçimde internal yada external CA 'den alinmis sertifikalar kurulmalidir. Sertifikalarin trusted bir publisher'dan saglanmasi, isminin dogru olmasi ve tarih araliginin geçerli olmasi zorunlu kurallardir. Bunlardan özellikle isimlendirme genellikle karsimiza çikan temel hata olarak kendini gösteriyor. Örnegin; contoso.com autodiscover servisini kullanmak istesin. Bu durumda contoso.com sertifikasinin en azindan contoso.com yada autodiscover.contoso.com adinida subject yada subject alternative name olarak içermesi gerekiyor.
Sertifikanin subject alternative name kisminin içermesi gereken / önerilen temel örnek isimler sunlardir;
webmail.contoso.com -----------> owa erisimi için gereken isim.
contoso.com -----> zorunlu degildir, autodiscover için kullanilabilir.
autodiscover.contoso.com -----> autodiscover servisi için gerekli ve zorunlu eger contoso.com adi yoksa...
smtp.contoso.com ----> zorunlu degil, eger Transport servisi farkli bir IP'den ve TLS tabanli hizmet verecekse (HUB transport özellikle ayni server'da hizmet veriyorsa ve TLS kullanilacaksa düsünülmeli)
pop.contoso.com ----> zorunlu degil, eger pop baglanti için özel bir CAS kullanilacaksa
imap.contoso.com ----> zorunlu degil, eger imap baglanti için özel bir CAS kullanilacaksa
casservername ----> zorunlu degil eklenebilir netbios name
casservername2 ----> zorunlu degil eklenebilir netbios name
casservername.contoso.local ---> Internal OAB vb. baglantilarda gereken iç isim
casservername2.contoso.local -----> Internal OAB vb. baglantilarda gereken iç isim
Not: Birçok sertifika saglayici 40 ismi tek bir sertifikada verebiliyor. Zaman içerisinde bu sertifikalari yenisini almadan update ederek yeni isim ekleyebiliyoruz. Eger isimlendirme çok karisik bir durum ortaya çikariyorsa veya bizim için problem oluyorsa (internal name registered degilse ve baska bir sahibi varsa ) " * " wildcard sertifikayida gözardi etmemeliyiz. Örnegin; *.contoso.com gibi tek bir isim isimizi görecektir.
Bu isimlerden özellikle autodiscover.contoso.com ismi üzerinde durmak gerekiyor. By default outlook 2007 açildiginda active directory üzerinden connection (SCP) saglayarak autodiscover URL bilgisini bulur..

Fakat sirket disinda yada active directory baglantisi olmayan / saglanamayan durumlarda outlook ikinci denemeyi autodiscover.contoso.com olarak yapacak ve böylece servis bilgilerini edinecektir. (autodiscover adi degistirilebilir) Bu durum asagidaki figür ile temsil ediliyor...

Outlook 2007 açildiginda asagidaki URL'leri sirasi ile deneyecektir...
https://contoso.com/autodiscover/autodiscover.xml
https://autodiscover.contoso.com/autodiscover/autodiscover.xml
Not: SCP exchange'e özel bir kavram degildir. Istenildiginde özel uygulamalar için SCP kayitlari olusturulabilir. Active directory'de ilgili server objesinde yeralir.
https://msdn.microsoft.com/en-us/library/ms677638(VS.85).aspx
Yukaridanda anlasildigi üzere https gerekli ve zorunlu, bu nedenle dorgu sertifikayi edinmeliyiz. Bunun için exchange client access server (CAS) üzerinde asagidaki adimlari atarak ise baslayabiliriz.
1- Ilk adimimiz sertifika istegini olusturmak olmalidir. Bunun için asagidaki islem yapilmali ve New-ExchangeCertificate komutu kullanilmalidir.

Bu islem ile local sertifika store'da ilgili istek olusur ve buna bagli bir dosyada diske yazilir. Ilgili istek dosyasi C:\certREQ.txt dosysidir. Yukaridaki komutta -domainname ile tüm adlar belirtilmelidir. PrivateKeyExportable true dsye belirtilmeli böylece sertifkanin server'lar arasinda export edilerek tasinabilmesine izin verilmelidir.Ayrica bazi uygulamalar (özelikle mobile) subjectname'de geçen adin public URL olmasini zorunlu tutarlar. Bu nedenle CN=webmail.corpnet.com kullanilmistir.
Yukaridaki komut sadece sertifika istegini olusturmamizi sagliyor, sertifika almis olmuyoruz.
2- Ikinci adim olarak bu dosyayi (c:\certREQ.txt) sertifika saglayicimiza göndererek sertifikamizi ediniyoruz. Asagida kendi sertifika sunucumuzdan sertifka edinme adimlarini yazmaya çalistim.
I. Ilgili istek dosyasini sertifika sunucumuza kopyaliyoruz.
II. https://CAserver/certsrv ile sertifka sunucumuza baglaniyoruz.
III. "Select a certificate" seçenegini kullanarak, "Advanced certificate request" 'i seçiyoruz.
IV. "Submit a certificate request..." seçilir.
V. Request file içerigi "Saved request" alanina kopyalanir ve "Web Server" sertifika template olarak seçilir.
VI. Submit butonuna tiklanarak sertifika istegi girilimis olunur.
VII. Sertifika save edilerek CAS server'lara tasinir.
Not: Yukaridaki islemler ile elde edilecek .P7B uzantili dosya istegin yapildigi makinaya import edildikten sonra private key exportable olarak görülecektir.
Not: Import islemi için enaz CAS,HUB yada UM rolü ilgili makinada yüklü olmalidir.
3- Ilgili sertifikayi exchange server'a kopyaladik ve sira import isine geldi. Bunun için asagidaki komut çalistirilir.

Import islemi sonrasinda private key'in exportable oldugu asagidaki sertifikanin anahtar resminden anlasilabilir.

4- Artik sira ilgili sertifikayi Enable etmeye geldi. Bunun için Enable-ExchangeCertificate komutunu kullanmaliyiz. Enable ile hangi servisler için ilgili sertifikanin etkin olacagini belirtebiliriz. Bunlar kisaca SMTP,IMAP,POP3,UM ve IIS olabilir.

Eger IIS için import ettiysek ilgili sertifika IIS içerisinden de görülebilicektir.

Tüm bu islemlerden sonra bir "IISRESET /noforce" yapmak faydali olacaktir.
Bir sonraki makalede gerekli url set degisikliklerine deginecegim.
Kubilay Ekici
Exchange 2007 service pack 2'nin getirdiği audit özellikleri
Audit güvenlik ihtiyaçlari nedeniyle giderek artan bir oranda ihtiyaç haline geliyor. Bu anlamda exchange server üzerinde bulunan mailbox'larin güvenligi ve izlenmeside önemli.
Kim kimin adina mail gönderebiliyor, kimler kimlerin maillerini görebiliyor vb sorular giderek daha sik sorulmaya baslandi.
Exchange 2007 service pack 2 ile yeni auditing özellikleri gelmektedir. Bu özellikler ile exchange auditing eksikligini gidermis oluyor ve böylece store içerindeki hareketi loglayabiliyoruz.
Yeni diyebilecegimiz audit'i kisaca dört baslik altinda toplayabiliriz.
Folder Access --- Herhangi bir folder'a erisim durumunda
Message Access --- Bir mesajin açilmasi durumunda
Extended Send As --- Mailbox enabled user'in mesaj göndermesi durumunda
Extended Send On Behalf Of --- Mailbox enabled user için On Behalf Of kullanimi durmunda
Loglama saglamaktadirlar..
Bu loglar için yeni bir event log tipi olusturuyoruz ve loglari "Exchange Auditing"
adli event log biriminde biriktiriyoruz. Tabi butip eventlerin sayisi çok fazla olabilecegi ve bu veriler kaybedilmek istenmeyecegi için ihtiyaçlarimiza göre özellikle event file büyüklügüne dikkat etmek gerek.
Asagida 4 degisik eventten birer örnek ve kisa açiklamalar var.
Folder Access:
Event ID 10100 Veli Ali'nin Outbox'ini açmis. Her folder için ayri ayri event düsürülebildiginden çok net olarak erisimin nereye yapildigini anlayabiliyoruz.
Böylece eski 1016 eski tip event arayisina gerek kalmiyor.

Message Access:
Veli Ali'nin mailbox'indaki 30***EAD@e2k7-dc.e12.local message id'li mesaji ADI ve IP'si belirli client'tan outlook.exe'yi açmis.
Not: Mesaj silmeler özel bir event ile takip edilmez sadece access event'i yazilir.

Send As:
Asagidaki eventte Veli, Ali adina mail göndermis yine client adi,ip'si ve message ID net olarak anlasiliyor.
Hangi mesaji gönderdigini hangi client'i kullandigini ve ip'sinin o anda ne oldugunu yine event'ten ek olarak edinebiliyoruz.

Send On Behalf Of:
Veli Ali adina yetkili kilinmis ancak send-as degil send on behalf. Bunuda asagidaki event'ten anliyoruz.

Service Pack 2 release edildi.
Download:
https://www.microsoft.com/downloads/details.aspx?displaylang=en&FamilyID=4c4bd2a3-5e50-42b0-8bbb-2cc9afe3216a
Release Notes:
https://www.microsoft.com/downloads/details.aspx?FamilyID=ee7829a3-0ae8-44de-822c-908cd1034523&displaylang=en
Kubilay
Exchange 2007 Service Pack 3 Update Rollup 7
Exchange 2007 Service Pack 3 için Update Rollup 7, 16 Nisan 2012 tarihinde yayinlandi. Bu güncellemeyle ilgili detayli bilgilere https://support.microsoft.com/kb/2655203 adresinden ulasabilirsiniz. https://www.microsoft.com/downloads/details.aspx?FamilyID=51d1079c-b5e2-418d-9431-0e556917c5de adresinden ise bu güncellemeyi indirebilirsiniz.
Yapilan düzeltmeler arasinda önemli gördüklerimiz asagidaki gibidir:
- Mailbox için olusturulan sunucu temelli kurallar, ilgili mailbox Exchange Server 2007'den Exchange Server 2010'a tasinip, sonrasinda 2007'ye geri tasindiktan sonra çalismiyor. 2654700
- Mailbox'lar baska bir veritabani ya da farkli bir sunucudaki veritabanina tasindiginda, bu islem basarili bir sekilde tamamlanamiyor. Tasima sirasinda mailbox sunucuda %100 CPU kullanimi oldugu görülüyor. 2677583
- MSExchangePOP3 servisi crash oluyor. 2677979
- Public Folder'da bulunan bos bir PR_URL_NAME ögesi, Exchange Server 2007 ve Exchange Server 2010 bulunan bir ortamda replike edildiginde Store.exe crash oluyor. 2682570
- Microsoft Exchange Replication servisi Active Directory ile iletisim kurdugunda, eger active directory LDAP_PARAM_ERROR degerini gönderdiyse MSExchangeRepl.exe prosesi crash oluyor. 2694267
- Exchange Server 2007 ve Exchange Server 2010'un birlikte bulundugu ortamda, baska bir mailbox üzerinde Full Access hakki olan bir kullanici, Outlook Web Application kullanarak bu mailbox'i açamiyor. 2694274
Notlar:
- Eger Forefront Protection for Exchange kullaniyorsaniz, kurulumdan önce ForeFront'u fscutility /disable komutuyla devre disi birakmali, kurulum bittikten sonra da fscutility /enable komutuyla tekrar devreye almalisiniz.
- Kurulum sonrasinda Exchange'in kritik servisleri tekrar baslatilacaktir.
Burak Petekkaya
Exchange 2007'de queue'daki mesajları export etmek ve tekrar process ettirmek
Exchange 2007'de Queue Management için Queue viewer tool'u ve asagidaki komutlar kullanilabilir.. Exchange management shell'den kullanabileceginiz asagidaki komutlar bir daha Queue Viewer tool'unu kullanmamanizi saglayacak kadar etkin ve güzel. Kisaca komut listesini ve tanimini yapmaya çalistim.
Export-Message -----------> mesaj export/disariya almak için
Get-Message ----------> mesaj listelemek için
Get-Queue ------------> queue listelemek için
Remove-Message ----------> mesaj silmek için
Resume-Message ----------> mesaj devam için
Resume-Queue ----------> queue devam için
Retry-Queue -----------> queue retry/tekrar için
Suspend-Message -----------> mesaj bekletmek için
Suspend-Queue -----------> queue bekletmek için
Mailleri disari alma ihtiyaci günlük bir ihtiyaç degildir bazen networksel bazen donanimsal nedenler ile gerekebilir.
Öncelikle transport service'i pause etmemiz gerekiyor... Service pause ile exchange transport'a yeni mail girisini durdurmus oluyoruz.
![]()
Get-Queue ile queue içerisindeki mailleri bir yada daha çok alt queue'lariçerisinde görebiliriz.
Queue'daki bir mesaji export etmek için öncelikle ilgili mesaj yada mesajlar suspend edilmeli.
Get-Queue | Get-Message | Suspend-Message
Yukaridaki komut kümesi ile tüm mailleri suspend duruma geritiyoruz. Buradaki anacimiz tüm mailleri export etmek ve queue'dan silmek. Suspend ile maillerin deliver edilme ihtimali sifira indirilmis oluyoruz.
Mesajalarin suspend olup olmadiklari asagidaki komut kümesi..
Get-Queue | Get-Message
ile görülebilir. Mesajlarin bu asamada status'u artik "suspended" durumdadir...
Bu asamadan sonra mesajlari queue'dan export edebiliriz. Bunun için asagidaki komut kümesi...
Get-Queue | Get-Message | Export-Message -Path C:\temp
kullanilir. Burada path parametresi ile export edilecegi disk folder'i belirtilmis olunur...
Asagidaki örnekte mesajlar uykaridaki komutlar ile C:\Temp'e export ediliyor.
![]()
C:\Temp içegi;
![]()
Yukaridaki mesajlar hala queue'da durmaktadir, çünkü sadece export ettik.
![]()
Mesajlarin birden fazla "dublicate deliver" edilmesini önlemek için mutlaka queue database'i replace eidlmeli yada mesajlar queue'dan export edildikten sonra silinmelidir. Bu islemi gerçeklestirmek için;
Get-Queue | Get-Message | Remove-Message ----------------> dikkat bu komut queue'daki tüm mesajlari onayinizi alarak silecektir.
![]()
Yukaridaki gibi hata mesajlari gelebilir ilgili queue'lar sistem queue'sudur.
Export edilen mesajlar herhangi bir transport server üzerinde REPLAY \ PICKUP folder'ina konularak testrar process ettirilebilir...
Kisaca pickup fiolder'in replay folder'dan farki header firewall'dur.
Not: Submission queue ve Poison queue'daki mesajlari remove edemeyiz.
K. Ekici
Exchange 2007'de TELNET ile IMAP bağlantısı nasıl yapılır?
IMAP yani Internet Message Access Protocol ile Exchange Server 2007 üzerindeki bir mailbox baglantisi, telnet komutlari ile gerçeklestirilebilmektedir.
Burada Client Access Server rolü üzerinde olan Exchange 2007 sunucusu üzerinde telnet komutlari çalistirilmalidir.
Öncelikle, IMAP4 sanal sunucusunu plain text logon türü için ayarlayacagiz. Bunun için, Exchange Management Shell üzerinde asagidaki komut çalistirilir.
Set-ImapSettings –LoginType "plaintextlogin"
Ardindan yine Management Shell üzerinden Telnet ile IMAP oturumu açilir.
Telnet CAS IP Adresi 143
Eger IMAP4 servisiniz düzgün bir sekilde çalisiyor ise asagidaki gibi bir mesaj almalisiniz:
![]()
Bu asamadan sonra bir mailbox'a login olmak için asagidaki komutu çalistirin.
? LOGIN DomainIsmi/LoginIsmi Password
Bu komut sonrasinda eger user bilgileri dogru girildi ise su çiktiyi almalisiniz:
![]()
Tüm klasörleri listelemek için:
? LIST "" "*"
komutu çalistirilir.
Istedigimiz mailbox klasörünü açmak için ise:
? Select ilgiliKlasörIsmi
Bu komut eger basarili bir sekilde çalisir ise, suna benzer bir çikti alirsiniz.
![]()
Burada bir mesaji okumak için asagidaki komutlardan birisi çalistirilir.
? FETCH mesajnumarasi All
? FETCH mesajnumarasi Body
IMAP oturumunu sonlandirmak için asagidaki komut kullanilir.
? LOGOUT
Bu komut sonrasinda asagidaki gibi bir mesaj ile oturum sonlanir.
![]()
Volkan Günaydin
Exchange 2010 Service Pack 2 Update Rollup 2 ile gelen birkaç önemli düzeltme
Exchange 2010 Service Pack 2 için yayinlanan Update Rollup 2'de (KB2661854), asagidaki sorunlar için önemli düzeltmeler yapilmistir:
- Internet'e bagli olmayan bir Exchange Server 2007'ye proxy'lik yapan Exchange Server 2010'a Service Pack 2 Update Rollup 1 yüklendikten sonra, Outlook Web Application'a giris yapan kullanici, "an exception thrown in the proxy" hatasiyla karsilasiyor. KB2696913
- Kullanici, OWA ya da EWS'i kullanan bir uygulama araciligiyla recurring takvim ögesi açtiginda, Exchange Server 2010 Client Access Server'larda bulunan MSExchangeServicesAppPool'un kullandigi W3wp.exe prosesi, CPU kaynaklarinin tümünü kullaniyor. Bu sorun ortaya çiktiginda, OWA ve EWS uygulamasi Exchange Server 2010 sunucularina baglanamiyorlar. KB2688667
- Gönderilmis Ögeler 'de bulunan mesajlar ayni PR_INTERNET_MESSAGE_ID'ye sahipler. Bu sorun asagidaki üç farkli durumdan birinde ortaya çikmaktadir KB2592398:
Senaryo 1
-
-
- Yeni bir mesaj olusturdunuz ve bu mesaji Outlook Template dosyasi olarak kaydettiniz.
- Outlook Template dosyasini açtiniz ve email olarak gönderdiniz.
- Ayni template dosyasindan tekrar email gönderdiniz.
Senaryo 2
-
-
- Outlook ile email gönderdiniz.
- Sent Items'da bulunan mesaji açip bunu tekrar gönderdiniz.
Senaryo 3
-
-
- Yeni bir mesaj olusturup bunu Drafts klasörüne kaydettiniz.
- Bu mesaji farkli bir klasöre kopyaladiniz.
- Her iki mesaji da gönderdiniz.
Bu senaryolarin herhangi birinin gerçeklesmesi durumunda, Sent Items'daki iki mesaj da MFCMapi ile incelendiginde, PR_INTERNET_MESSAGE_ID degerinin ikisi içinde ayni oldugu görülmekte. Ayrica bu durumdan dolayi, gönderilen ikinci mesaj alicilara ulasmamakta ve bununla ilgili NDR gönderilmemekte.
- Belli bir mailbox'in Microsoft Outlook for MAC 2011'le erisimi, Set-CasMailbox ya da Set-OrganizationConfig komutlariyla EwsAllowMacOutlook parametresi false yapilmasi suretiyle engellenmesine ragmen, bu kullanicinin login olabildigi görülüyor. KB2630808
- Asagidaki senaryo dahilinde, bazi mobile cizhalardan mailbox'a erisilemiyor. KB2661277:
-
-
- Trust kurulmus iki Exchange Server 2010 forest'i var.
- Exchange Management Console ya da Exchange Management Shell araciligiyla, Microsoft Server ActiveSync Virtual directory içerisinde ExternalURL 'de adres konfigürasyonu yapilmis.
- Kullanici uzak forest'da bulunuyor ve cihazin Exchange ActiveSync (EAS) versiyonu 12.1'den eski.
- Exchange Server 2010 Client Access Server http 451 redirect cevabi gönderiyor. Ilgili cihaz, http 451 redirect cevabini tanimadigi için yönlendirme basarili olmuyor.
- Asagidaki senaryoda, olusturulan contact'in isim bölümü Address Book'da bos olarak görünüyor. KB2678414:
-
-
- Outlook online olarak kullaniliyor.
- Public folder ya da mailbox'ta yeni bir contact olusturuluyor.
- Full Name bölümü bos birakilip, sadece Company bölümüne isim giriliyor.
- Address Book açilip buradan Contacts seçiliyor.
Önemli degisiklikler oldukça deginmeye çalisacagiz.
Burak Petekkaya
Exchange 2010 Service Pack 2 Update Rollup 4 ve birkaç önemli düzeltme
Exchange 2010 Service Pack 2 için Update Rollup 4, 13 Agustos 2012 tarihinde yayinlandi.
Bu güncellemeyle ilgili detayli bilgilere https://support.microsoft.com/kb/2706690 adresinden ulasabilir ve https://www.microsoft.com/en-us/download/details.aspx?id=30478 adresinden ise bu güncellemeyi indirebilirsiniz.
Yapilan düzeltmeler arasinda önemli gördüklerimiz asagidaki gibidir:
- Microsoft Exchange Server WebReady doküman görüntüleme özelligindeki güvenlik açigi, uzaktan kod çalistirilmasina neden olabilir. 2740358
- Exchange 2010 mesajlari Journal Mailbox'a aktarilmiyor. 2686540
- EdgeTransport.exe prosesi sürekli olarak crash oluyor. 2709935
Üzerinde tam erisim hakki olunmasina ragmen kullanicinin free/busy bilgisi görüntülenemiyor. 2701162
Exchange Server 2010 ve 2003'ün birlikte bulundugu bir ortamda, eger konu kisminda iki nokta üst üste ":" bulunuyorsa, mesaji bir mailbox'tan farkli bir mailbox'a aktardiginizda konu kisminda bulunan bilgilerin bir bölümü siliniyor. 2724188
Notlar:
- Eger Forefront Protection for Exchange kullaniyorsaniz, kurulumdan önce ForeFront'u fscutility /disable komutuyla devre disi birakmali, kurulum bittikten sonra da fscutility /enable komutuyla tekrar devreye almalisiniz.
- Kurulum sonrasinda Exchange'in kritik servisleri tekrar baslatilacaktir.
Burak Petekkaya
Exchange 2010 SP1 için RU8, Exchange 2010 SP2 için RU5 v2 ve Exchange 2007 SP3 için RU9 11 Aralık 2012 de yayınlandı
Exchange 2010 SP1 için Ru8, Exchange 2010 SP2 için Ru5 v2 ve Exchange 2007 SP3 için Ru9 11 Aralik 2012 de yayinlandi. Ilgili Exchange blog sayfasi: https://blogs.technet.com/b/exchange/archive/2012/12/11/released-update-rollup-5-v2-for-exchange-2010-sp2-exchange-2010-sp1-ru8-and-exchange-2007-sp3-ru9.aspx
Exchange 2007 SP3 Ru9 ile gelen en önemli fix EdgeTransport.exe isleminin tekrarlanan toplanti istegini islerken crash etmesidir. Sunucu sadece bir defa olusan ancak tekrarlanan toplantiyi islerken bu problemi vermektedir. Bunun nedeni AppointmentReccurenceBlob özelliginin bu tip toplanti istekleri için desteklenmemis olmasidir. Bu nedenle InvalidOperationException hatasi alinarak EdgeTrasnport.exe crash ediyor.
Bu kosulda event loglara düsecek olasi hatalar:
Time: Time
ID: 10003
Level: Error
Source: MSExchangeTransport
Machine: Computer
Message: The transport process failed during message processing with the following call stack: System.InvalidOperationException: Property AppointmentRecurrenceBlob is not permitted on meeting occurrences.
Time: Time
ID: 4999
Level: Error
Source: MSExchange Common
Machine: Computer
Message: Watson report about to be sent to dw20.exe for process id: Process ID, with parameters: E12, Build Type, Version Number, edgetransport, M.E.D.Storage, M.E.D.S.OccurrencePropertyBag.InternalSetValidatedStoreProperty, System.InvalidOperationException, XXXX, Version Number. ErrorReportingEnabled: False
Güncellemeyle ilgili daha detayli bilgiye https://support.microsoft.com/kb/2748658 buradan ulasabilirsiniz.
Exchange 2010 SP2 UR5 v2 ile de gelen önemli fixler var bunlardan sik karsilastiklarimiz sunlar;
Gönderici attigi epostanin bazi alicilara iletilmesine ragmen iletim listesindeki herkes için iletilemedi (NDR) mesajini almasi. Bunun nedeni Hub Transport sunucunun disariya email atilirken 3rd party smart-host ile route ederken Delivery Service Notification (DSN) tablosundan yanlis alicilari eklemesidir. Detayli bilgi için https://support.microsoft.com/kb/2748767
Microsoft Exchange Replication servisinin Exchange 2003 den Exchange 2010 a mailbox tasinirken araliklarla crash etmesi. Bunun sebebi Excange 2010 CAS sunucunun tamamlanmis
tasima talebini silerken o esnada olan tasima islemini düzgün isleyememesidir.
Event loglara düsebilecek olasi hatalar:
Log Name: Application
Source: MSExchange Mailbox Replication
Date: Date
Event ID: 1121
Task Category: Request
Level: Error
Keywords: Classic
User: N/A
Computer: Computer
Description: The Microsoft Exchange Mailbox Replication service was unable to process a request due to an unexpected error.
Request GUID:GUID
Database GUID: GUID
Error: MapiExceptionNotFound: Unable to open entry ID. (hr=0x80004005, ec=-1601)
Log Name: Application
Source: MSExchange Common
Date: Date
Event ID: 4999
Task Category:General
Level: Error
Keywords: Classic
User: N/A
Computer: Computer
Description: Watson report about to be sent for process id: Process ID, with parameters: E12, Build Type,Version Number, MSExchangeMailboxReplication,
M.Exchange.MailboxReplicationService, M.E.M.MoveBaseJob.<BeginJob>b__c, System.NullReferenceException, XXX, Version Number.
ErrorReportingEnabled: True
Log Name: System
Source: Service Control Manager
Date: Date
Event ID: 7031
Task Category: None
Level: Error
Keywords: Classic
User: N/A
Computer: Computer
Description: The Microsoft Exchange Mailbox Replication service terminated unexpectedly. It has done this XX time (s). The following corrective action will be taken in XX
milliseconds: Restart the service.
Fix ile ilgili daha ayrintili bilgiye buradan ulasabilirsiniz https://support.microsoft.com/kb/2727802.
Bir diger önemli mesele Exchange 2010 Mailbox server Store.exe servisinin VSAPI (virus scanning API) tabanli antivirus yazilimi kullanimi sonucunda crash etmesidir. Bunun sebebi Exchange sunucunun yanlislikla noktali virgül isaretini bazi VSAPI 2.6 protokolünün kullandigi bazi property lere koymasidir. Bu nedenle üstesinden gelinemeyen kural disi bir durum olusur ve store.exe crash eder.
Event loglara düsebilecek olasi hatalar:
Log Name: Application
Source: Application Error
Date: Date
Event ID: 1000
Task Category: (100)
Level: Error
Keywords: Classic
User: N/A
Computer: Computer
Description:Faulting application store.exe, version Version, time stamp TimeStamp, faulting module mdbrest.dll, version Version, time stamp TimeStamp, exception code 0xc0000005, fault offset
Offset, process id ProcessID, application start time Time.
Fix in detaylarina buradan ulasabilirsiniz https://support.microsoft.com/kb/2716145.
C. Sinem Tosun
Exchange 2013 High Availability
Iki bölümlük bu makale dizisinde Exchange 2013'le gelen yüksek erisilebilirlik çözümlerinden bahsediyor olacagiz.Ayrintilarini bulacaginiz konu basliklari ise su sekilde:
* Multiple Databases Per Volume
* Automatic Reseed
* Safety Net
* Lagged Copy'deki gelismeler
* Site Resilience
Multiple Databases Per Volume
Her bir volume'da birden fazla database tutabilme özelligi.
Günümüzde tasinabilir disk'lerin bile birkaç TB boyutuna ulastigini düsünürsek, disk kapasitesinde son yillarda yasanan ivmeli artisi görmüs oluruz. Bunun yaninda Exchange tarafindan baktigimizda
önerilen maksimum database boyutu 2 TB ile sinirlidir ve hatta bu boyutlara pek yaklasmadan ikinci bir database ile devam etmeniz yönetimsel açidan faydali olacaktir. Ne kadar büyük database'e sahip olursak o kadar backup – restore
islemleri uzayacak, database recovery islemleri daha uzun zamaninizi alacaktir. Kopyalardan birinde bir sorun oldugunda reseed islemi bir kabus haline gelip birkaç gününüzü bile alabilir.
Diger taraftan 8TB'lik bir disk alip en fazla 2TB'ini kullanmak pek mantikli görünmüyor! Exchange 2013 bu duruma karsi "Multiple Databases Per Volume" kavrami ile karsimiza çikiyor. Bu özellik sayesinde:
- Database size'larini daha küçük boyutlu tutarak, sorun oldugunda daha hizli recovery imkani sunuyor.
- Reseed islemleri daha güvenilir ve hizli yapilabiliyor.
- Disklerinizi daha verimli kullanmanizi sagliyor.
Yalniz bir volume'da birden fazla database tutabilmek için simetrik bir kopya database dagilimi gerekli. Örnegin bir volume'da 4 database tutacaksaniz, her bir database'in 4 kopyasi bulunmali.
Yani 4 mailbox sunucunuz olmali. Asagidaki diagramda örnek bir konfigürasyon bulunmakta:
CheckpointDepth: Bu deger Exchange 2010'da aktif kopya için 100 MB, pasif kopya için 5 MB iken; Exchange 2013'de pasif kopya için de 100 MB'a çikarildi. Bu sayede disk IOPS degerlerinde düsme saglanirken, diger bir avantaj olarak failover gerçeklesme zamanlarinin 2 kat hizli oldugu gözlemlendi.
Automatic Reseed
Disk'de yasanabilecek bozulma gibi Reseed'i gerektirecek durumlarda islemlerin manual degil de otomatik yapilmasini saglayan bir özelliktir. Bunun için yedek bir diskin olmasi ve gerekli konfigürasyon ayarlarinin yapilmasi sart. Disk failure durumunda sistem bu yedek diski sorunlu diskle replace ederek, otomatik reseed islemini baslatir. Failure durumunu farkedebilmek için sistem, database'lerin saglikliligini düzenli olarak kontrol eder. Sorun görüldügünde de sorunlu disk'te yer alan database'ler, automatic reseed devreye alinarak yeniden olusturulur. Öncesinde yapilan simetrik kopya dagilimi sayesinde database kopyalari farkli sunucularda aktif
oldugundan reseed için kullanilan kaynak sunucu da farkli sunucular olacak ve islem paralel olarak yapildigindan bu da reseed süresini kisaltacaktir.
Auto reseed ile gelen DAG parametreleri ise sunlardir:
AutoDagVolumesRootFolderPath – Tüm volume'larin, spare volume'lar da dahil, yer aldigi mount point'i isaret eder
AutoDagDatabasesRootFolderPath – Database'lerin yer aldigi mount point'i isaret eder
AutoDagDatabaseCopiesPerVolume – Volume basina kaç database tutulacagini gösterir
Safety Net
Exchange 2010'da mail akisinda yasanabilecek bir soruna karsi kullandigimiz teknolojiler olarak Shadow Redundancy, Transport Dumpster, Delayed Acknowledgement ve mesajin belli süre ilgili queue'da beklemesini gösterebiliriz.
Exchange 2013'de yeni bir terim karsiliyor bizi, Safety Net. Transport Dumpster'in yerini alan Safety Net, Transport Dumpster'dan farkli olarak feedback mekanizmasiyla çalismiyor. Her aktif database kopyasinin kendine özel bir Safety
Net queue'su bulunur. Sunucu tarafindan basari ile islenen maillerin bir kopyasi bu queue'da toplanir ve varsayilan olarak 2 gün boyunca bu queue'da kalir, istenirse bu süre degistirilebilir. Örnegin 3 güne çikarmak için asagidaki gibi bir komut çalistirmaliyiz:
Set-TransportService MBXServerName -MessageExpirationTimeout 3.00:00:00
Transport Dumpster sadece DAG ortaminda geçerli idi. Safety Net için ise böyle bir sart gerekmiyor. DAG olmayan bir ortamda islenen maillerin bir kopyasi ayni site'daki diger mailbox sunucuda tutulur.
Transport Dumpster'da mesajin kopyasi bir sunucuda tutulurken, Safety Net için single point of failure durumu yoktur. Primary Safety Net ve Shadow Safety Net adiyla iki farkli Safety Net'den bahsedebiliriz. Eger Primary Safety Net 12 saatten fazla erisilemez durumda kalirsa, resubmit istekleri shadow resubmit isteklerine dönüsür ve mesajlar Shadow Safety Net'den geri alinir.
Bu sebeplerle Exchange 2013'de "Guaranteed delivery" diye bir kavramdan bahsedebiliriz. Son bir bilgi, Safety Net için belirli bir boyut belirlemezsiniz, sadece mesajin Safety Net'den ne kadar süre sonra silinecegini belirlersiniz.
Kalan konularimiz Lagged Copy'deki gelismeler ve Site Resilience için "Exchange 2013 High Availability – Bölüm 2" makalesini inceleyebilirsiniz.
Sevgi Sifyan
Popular posts from this blog
[Excel] 문서에 오류가 있는지 확인하는 방법 Excel 문서를 편집하는 도중에 "셀 서식이 너무 많습니다." 메시지가 나오면서 서식을 더 이상 추가할 수 없거나, 문서의 크기가 예상보다 너무 클 때 , 특정 이름이 이미 있다는 메시지가 나오면서 '이름 충돌' 메시지가 계속 나올 때 가 있을 것입니다. 문서에 오류가 있는지 확인하는 방법에 대해서 설명합니다. ※ 문서를 수정하기 전에 수정 과정에서 데이터가 손실될 가능성이 있으므로 백업 본을 하나 만들어 놓습니다. 현상 및 원인 "셀 서식이 너무 많습니다." Excel의 Workbook은 97-2003 버전의 경우 약 4,000개 2007 버전의 경우 약 64,000개 의 서로 다른 셀 서식 조합을 가질 수 있습니다. 셀 서식 조합이라는 것은 글꼴 서식(예- 글꼴 종류, 크기, 기울임, 굵은 글꼴, 밑줄 등)이나 괘선(괘선의 위치, 색상 등), 무늬나 음영, 표시 형식, 맞춤, 셀 보호 등 을 포함합니다. Excel 2007에서는 1,024개의 전역 글꼴 종류를 사용할 수 있고 통합 문서당 512개까지 사용할 수 있습니다. 따라서 셀 서식 조합의 개수 제한을 초과한 경우에는 "셀 서식이 너무 많습니다." 메시지가 발생하는 것입니다. 그러나 대부분의 경우, 사용자가 직접 넣은 서식으로 개수 제한을 초과하는 경우는 드뭅니다. 셀 서식이 개수 제한을 넘도록 자동으로 서식을 추가해 주는 Laroux나 Pldt 같은 매크로 바이러스 에 감염이 되었거나, 매크로 바이러스에 감염이 되었던 문서의 시트를 [시트 이동/복사]하여 가져온 경우 시트의 서식, 스타일이 옮겨와 문제가 될 수 있습니다. "셀 서식이 너무 많습니다." 메시지가 발생하지 않도록 하기 위한 예방법 글꼴(종류, 크기, 색, 굵기, 기울임, 밑줄), 셀 채우기 색, 행 높이, 열 너비, 테두리(선 종류, ...
ASP.NET AJAX RC 1 is here! Download now
Moving on with WebParticles 1 Deploying to the _app_bin folder This post adds to Tony Rabun's post "WebParticles: Developing and Using Web User Controls WebParts in Microsoft Office SharePoint Server 2007" . In the original post, the web part DLLs are deployed in the GAC. During the development period, this could become a bit of a pain as you will be doing numerous compile, deploy then test cycles. Putting the DLLs in the _app_bin folder of the SharePoint web application makes things a bit easier. Make sure the web part class that load the user control has the GUID attribute and the constructor sets the export mode to all. Figure 1 - The web part class 2. Add the AllowPartiallyTrustedCallers Attribute to the AssemblyInfo.cs file of the web part project and all other DLL projects it is referencing. Figure 2 - Marking the assembly with AllowPartiallyTrustedCallers attribute 3. Copy all the DLLs from the bin folder of the web part...
Architecture Testing Guide Released
视频教程和截图:Windows8.1 Update 1 [原文发表地址] : Video Tutorial and Screenshots: Windows 8.1 Update 1 [原文发表时间] : 4/3/2014 我有一个私人的MSDN账户,所以我第一时间下载安装了Windows8.1 Update,在未来的几周内他将会慢慢的被公诸于世。 这会是最终的版本吗?它只是一项显著的改进而已。我在用X1碳触摸屏的笔记本电脑,虽然他有一个触摸屏,但我经常用的却是鼠标和键盘。在Store应用程序(全屏)和桌面程序之间来回切换让我感到很惬意,但总是会有一点瑕疵。你正在跨越两个世界。我想要生活在统一的世界,而这个Windows的更新以统一的度量方式将他们二者合并到一起,这就意味着当我使用我的电脑的时候会非常流畅。 我刚刚公开了一个全新的5分钟长YouTube视频,它可以带你参观一下一些新功能。 https://www.youtube.com/watch?feature=player_embedded&v=BcW8wu0Qnew#t=0 在你升级完成之后,你会立刻注意到Windows Store-一个全屏的应用程序,请注意它是固定在你的桌面的任务栏上。现在你也可以把任何的应用程序固定到你的任务栏上。 甚至更好,你可以右键关闭它们,就像以前一样: 像Xbox Music这种使用媒体控件的Windows Store应用程序也能获得类似于任务栏按钮内嵌媒体控件的任务栏功能增强。在这里,当我在桌面的时候,我可以控制Windows Store里面的音乐。当你按音量键的时候,通用音乐的控件也会弹出来。 现在开始界面上会有一个电源按钮和搜索键 如果你用鼠标右键单击一个固定的磁片形图标(或按Shift+F10),你将会看到熟悉的菜单,通过菜单你可以改变大小,固定到任务栏等等。 还添加了一些不错的功能和微妙变化,这对经常出差的我来说非常棒。我现在可以管理我已知的Wi-Fi网络了,这在Win7里面是被去掉了或是隐藏了,以至于我曾经写了一个实用的 管理无线网络程序 。好了,现在它又可用了。 你可以将鼠标移至Windows Store应用程序的顶部,一个小标题栏会出现。单击标题栏的左边,然后你就可以...




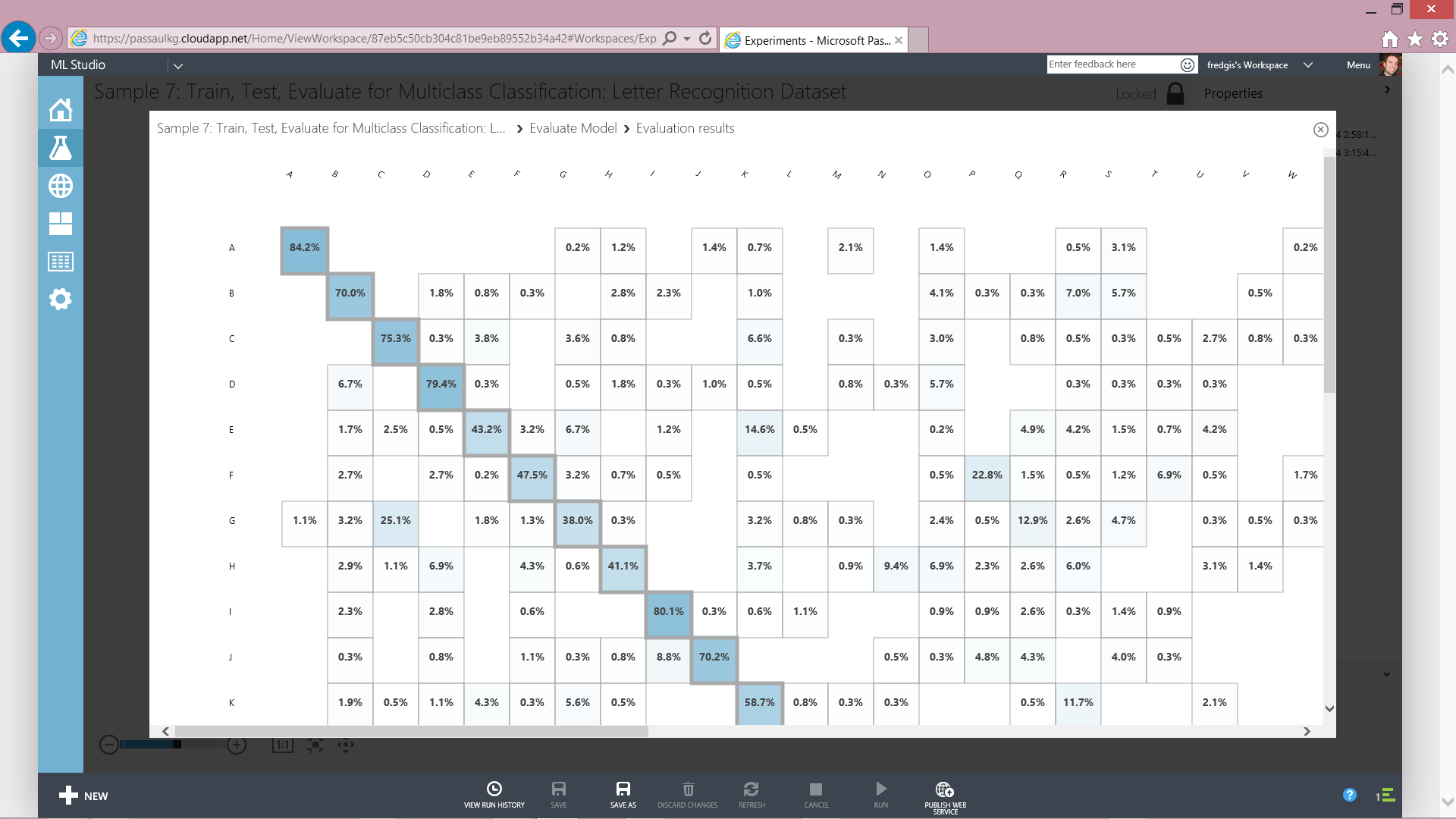{kind=link}
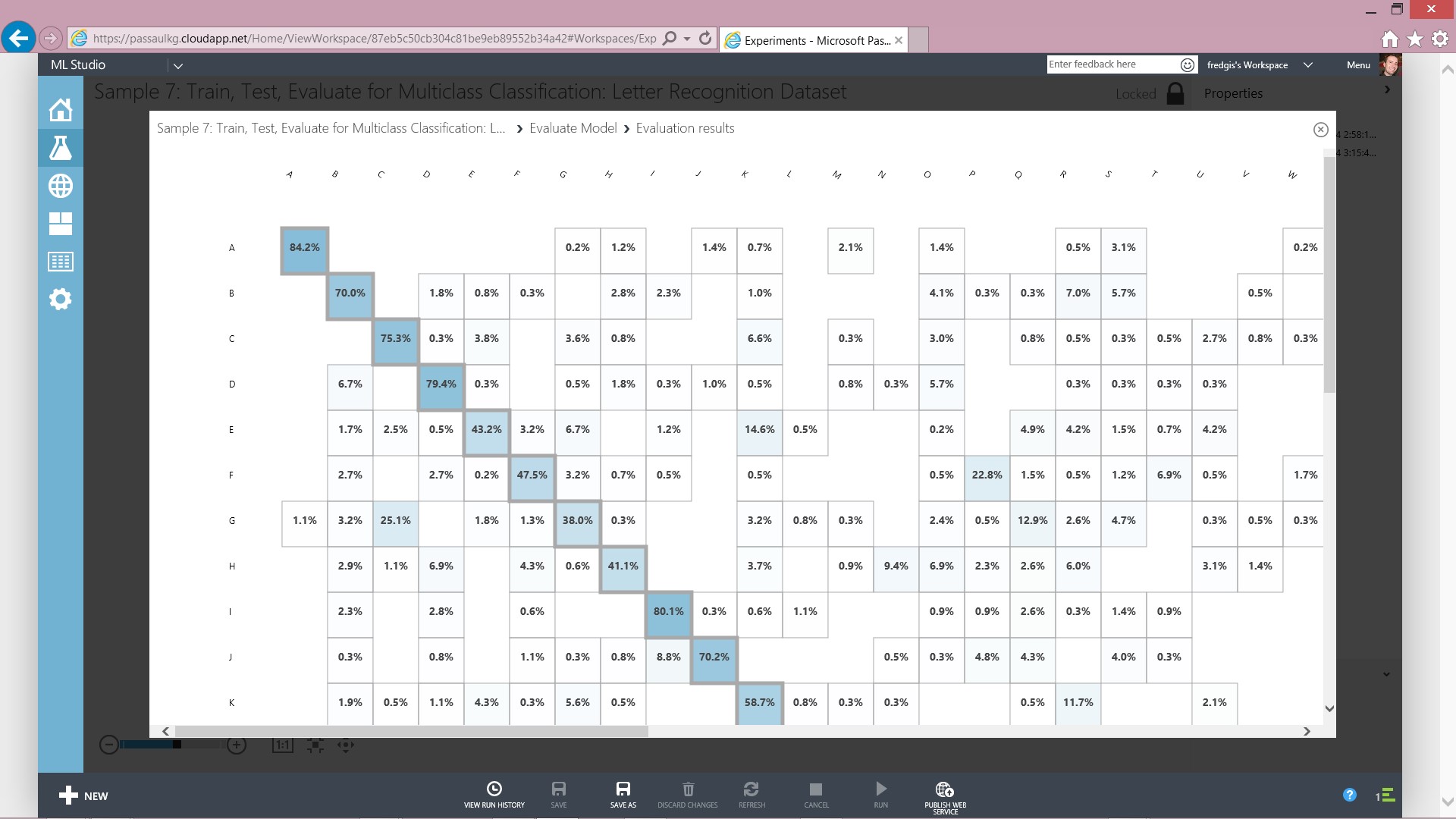{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Post a Comment