Skip to main content
Machine Learning para principiantes – Capítulo 6: prediciendo el futuro
Continuamos con el desarrollo de smartcontracts con Ethereum

Siguiendo con la miniserie de artículos sobre desarrollo de smart contracts con Ethereum que comentamos anteriormente, nuestro compañero @javierglozano ha publicado su siguiente articulo sobre el tema en su blog Minabta.
En este siguiente articulo desarrollaremos nuestro primer smart contract con Solidity (uno de los lenguajes de programación específicos para Ethereum y que se parece muy mucho a javascript) y como buenos desarrolladores además aplicaremos conceptos DevOps como tests unitarios e integración continua utilizando Mocha y Truffle.
Os anticipamos que la serie de articulos es bastante asequible y de momento no tendremos que preocuparnos con cuestiones más "oscuras" relacionadas con blockchain, aunque seguramente la cosa se empiece a poner un poco más "dura" conforme avancéis en la serie de artículos.
Nos ha comentado @javierglozano que está abierto a que le propongáis temas relacionados sobre los que desarrollar las siguientes entregas de su serie de artículos (aunque tiene material para algunos artículos más). Animaos y proponedle temas.
Seguiremos con interés los siguientes artículos y os comunicaremos sus siguientes entregas.
Crea tu primer bot inteligente!
¡Crea tu primer bot con Visual Studio, Microsoft Bot Framework y Microsoft Cognitive Services!
Hemos preparado un taller para entender cómo trabajar con Bot Framework y que sirva de ayuda para crearte tu propio bot.
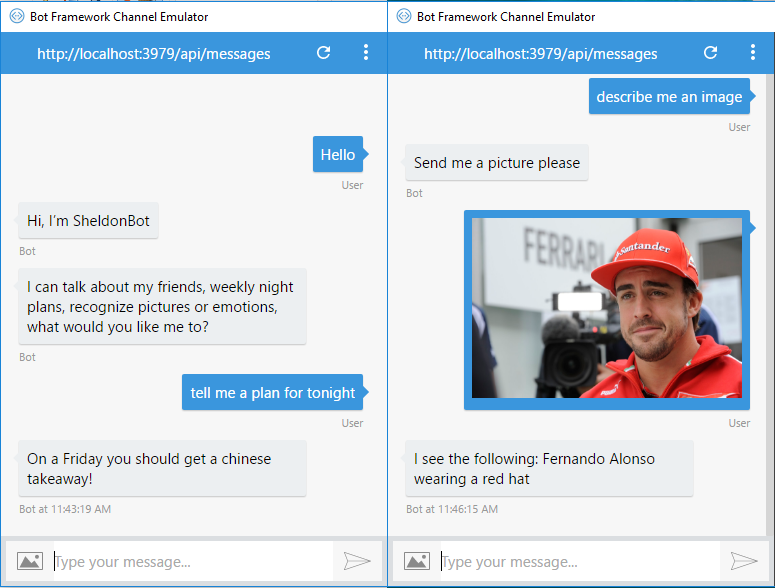
El resultado del taller es un SheldonBot, un bot capaz de:
- Hablarte de sus amigos.
- Recomendarte un plan en función del día de la semana que sea.
- Reconozca emociones en las caras de una foto que se le mande.
- Describirte una imagen que le mandes.
El taller se ha dividido en 5 módulos que cubren las distintas áreas de Bot Framework y los Servicios Cognitivos:
- Módulo 1: Crear un bot simple.
- Módulo 2: Publicar el bot en Azure, registrarlo en Bot Framework y conectarlo a distintos canales (Skype por ejemplo).
- Módulo 3: Añadir diálogos al bot.
- Módulo 4: Añadir inteligencia al bot con el servicio cognitivo LUIS.
- Módulo 5: Integrar servicios cognitivos de descripción de imágenes y reconocimiento de emociones faciales.
Aquí el enlace al taller: https://github.com/DanyStinson/BigBotTheory
Daniel Mitchell
Technical Evangelist Intern
@danymitb
emPower BI
¡Empieza a crear visualizaciones de tus datos con un par de clicks gracias a Power BI! Podrás diseñar informes y compartirlos en tu organización de una manera muy sencilla. Y lo mejor de todo, es que como parte de los servicios de Office 365, con Power BI puedes acceder a tus informes desde cualquier lugar.
Power BI cuenta con aplicación de escritorio, llamada Power BI Desktop, un portal (Power BI Service), aplicación para la Tablet y para tu teléfono.
Si quieres saber más sobre esta herramienta, hemos creado un taller que te servirá para comenzar a manejarte con Power BI Service, por lo que no será necesario descargar ningún software. Aprenderás a importar datos, analizarlos y a crear visualizaciones.
En este taller dispondrás de una base de datos sobre ventas de varias empresas canadienses, con campos como los productos que se venden, de qué tipo son, la empresa, unidades vendidas, ingresos por las ventas, dónde se han producido las ventas, entre otros.
El taller está dividido en 3 módulos, ¡pero habrá más! Tendrás incluso un módulo con los prerrequisitos necesarios para empezar con esta herramienta.
- Módulo 0 - Explorando el portal
- Módulo 1 - Visualizaciones I
- Módulo 2 - Visualizaciones II
- Módulo 3 - Dashboard y compartición de datos
¡Aquí tienes el enlace al taller!
Daniel Ortiz López
@ortizlopez91
Technical Evangelist Intern
Explorando Stream Analytics
Cuando hablamos de las últimas innovaciones, es inevitable pensar en el Internet of Things, o más bien conocido por sus siglas, IoT . Sobre los cimientos del IoT residen gran cantidad de dispositivos y tecnologías que no suponen ninguna novedad, sin embargo, su propósito es proporcionarles una capa de conectividad digital a través de la red por excelencia, Internet, aportándoles de esta manera más inteligencia.
Por tanto, el IoT supone una convergencia entre el mundo de los dispositivos cotidianos e Internet, y su idea principal es tener todos nuestros dispositivos conectados a la red, de manera se puedan comunicar entre sí.
Por ello, resulta esencial utilizar herramientas que analicen en tiempo real todos los datos que producen los aparatos que nos rodean. Con Stream Anaytics podrás implementar soluciones para obtener la información que generan tus dispositivos, sensores o aplicaciones en tiempo real. Así, actuarás como supervisor y administrador, de manera remota.
Configuración de Stream Analytics
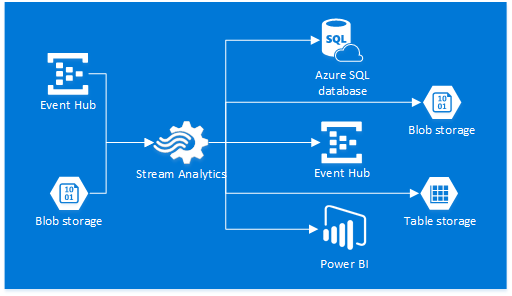
En este artículo vamos a ver cómo procesar datos en tiempo real a través de un Blob Storage, es decir, una vez hayamos ejecutado el Stream Analytics, subiremos un archivo a nuestro Blob Storage, que servirá como entrada. Le aplicaremos una función, y a continuación almacenaremos la salida de la función en otro contenedor Blob Storage.
Lo primero que haremos es crear una cuenta en Azure.
Una vez tengamos nuestra cuenta preparada, podemos empezar a crear y configurar el Stream Analytics. Desde el panel de la izquierda, añadimos un nuevo elemento " +" apoyándonos en el buscador:
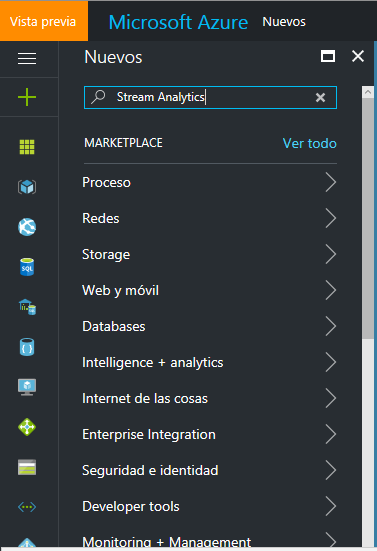
A continuación, tras la búsqueda seleccionamos el Stream Analytics Job - Crear:
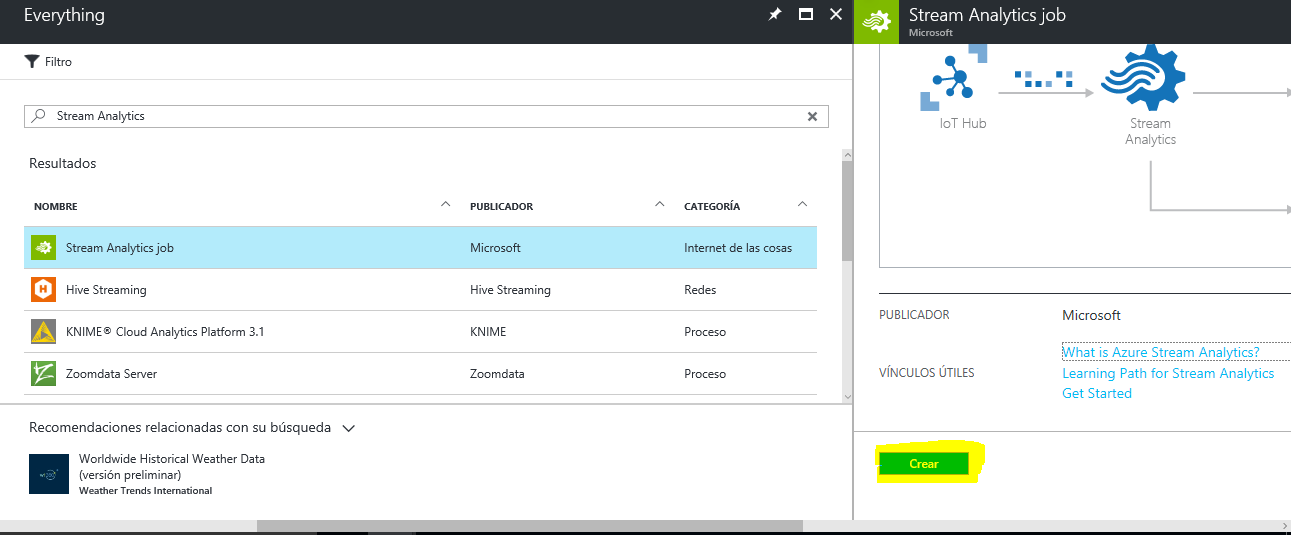
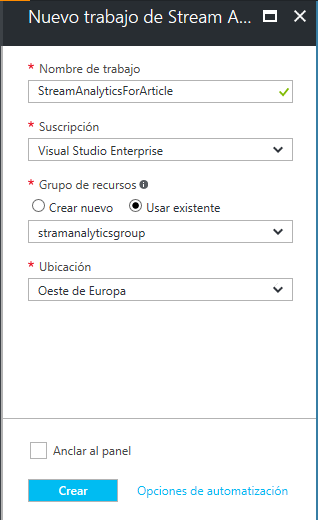
Ahora tendrás que asignarle un nombre y un grupo de recursos. En mi caso, le he asignado un grupo de recursos que ya tenía creado, pero si tu cuenta de Azure es nueva, necesitarás uno nuevo. Selecciona la opción de Crear Nuevo, introdúcele un nombre y solucionado.
Podrás acceder a los recursos que crees en el portal de Azure desde el botón que está debajo del "+" . Así pues, abrimos el Stream Analytics y nos encontramos con la siguiente interfaz: 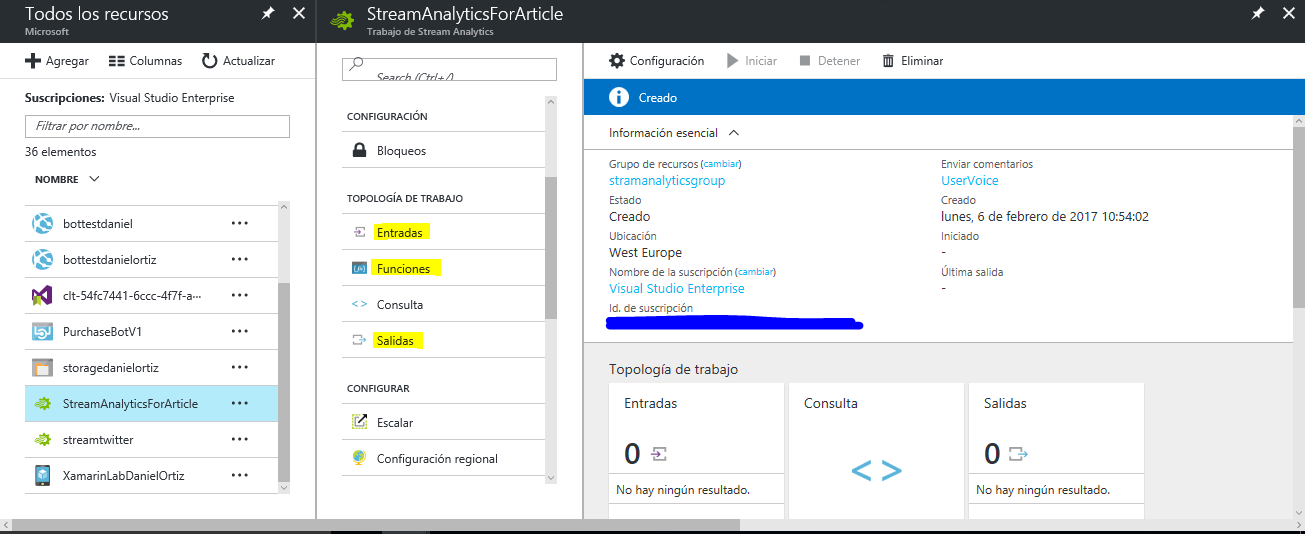
En los siguientes pasos configuraremos la entrada, salida y la función a aplicar.
Configuración del almacenamiento
En primer lugar, necesitaremos una cuenta de almacenamiento de tipo Blob Storage y a continuación crear dos contenedores. Puedes consultar este artículo en el que se explica cómo crear y manejar contenedores Blob Storage desde el Azure Storage Explorer.
Una vez tenemos el almacenamiento listo, volvemos al Stream Analytics y empezamos configurando la entrada: 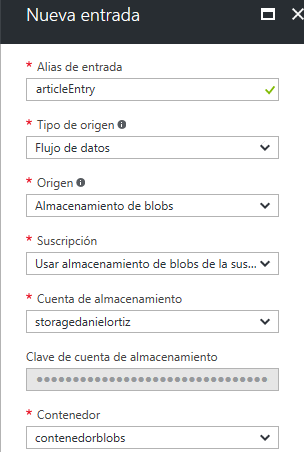
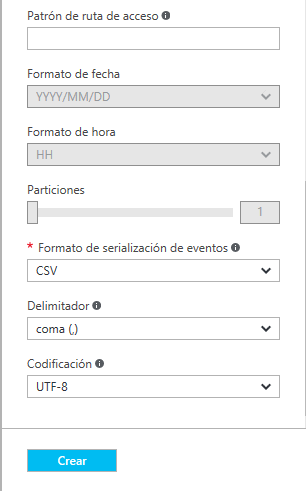
En mi caso, he introducido un nombre, he especificado que quiero usar un Almacenamiento Blob, y tras introducir mis credenciales, le asigno un contenedor ya creado, que he llamado contenedorblobs. Le he especificado en el Formato de serialización de eventos, que va a estar en formato CSV. Podrás usar también el formato JSON o Avro.
La configuración de la salida es muy similar. Introducimos un nombre, especificamos el almacenamiento que queremos, en nuestro caso Almacenamiento de blobs, indicamos el contenedor de salida y elegimos el formato de almacenamiento de tipo CSV.
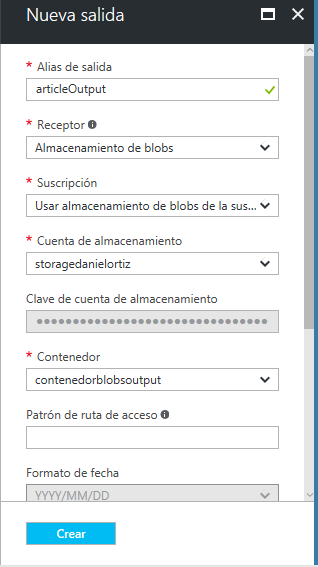
Si todo ha ido bien, en "Información General" te debería aparecer una entrada y una salida: 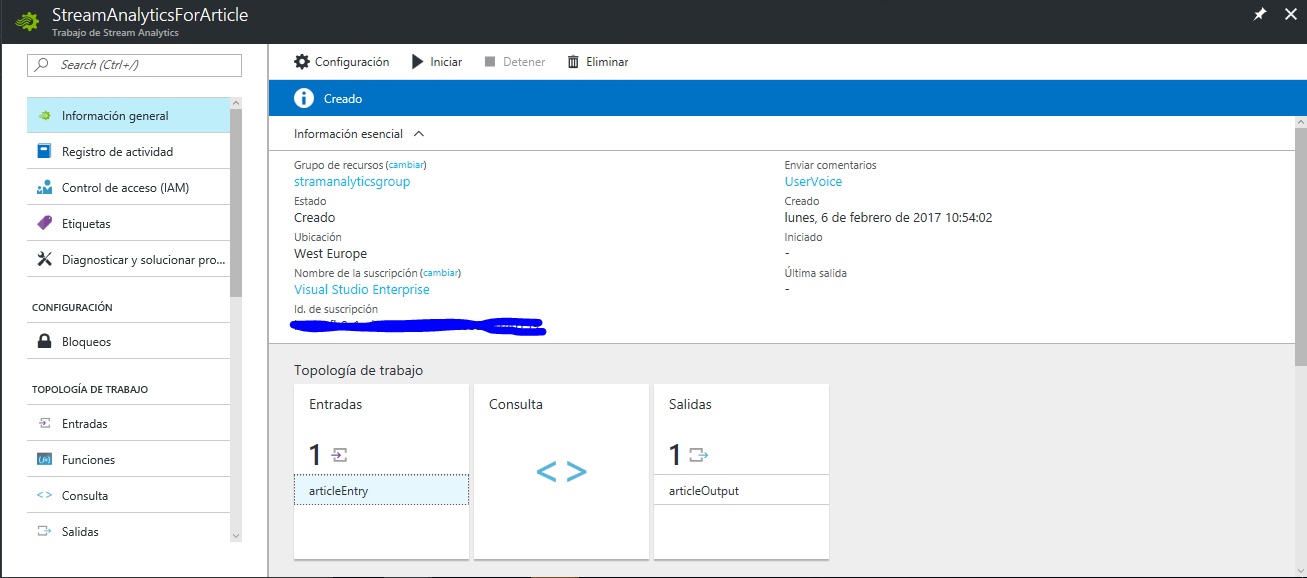
Ejecución de Stream Analytics
El siguiente paso es configurar el apartado < > Consulta. Con esto lo que hacemos es aplicar una query a los datos de entrada. En este ejemplo simplemente seleccionamos la columna Text del contenedor de entrada y la enviamos al de salida:
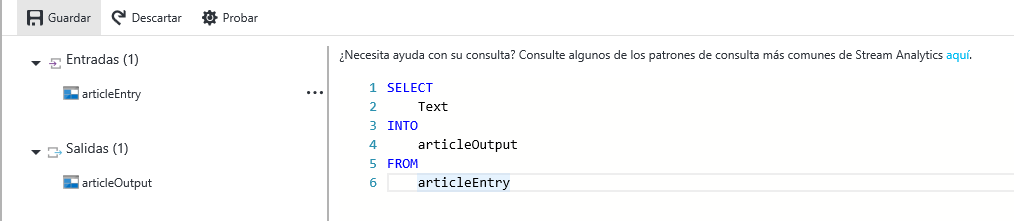
Le damos al botón de Iniciar y especificamos que queremos empezar el Stream Analytics ahora, ya que lo podemos programar para que comience en el momento que nos venga mejor. Por tanto, nuestro panel tendría que tener este aspecto:
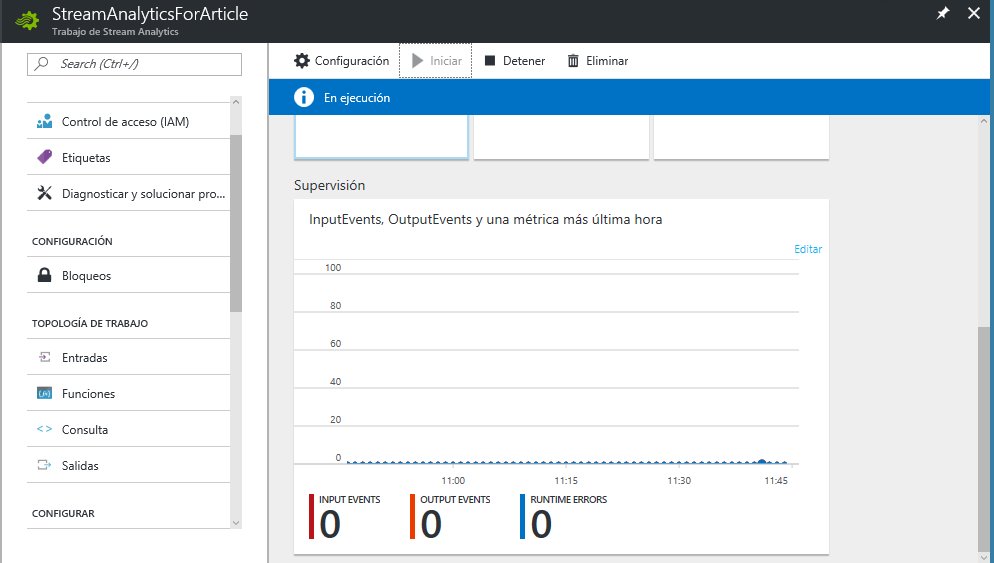
Ahora si, desde el Azure Storage Explorer introducimos un archivo .CSV, que en mi caso se llama book2.csv y poco después aparecerán en el portal de Azure tres entradas, correspondientes a las tres líneas que tiene mi archivo.
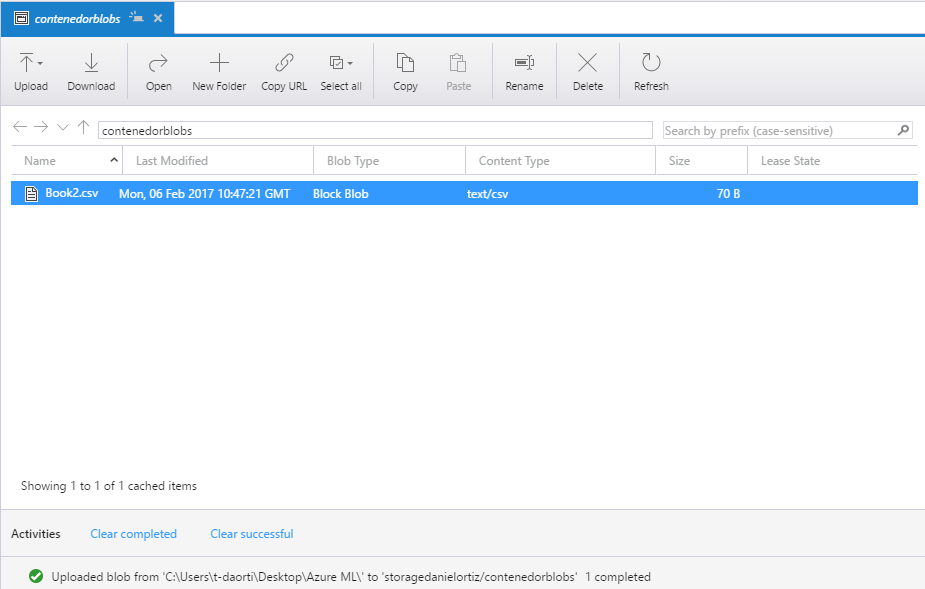
La mejor opción para comprobar si nuestro sistema funciona correctamente es ir al contenedor de salida y ver que efectivamente se creó un nuevo archivo con los datos del primero.
 Funciones Agregadas
Funciones Agregadas
Las funciones agregadas pueden realizar cálculos directamente sobre los datos que le entran, devolviendo un único valor. Además, estas funciones son determinísticas, de modo que devuelven el mismo valor cada vez que las llamamos con las mismas entradas. En este ejemplo vamos a probar la función MAX, aunque hay otras más:
| | |
| AVG | COUNT | Collect |
| CollectTOP | MAX | MIN |
| Percentile_Cont | Percentile_Disc | STDEV |
| STDEVP | SUM | TopOne |
| VAR | VARP | |
Ventanas Temporales
En muchos escenarios se analizan datos en tiempo real y es necesario establecer una ventana temporal para especificar cuándo quiero procesar estos datos. Este procesado se aplicará al final de cada ventana, sobre todos los datos recogidos en ese intervalo de tiempo.
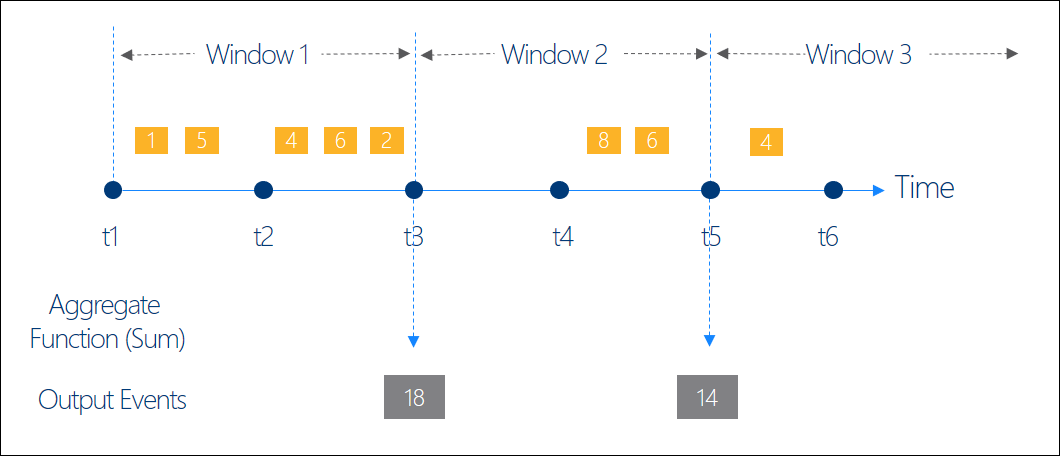
Existen varios tipos de ventanas : Trumbling, Hopping y Sliding. Para este ejemplo utilizaremos la Trumbling, que consiste en un conjunto de intervalos de tamaño fijo, no superpuestos y contiguos. En nuestro caso, crearemos una ventana de 5 minutos: 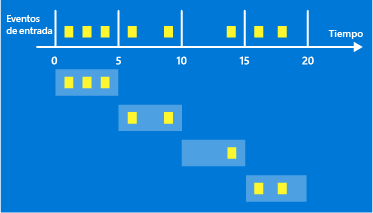
Cargamos la nueva consulta en el Stream Analytics:
SELECT MAX (Views) AS allEvents
INTO articleOutput
FROM articleEntry
GROUP BY TumblingWindow(minute,5)
Así, recogeremos eventos cada 5 minutos y los procesaremos al final de este intervalo, filtramos los eventos y seleccionamos el que tenga el campo Views más alto.
Este es un ejemplo de cómo puedes cargar y procesar datos en tiempo real con la herramienta Stream Analytics. En este caso, establecemos ventanas de tiempo de 5 minutos y aplicamos una función agregada (MAX), todo ello mediante entradas y salidas de archivos desde el Storage Explorer. También tenemos la opción de poner queries o incluso funciones dentro de las propias queries.
Daniel Ortiz
Technical Evangelist Intern
@ortizlopez91
GRACIAS por un Global Azure Bootcamp 2017 increíble
Queridas comunidades técnicas españolas:
Este año, de nuevo, habéis vuelto a dejarnos sin palabras con el Global Azure Bootcamp que habéis organizado. Más de 500 personas estuvieron este pasado sábado 22 de abril de 2017 en los eventos de Madrid, Barcelona, Palma de Mallorca y Tenerife. Eventos organizados íntegramente por la comunidad para la comunidad que se replicaron en todo el mundo hasta llegar a la cifra de 252 eventos por todo el planeta con más de diez mil asistentes en total.
El Global Azure Bootcamp es una demostración innegable del increíble poder de las comunidades técnicas a escala global. Es un evento de comunidad en estado puro, sin intereses comerciales, sin más ánimo que compartir conocimiento con todo aquel que esté interesado y hacer crecer la comunidad, una comunidad abierta e inclusiva a la que es una verdadera alegría pertenecer. Es un ejemplo de colaboración entre diferentes comunidades con diferentes intereses que se unen para aprender unos de otros y compartir la experiencia con personas de todo el mundo. Es increíblemente hermoso.
Este año, además, hemos tenido el privilegio de contar en Madrid con la presencia de Sebastián Hidalgo, el Doctor en Astrofísica del IAC artífice del algoritmo SELIGA - el centro del Science Lab del Global Azure Bootcamp de este año. Sebastián nos ha hecho comprender la complejidad detrás de la determinación del proceso de formación estelar y la importancia de la computación distribuida para poder afinar muchísimo más nuestra comprensión de ese proceso. Para mí, que he tenido experiencia personal en algunos campos de la supercomputación donde un simple milisegundo es una magnitud de tiempo elevada, fue revelador entender que conseguir afinar el modelo de SFH de una galaxia a una delta de Dirac que representaba, literalmente, "unos pocos millones de años"? nos iba a permitir comprender mucho mejor el proceso de formación estelar. Me emociona haber sido partícipe del Science Lab de este año, y estoy deseando que Sebastián consolide todos los cálculos hechos por todos nosotros con más de 100.000 horas de computación en más de 2000 cores para continuar con su investigación y compartir sus conclusiones.
Gracias a todos los que habéis hecho posible los eventos de Madrid, Barcelona, Palma y Tenerife. Desde los patrocinadores locales (Kabel, Sogeti y Tokiota en Madrid y Barcelona; Avanade, Encamina, Insight, Intelequia, Pasiona, y Plain Concepts en Madrid; XML Travelgate en Palma; Intech en Tenerife) hasta las numerosas comunidades técnicas que estuvisteis directamente involucradas en la organización (disculpad si dejamos de mencionar a alguna, decídnoslo por Twitter o en los comentarios y nos aseguraremos de añadiros!):













A todos los que asististeis, gracias por apoyar esta iniciativa de la comunidad. A los que no pudisteis asistir, podéis disfrutar de las grabaciones del track principal de Madrid aquí y os animamos a que no os lo perdáis el año que viene.
Queridas comunidades técnicas, a todos los que formáis parte de una manera u otra de esta gran familia, por vuestro trabajo para difundir las posibilidades que nos brinda la tecnología en cada ciudad en la que estáis, a cada persona que muestra interés, donando vuestro tiempo libre de manera incansable, estando siempre dispuestos a ayudar a quien lo necesite, solo podemos daros las gracias. Gracias de corazón. Sois un ejemplo y una inspiración para todos.
A todos los que aún no sois parte de esta increíble gran Comunidad Técnica con mayúsculas, os esperamos con los brazos abiertos 😊
Ester de Nicolás
Chief Evangelist - DX Spain
@esterdenicolas
Guía para principiantes de Xamarin
Desde Microsoft estamos apostando fuerte por herramientas que nos permitan desarrollar aplicaciones multiplataforma. En el caso de los móviles no iba a ser menos, y para ello contamos con Xamarin.
Es la herramienta con la que podrás desarrollar aplicaciones móviles nativas para Android, iOS y Windows Phone. Es decir, un único proyecto de código compartido te servirá para cada una de estas plataformas.
Eso sí, una herramienta de estas características precisa de bastantes dependencias, como del JDK de Java, SDK de Android, los emuladores e incluso un MAC para compilar las aplicaciones de iOS. Por ello, es imprescindible configurar bien el IDE, así como saber algunos trucos básicos a aplicar durante el desarrollo de nuestras apps móviles.
Ya que la mayoría de los problemas surgen al principio, cuando instalamos Xamarin, configuramos el entorno, y creamos nuestro primer "Hello World" , vamos a ver los pasos a seguir durante la instalación y configuración.

Como este post está dirigido a aquellos que estáis empezando con Xamarin, seguro que os viene muy bien la documentación oficial, así como el enlace al foro oficial de Xamarin.
A día de hoy no hay ninguna comunidad o foro público de Xamarin en castellano que tenga gran actividad. Así que os animamos a que forméis vuestros propios foros para hacer crecer esta comunidad de developers.
Instalación
Lo primero y más importante de todo, instalar bien el entorno de desarrollo. Una buena instalación va a evitar muchos problemas en el futuro y sobre todo va a hacer que nos ahorremos gran cantidad de tiempo en intentar solucionarlos.
Para desarrollar Xamarin vas a necesitar el Visual Studio, si estás con un Windows, o Xamarin Studio para el MAC. Ambas herramientas son gratuitas. Podrás descargar la versión Community del VS desde aquí o el XS en este enlace.
Ya que los proyectos de Xamarin dependen de varios paquetes y SDKs del Visual Studio, en este video se muestra cómo configurar su instalación para Visual Studio 2015, así como la compilación de la plantilla que viene por defecto, en las tres plataformas.
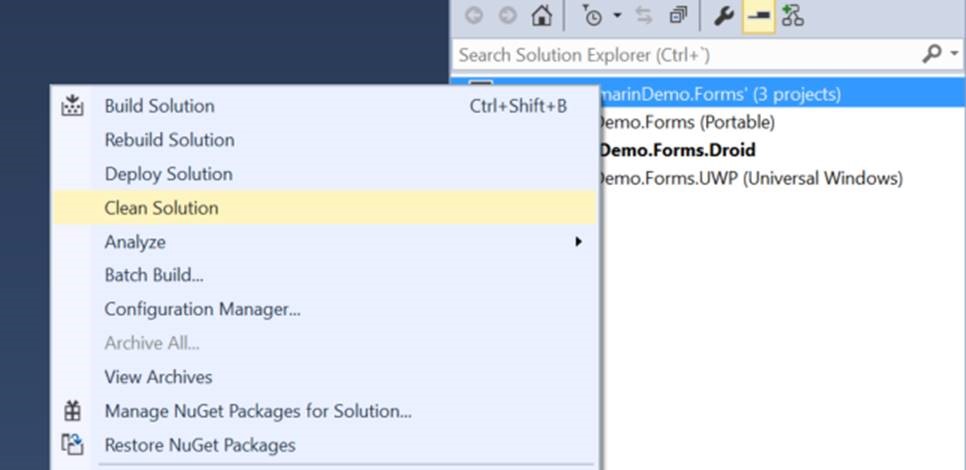
Un Clean soluciona muchos problemas
La opción de Clean nos sirve para borrar las variables que ha utilizado el Visual Studio al hacer la compilación. Si hubiese archivos en el directorio al que se dirige cuando compila (/bin y objetos), estos no se van a borrar, a no ser que hagamos un clean.
Por tanto, ante un error de este tipo:
Build action 'EmbeddedResource' is not supported by one or more of the project's targets.
C:\Users\daorti\Microsoft\OneDrive - Microsoft\Charlas\Academic Tour\Xamarin\4_Xamarin_Forms\XamarinDemo.Forms\XamarinDemo.Forms\MainPage.xaml 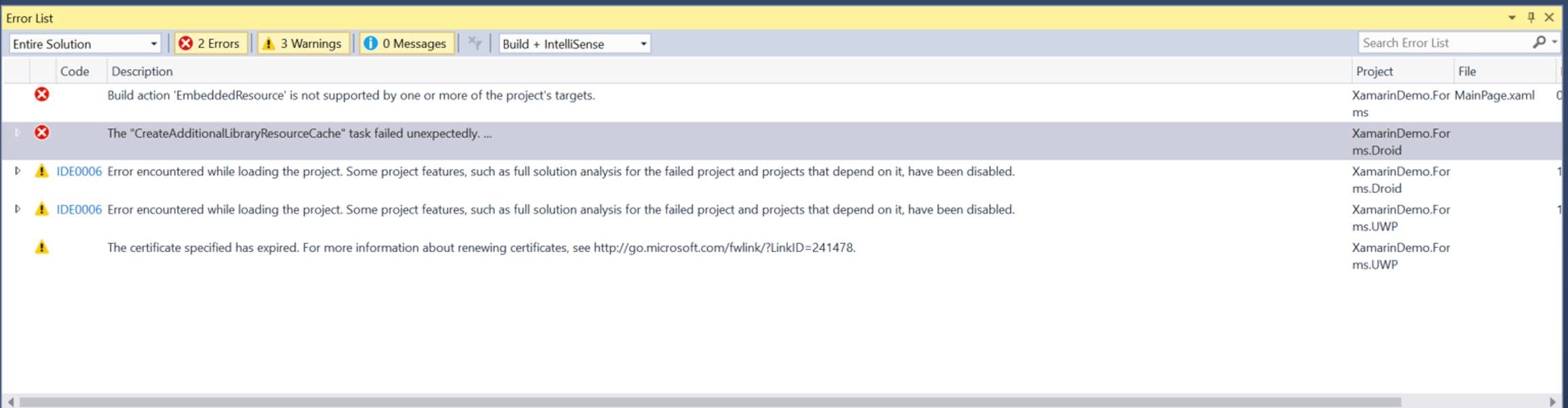
Lo mejor es hacer un Clean desde el Solution Explorer.
Evitar rutas largas
Muchas veces surge este tipo de problema con Xamarin. Seguramente se solucione en la siguiente release, pero hasta entonces, lo ideal es almacenar nuestro proyecto en rutas cortas. Por ejemplo en C:/ . Este sería el típico error que nos salta cuando tenemos este problema:
The "CreateAdditionalLibraryResourceCache" task failed unexpectedly.System.IO.PathTooLongException: The specified path, file name, or both are too long. The fully qualified file name must be less than 260 characters, and the directory name must be less than 248 characters. at System.IO.Path.LegacyNormalizePath(String path, Boolean fullCheck, Int32 maxPathLength, Boolean expandShortPaths) at System.IO.Path.NormalizePath(String path, Boolean fullCheck, Int32 maxPathLength, Boolean expandShortPaths) at System.IO.Path.InternalGetDirectoryName(String path) at Xamarin.Android.Tools.Files.CopyIfChanged(String source, String destination) at Xamarin.Android.Tasks.CreateAdditionalLibraryResourceCache.Execute() at Microsoft.Build.BackEnd.TaskExecutionHost.Microsoft.Build.BackEnd.ITaskExecutionHost.Execute() at Microsoft.Build.BackEnd.TaskBuilder.<ExecuteInstantiatedTask>d__26.MoveNext()
Si no hemos creado el Proyecto en una ruta corta, sino que lo estamos moviendo desde una larga, lo recomendable al reabrir el proyecto es hacer un Clean antes de recompilar de nuevo.
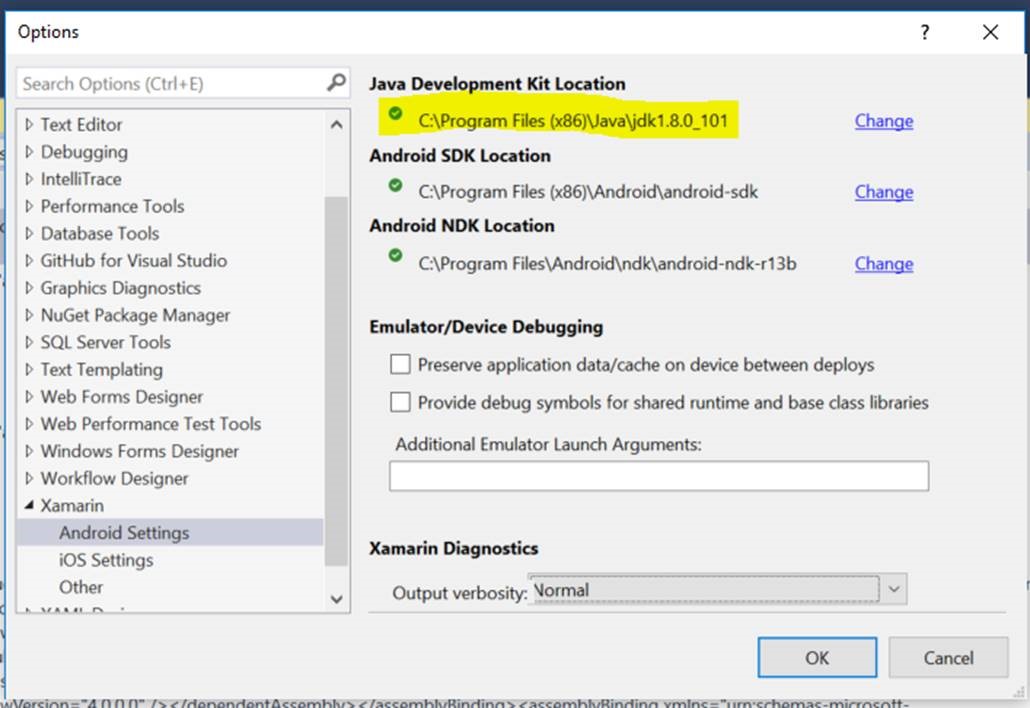
Configuración del JDK de Java
Es posible que tengamos problemas con el JDK de Java o bien que no lo tengamos descargado o que la versión no es la última. Si se diese la ocasión, podríamos tener este tipo de error:
java.lang.UnsupportedClassVersionError: com/android/dx/command/Main : Unsupported major.minor version 52.0
En tal caso, hay que dirigirse a la web de Oracle y descargar la última versión de Java. A continuación, tienes que indicarle al Visual Studio dónde está el JDK, desde Tools – Options – Xamarin. Una vez configurado, debería aparecerte un tick verde:
Configuración del MAC
Aunque en el vídeo de instalación se muestran unas pequeñas pinceladas de cómo ejecutar la aplicación en iOS, en este apartado veremos los pasos necesarios para poder compilar este proyecto:
- Conectamos tanto el equipo Windows donde estemos desarrollando en Xamarin como el MAC a la misma red. No hace falta que estén físicamente en la misma LAN, ya que si ambos ordenadores pertenecen a la misma VPN, podréis acceder al MAC de manera remota.
- En segundo lugar, hay que instalar en el MAC el xcode y Xamarin Studio .
- Asegúrate de tener actualizados tanto el Xamarin de Visual Studio como el Xamarin Studio del Mac.
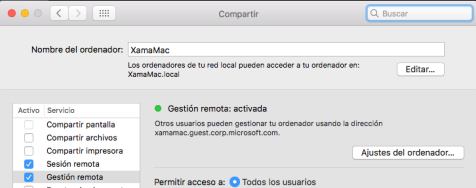
- Ahora necesitaremos o bien la dirección IP del MAC (la puedes sacar con el comando ifconfig desde el terminal) o el nombre del ordenador. Para el nombre del ordenador hay que ir a Preferencias del sistema -> Compartir -> Gestión Remota -> Nombre del ordenador.
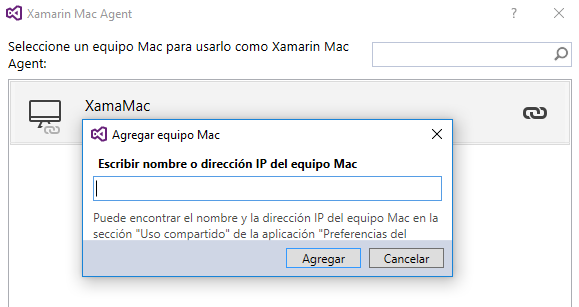
- Ya tenemos configurados ambos entornos. Lo único que queda es la comunicación. Abrimos el Mac Agent desde Visual Studio, clickamos en Agregar Equipo e introducimos el nombre del ordenador. Seleccionamos Conectar, esperamos un rato y ya tenemos Visual Studio sincronizado con nuestro MAC.
Finalmente, establecemos el de iOS como proyecto de inicio, elegimos un dispositivo iPhone y lo ejecutamos. Tras un rato, debería abrirse el emulador de iOS en el MAC y lanzarse la aplicación.
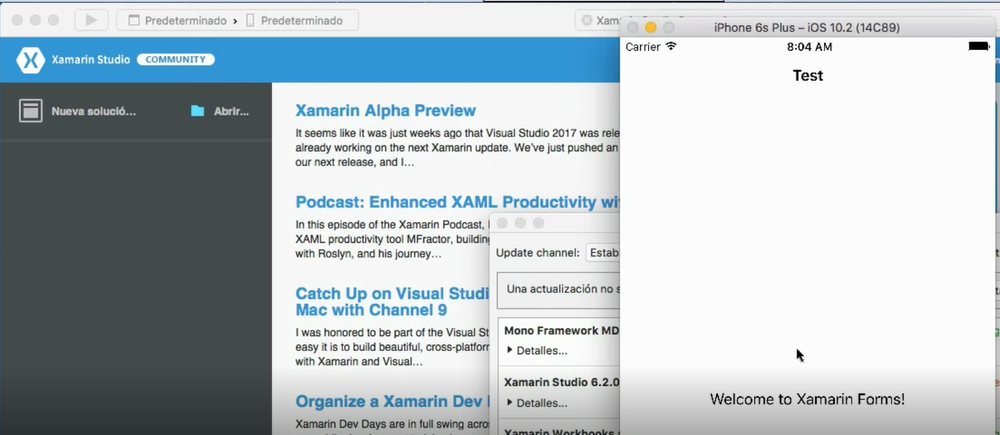
Estos son algunos de los consejos a seguir para empezar a programar con Xamarin. Procura tener todas tus herramientas actualizadas porque van saliendo mejoras cada mes.
Xamarin es una herramienta muy potente, pero requiere de paciencia ya que se compone de muchas dependencias y como haya alguna mal configurada o desactualizada vamos a perder mucho tiempo tratando de resolverlo. Merece la pena pararse un momento a pensar qué necesito instalar y por qué, ya que luego no vamos a saber por dónde vienen los fallos.
Y una vez tengamos el entorno configurado, a partir de aquí empieza lo divertido :)
Daniel Ortiz
Technical Evangelist Intern
@ortizlopez91
Hackathon Online de Xamarin #apps4good
Aplicaciones para conseguir un mundo mejor.
Seguro que hay algún problema social (o muchos) que personalmente te afecta o te preocupa. Es el momento de hacer algo con las herramientas con las que somos buenos: ¡programando!
Desde Microsoft queremos animarte a participar en el Hackathon Online que organizaremos los próximos 16, 17 y 18 de junio.
Este hackathon persigue un claro objetivo: conseguir entre todos resolver o ayudar a alguno de los problemas que nos preocupen a través de una aplicación móvil.
¿Cómo?
Paso 1: Forma parte del Hackathon online. Sólo tienes que formar parte de la iniciativa haciendo like en este grupo de Facebook.
Paso 2: Estrújate un poco el coco y saca una buena idea en forma de aplicación que ayude a los demás.
Paso 3 (la parte fácil): Crearla.
Hemos organizado este hackathon online para ayudarte con ello a través de Xamarin. Para que aprendas a desarrollar (o profundices en tus conocimientos) sobre esta plataforma que nos permite crear aplicaciones nativas para iPhone, Android y Windows 10 compartiendo código.
Paso 4: Tras el hackathon online tendréis unas semanas de margen, por si necesitaras ultimar detalles y presentar tu app después a este fantástico concurso que patrocinamos desde Microsoft: #apps4good https://www.campusmvp.es/concurso-xamarin.htm en el que puedes ganar un primer premio de 5.000€ u otros cuatro de 1000€ en metálico, cada uno.
¡¡Seguro que ya estás convencido!! ¿Quieres saber más?
El formato es el siguiente.
Antes del Hackathon
1. Toma contacto con Xamarin y resuelve dudas previas al hackathon: Nos basaremos en el Hand On Lab de Pierce Boggan, "Spent", que tiene un contenido muy organizado y completo: https://github.com/pierceboggan/spent
En él, exploraremos las características y funcionalidad de Xamarin.Forms desde una aplicación de prueba para hacer el seguimiento de los gastos.
2. Si no tienes tu entorno de Xamarin instalado, puedes ver cómo instalarlo en una máquina limpia en el siguiente video: https://channel9.msdn.com/Blogs/channel9spain/Instalacin-de-Xamarin
No lo dejes para el último día, y si surge alguna duda, escríbenos un mensaje en el foro: https://aka.ms/foroapps4good
3. Todos los recursos que necesitas puedes encontrarlos en Visual Studio Dev Essentials: https://aka.ms/dev-essentials
Durante el Hackathon
Durante tres días contaremos con los mejores expertos de desarrollo de aplicaciones móviles y Xamarin para ayudarte.
Ellos estarán pendientes de los mensajes que nos dejes en el foro de desarrollo en Xamarin.
"No sé Xamarin" no es una excusa: Si aún no conoces Xamarin, durante el primer día (viernes 16 de junio), además de la resolución de dudas a través del foro, emitiremos en directo un workshop totalmente práctico (en español). Y te permitirá dar tus primeros pasos en Xamarin.
(mira el evento que hemos creado en nuestra página de Facebook para ver la agenda del Hackathon)
En este workshop veremos una introducción a qué es Xamarin, y cómo hacer paso a paso una aplicación desde tu primer "Hola mundo".
Podréis seguir este workshop en este grupo de Facebook: https://www.facebook.com/hackathonapps4good/
A partir de este workshop tendréis los conocimientos necesarios para poder implementar tu propia aplicación.
Además, implementaremos el backend de tu aplicación móvil en Azure, veremos qué servicios de Azure nos facilitan la vida a la hora de hacer aplicaciones móviles e incluso veremos cómo hacer Integración Continua, tests y despliegues de tus aplicaciones.
Si ya tienes experiencia con Xamarin, o has hecho nuestro curso de Introducción a Xamarin y Azure de Campus MVP, simplemente céntrate en programar los tres días porque....¡rara vez tendrás la oportunidad de tener este elenco con los mejores expertos ayudándote!
Todo ello en un formato del siglo XXI: online.
Sin tener que moverte de casa, no hay desplazamiento, participar no tiene ningún coste!!! ¡todo son ventajas!
¿Te está emocionando la idea de participar tanto como nosotros estamos disfrutando organizándolo?
Porque..... contamos contigo en este hackathon online: #apps4good
El equipo de Evangelismo Técnico. Microsoft Ibérica.
@msdev_es
Integración de Azure B2C en una aplicación de Xamarin Forms utilizando MSAL
En este artículo veremos cómo crear una sencilla aplicación Xamarin Forms, que muestra cómo usar MSAL para autenticar usuarios a través de Azure Active Directory B2C y acceder a una API Web ASP.NET con el token resultante. Para obtener más información sobre Azure B2C, consulta la documentación de Azure AD B2C.
Cómo ejecutar un ejemplo simple
Para ejecutar este ejemplo necesitarás: - Visual Studio 2017 - Una conexión a Internet - Un tenant Azure AD B2C.
Si no tienes un tenant Azure AD B2C, puedes seguir las instrucciones para crear uno. Si sólo quieres ver este ejemplo, no necesitas crear tu propio tenant, ya que el proyecto viene con algunos ajustes asociados a un tenant de prueba y una aplicación; Sin embargo, es altamente recomendable que registres tu propia aplicación y pruebes los pasos de configuración a continuación.
Paso 1: clona o descarga el repositorio
Desde la línea de comandos:
git clone https://github.com/Azure-Samples/active-directory-b2c-xamarin-native.git
[OPCIONAL] Paso 2: consigue tu propio tenant Azure B2C
También puedes modificar el ejemplo para usar tu propio tenant Azure AD B2C. Primero, necesitará crear un tenant Azure AD B2C siguiendo estas instrucciones.
IMPORTANTE: si eliges realizar uno de los pasos opcionales, tienes que hacer TODOS ellos para que el ejemplo funcione como se esperaba.
[OPCIONAL] Paso 3: crea tus propias políticas
Este ejemplo utiliza tres tipos de políticas: una política de registro / inicio de sesión unificado y una directiva de edición de perfil. Crea una política de cada tipo siguiendo estas instrucciones. Puede elegir incluir tantos o tan pocos proveedores de identidad como deses.
Si ya tienes políticas existentes en tu tenant Azure AD B2C, no dudes en volver a utilizarlas. No hay necesidad de crear nuevas sólo para este ejemplo.
[OPCIONAL] Paso 4: Crea tu propia Web API
Este ejemplo llama a una API en https://fabrikamb2chello.azurewebsites.net que tiene el mismo código que el ejemplo Node.js Web API con Azure AD B2C. Necesitará su propia API o, como mínimo, tendrás que registrar una API Web con Azure AD B2C para que puedas definir los ámbitos para los que su aplicación de una única página solicitará tokens de acceso.
El registro de tu API web debe incluir la siguiente información:
- Habilitar la configuración de la aplicación web / Web API para la aplicación.
- Establecer la URL de respuesta en el valor apropiado indicado en el ejemplo o proporcionar cualquier URL si sólo está realizando el registro de api web, por ejemplo https: // myapi.
- Asegúrate de proporcionar también una URI de AppID, por ejemplo demoapi, que se utiliza para construir los scopes que están configurados en el código de la aplicación de una sola página.
- (Opcional) Una vez que se haya creado la aplicación, abre Scopes públicos de la aplicación y agrega los scopes adicionales que desees.
- Copia los valores de URI de AppID y Scopes públicos, para poder ingresarlos en el código de tu aplicación.
[OPCIONAL] Paso 5: Crea tu propia app nativa
Ahora debes registrar tu aplicación nativa en su tenant B2C, para que tenga su propio ID de aplicación. No olvides proporcionar una API de Acceso a tu API web registrada en el paso anterior.
El registro nativo de tu aplicación debe incluir la siguiente información:
- Activa la configuración Native Client para tu aplicación.
- Una vez que se haya creado la aplicación, abre la pestaña de Propiedades de la aplicación y configura la URI de redirección para tu aplicación en msal <Id de aplicación>: // auth.
- Una vez que se haya creado la aplicación, abre la pestaña de acceso a la API y agrega la API que creaste en el paso anterior.
- Copia el ID de aplicación generado para su aplicación, de modo que puedas utilizarlo en el paso siguiente.
[OPCIONAL] Paso 6: Configura el proyecto de Visual Studio con los datos de tu aplicación
- Abre la solución en Visual Studio.
- Abre el archivo UserDetailsClient \ App.cs.
- Busca la asignación para public static string Tenant y reemplaza el valor por su nombre de tenant.
- Busca la asignación de ClientID de cadena estática pública y reemplaza el valor por el ID de aplicación del paso 2.
- Busca la asignación para cada una de las políticas public static string PolicyX y reemplaza los nombres de las políticas que creaste en el paso 3.
- Busca la asignación para los ámbitos public static string [] Scopes y reemplázalos con los que creaste en el Paso 4.
[OPCIONAL] Paso 6a: Configura el proyecto en iOS con la URI de retorno de la API
- Abre el archivo UserDetailsClient.iOS \ info.plist en un editor de texto (abrirlo en Visual Studio no funcionará para este paso, ya que necesitas editar el texto)
- En los tipos de URL, sección, agrega una entrada para el esquema de autorización utilizado en su redirectUri. Xml <key> CFBundleURLSchemes </ key> <array> <string> msal [APPLICATIONID] </ string> </ array> donde [APPLICATIONID] es el identificador que copiaste en el paso 2. Guarda el archivo.
[OPCIONAL] Paso 6b: Configura el proyecto Android con la URI de retorno de la API
- Abre el UserDetailsClient.Droid \ Properties \ AndroidManifest.xml
- Agrega o modifica el elemento <application> como en el siguiente xml <application> <activity android: name = "microsoft.identity.client.BrowserTabActivity"> <action android: name = "android.intent.action. VIEW "/> <categoría android: name =" android.intent.category.DEFAULT "/> <android: name =" android.intent.category.BROWSABLE "/> <data android: scheme =" msal [APPLICATIONID] Android: host = "auth" /> </ intent-filter> </ activity> </ application> donde [APPLICATIONID] es el identificador que copiaste en el paso 2. Guarda el archivo.
Paso 7: Ejecutar el ejemplo
- Elige la plataforma en la que deseas trabajar estableciendo el proyecto de inicio en el Explorador de soluciones. Asegúrate de que la plataforma elegida esté marcada para la creación y la implementación en el Configuration Manager.
- Limpia la solución, hazle un rebuild y ejecútala.
- Haz clic en el botón de inicio de sesión en la parte inferior de la pantalla de la aplicación. El ejemplo funciona exactamente de la misma manera, independientemente del tipo de cuenta que elijas, y contará con algunas diferencias visuales en la experiencia de autenticación y consentimiento. Al acceder con éxito, la pantalla de la aplicación mostrará una información de perfil básica para el usuario autenticado y podrás ver botones que te permitirán editar tu perfil, llamar a una API y cerrar sesión.
- Cierra la aplicación y vuelve a abrirla. Verás que la aplicación conserva el acceso a la API y recupera la información de usuario de inmediato, sin necesidad de volver a iniciar sesión.
- Para salir, haz clic en el botón Cerrar sesión y confirma que pierde el acceso a la API hasta que se cierre la sesión.
Corriendo la app en el emulador
MSAL en Android requiere soporte para las pestañas personalizadas de Chrome, que muestran las indicaciones de autenticación. No todas las imágenes de los emuladores vienen con Chrome a bordo: consulta este documento para obtener instrucciones sobre cómo garantizar que tu emulador admita las funciones requeridas por MSAL.
Acerca del código
La estructura de la solución es sencilla. Toda la lógica de la aplicación y UX residen en UserDetailsClient (portable). Primitiva principal de MSAL para clientes nativos, PublicClientApplication, se inicializa como una variable estática en App.cs. En el inicio de la aplicación, la página principal intenta obtener un token sin mostrar ningún UX - sólo en caso de que un token adecuado ya esté presente en la caché de las sesiones anteriores. Este es el código que implementa esa lógica:
protected override async void OnAppearing() { UpdateSignInState(false); // Check to see if we have a User in the cache already. try { AuthenticationResult ar = await App.PCA.AcquireTokenSilentAsync(App.Scopes, GetUserByPolicy(App.PCA.Users, App.PolicySignUpSignIn), App.Authority, false); UpdateUserInfo(ar); UpdateSignInState(true); } catch (Exception) { // Doesn't matter, we go in interactive mode UpdateSignInState(false); } }
Si el intento de obtener un token falla, no hacemos nada y visualizamos la pantalla con el botón de inicio de sesión. Cuando se pulsa el botón de inicio de sesión, ejecutamos la misma lógica, pero empleando un método que muestra UX interactivo:
AuthenticationResult ar = await App.PCA.AcquireTokenAsync(App.Scopes, GetUserByPolicy(App.PCA.Users, App.PolicySignUpSignIn), App.UiParent);
El parámetro Scopes indica los permisos que la aplicación necesita para obtener acceso a los datos solicitados a través de la siguiente llamada de la API web (en este ejemplo, encapsulado en OnCallApi). El UiParent se utiliza en Android para vincular el flujo de autenticación a la actividad actual y se ignora en todas las demás plataformas.
La lógica de salida es muy simple. En este ejemplo tenemos sólo un usuario, sin embargo estamos mostrando una lógica de salida más genérica, que puede aplicar si tienes varios usuarios simultáneos y deseas borrar toda la memoria caché.
Csharp foreach (usuario var en App.PCA.Users) {App.PCA.Remove (usuario); }
Consideraciones especiales para Android
Los proyectos específicos de la plataforma requieren sólo un par de líneas adicionales para adaptarse a las diferencias de plataforma individuales.
UserDetailsClient.Droid requiere dos líneas adicionales en el archivo MainActivity.cs. En OnActivityResult, necesitamos agregar:
AuthenticationContinuationHelper.SetAuthenticationContinuationEventArgs(requestCode, resultCode, data);
Esa línea garantiza que el control vuelva a MSAL una vez que la parte interactiva del flujo de autenticación terminó.
En OnCreate, necesitamos agregar la siguiente asignación: csharp App.UiParent = new UIParent (Xamarin.Forms.Forms.Context as Activity); Ese código asegura que los flujos de autenticación ocurran en el contexto de la actividad actual.
Consideraciones específicas para iOS
UserDetailsClient.iOS sólo requiere una línea adicional, en AppDelegate.cs. Debe asegurarse de que el handler OpenUrl tiene un aspecto similar al siguiente: csharp public override bool OpenUrl (aplicación UIApplication, URL NSUrl, opciones NSDictionary) {AuthenticationContinuationHelper.SetAuthenticationContinuationEventArgs (url, ""); Devuelve verdadero; } Una vez más, esta lógica está destinada a asegurar que una vez que la parte interactiva del flujo de autenticación se concluye, el flujo vuelve a MSAL.
Para más información sobre Azure B2C, consulta la documentación oficial.
Más ejemplos de Jean-Marc Prieur
Extending the Azure AD directory schema with custom properties Calling the Azure AD Graph API in a web application Integrating a Windows Universal application with Azure AD Integrating Azure AD into a Windows desktop application Calling web APIs in a daemon or long-running process
Daniel Ortiz López
Technical Evangelist Intern
@ortizlopez91
Invisible o desaparece (comunicándonos con las nubes)
Si has seguido los últimos tres post, seguramente has llegado aquí con una sed de información: ¿cómo conecto mi Intel Edison (o cualquier otra plataforma hardware) a la nube?
En Azure hay n montón, pero un montón (y cada vez más) de servicios que nos ayudan con todos los temas relacionados con IoT. No sólo para comunicaciones, sino que también almacenamos datos, los analizamos, los representamos y podemos conseguir transformar esa información en conocimiento que nos ayude a la toma de decisiones.
El esquema es antiguo, claro. Se hace obsoleto cada pocos meses.
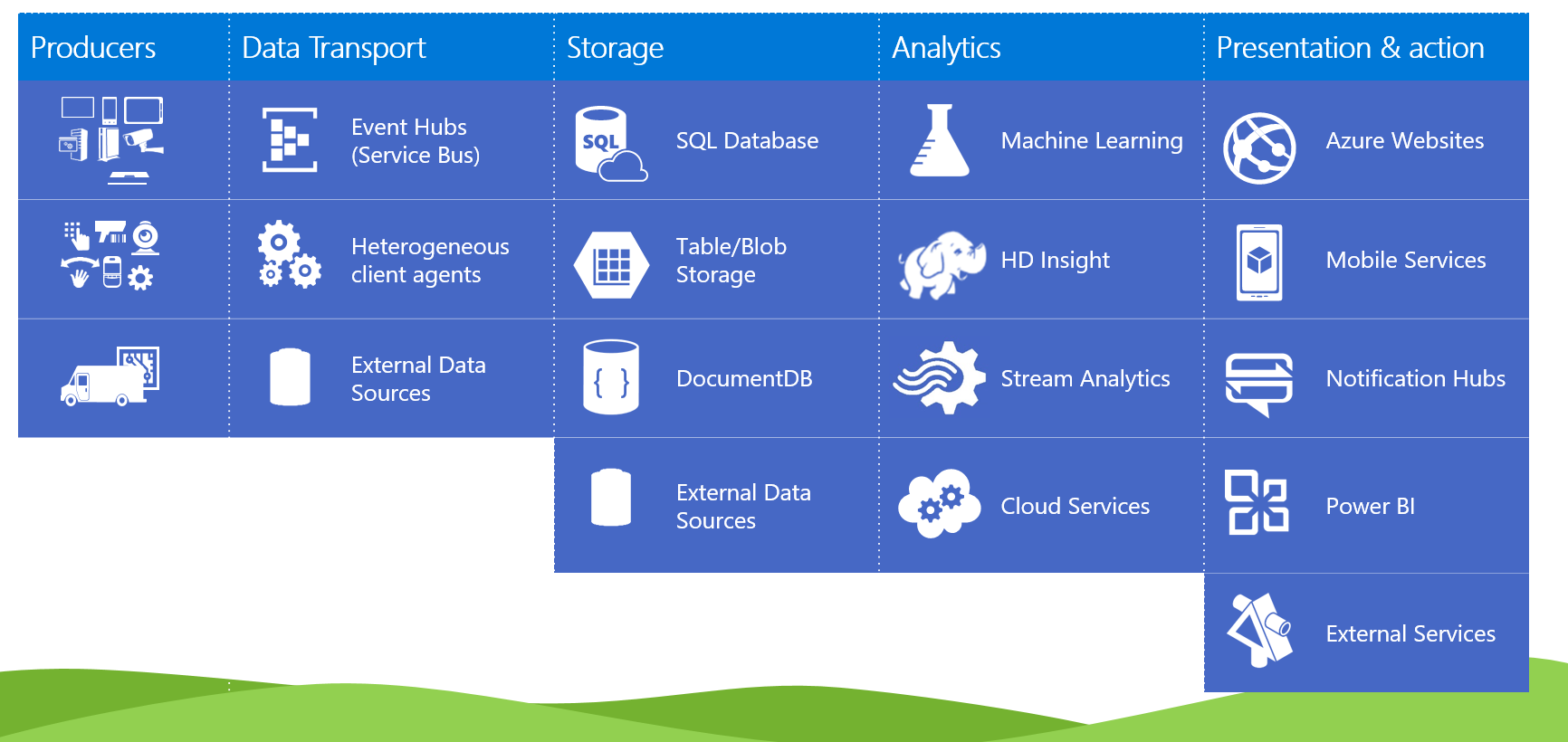
Pero a nosotras en concreto lo que queríamos es algo tan sencillo como enviar un dato a través de cualquier canal desde el WebJob, y que le llegara a la placa. Una cola, una pila, o cualquier estructura podría habernos servido.
Pero nosotras nos decidimos por un IoT Hub: ¿demasiado potente para el objetivo que necesitábamos? Nunca es demasiado, pero... muchísimo más sencillo de utilizar.
Un IoT Hub es un mecanismo que nos permite enviar y recibir información de los dispositivos que manejamos a la nube, a la vez que gestionar cada dispositivo por separado.
//normalmente en IoT los dispositivos generan datos y se están enviando a través de este tipo de servicios de comunicación. En este caso, en nuestro proyecto lo queremos invertir: será un proceso quien le envíe información al dispositivo físico, así que la comunicación bidireccional natural del IoT Hub nos ayuda en este sentido.
Un IoT Hub nos permite mantener la seguridad de los dispositivos por separado (si estuviéramos manejando cientos de ellos, y todos se comunicaran a través del mismo IoT y nos robaran uno de ellos, no se comprometería la seguridad del resto) y además utiliza los estándares de comunicación (AMQP, HTTP, MQTT...), pero también podríamos usar los nuestros propios.
El uso que le damos al IoT Hub es nuestro proyecto es básico, sencillo. Pero verás que muy poquitas líneas de código son suficientes para completar esta arquitectura:
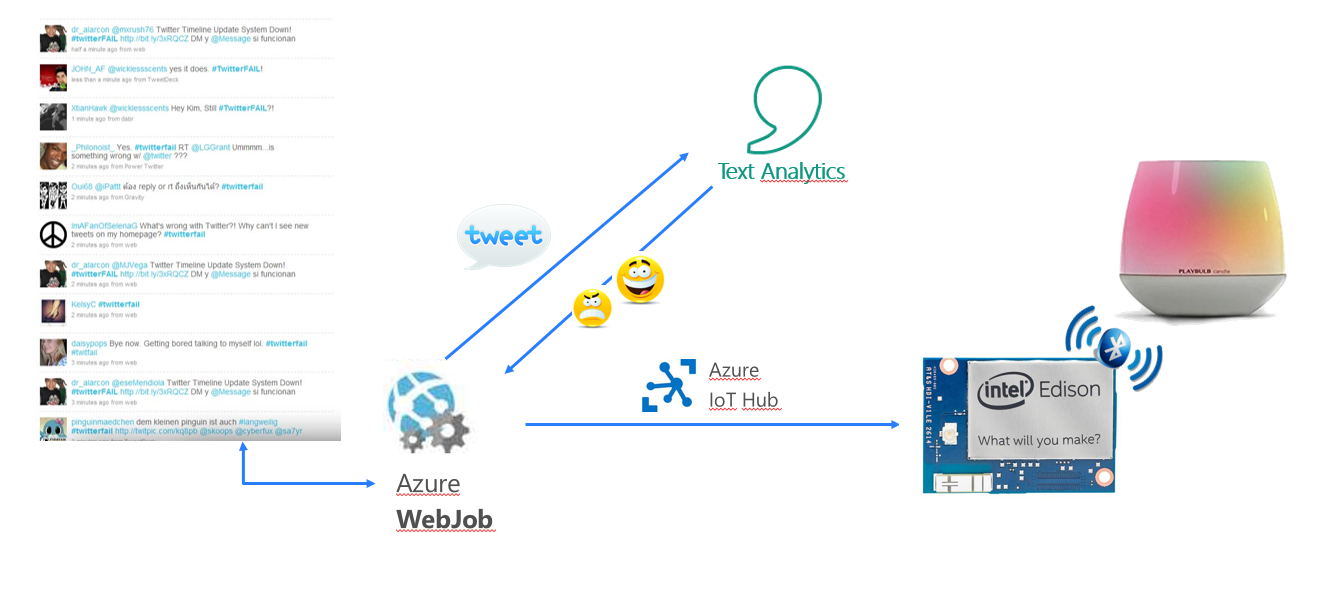
En el WebJob, que recuerda que puedes ver el código en server.js var iothub = require('azure-iothub'); var connectionString = "XXXXX"; //con. string var hubClient = iothub.Client.fromConnectionString(connectionString); //conexión
Y para enviar:
hubClient.send('Edison', color, function (err) { if (err) { console.log('Send Error: ' + err); } });
Espero que haya sido de utilidad y si tenéis alguna duda, por favor, consultad mi repositorio de GitHub, o escribidme un tuit.
Isabel Cabezas Martín
@isabelcabezasm
Technical Evangelist
(Editado) Links a todos los post de la serie:
Invisible o desaparece (El principio o cómo se nos ocurrió la idea)
Invisible o desaparece (Consumiendo la API de Twitter)
Invisible o desaparece (Interpretando los tuits)
Invisible o desaparece (el Internet de los Cacharritos)
Invisible o desaparece (comunicándonos con las nubes)
Invisible o desaparece (Consumiendo la API de Twitter)
 Empezamos a desenredar el ovillo.
Empezamos a desenredar el ovillo.
Como si de una receta se tratara, los ingredientes que entran en juego en este proyecto son:
1) Consultar los mensajes que se publican en Twitter.
2) Sistema que nos diga si un mensaje es bueno o malo
3) Aparato que conecte por bluetooth a la lámpara
4) Alguna forma de comunicar el "sistema" que nos dice si un mensaje es bueno o malo, con el "aparato" que conecta por bluetooth a la lámara.
Pues empezamos.
Consultar los mensajes que se publican en Twitter es bastante fácil, de hecho, el servicio de microblogging expone dos tipos de APIS para hacer consultas según tus necesidades: REST API y Streaming API. REST API, según la propia documentación, proporciona acceso a leer y escribir datos de Twitter, escribir un mensaje nuevo, leer los datos de un usuario y normalmente se usa autentificándose (mediante OAuth). Sin embargo, la propia documentación te recomienda: Si tu intención es monitorizar o procesar los Tweets en tiempo real, considera utilizar la Streaming API.
Utilizar una u otra es, efectivamente, una cuestión de cómo quieres enfocar el proyecto. En nuestro caso, en principio, nos gustaba más la idea de dejar la lámpara encima de la mesa, o en cualquier sitio y que se fuera iluminando en tiempo real con las opiniones.
Para tener más información sobre la utilización de la API de Twitter te aconsejo que leas la documentación oficial. Está muy bien explicado, en varios idiomas, con ejemplos, con esquemas y enlaces a bibliotecas que te pueden facilitar el trabajo en cualquier lenguaje en el que programes.
Nosotros decidimos hacer esta parte en NodeJS.
Por supuesto la elección ha sido subjetiva (no me voy a poder a discutir si ha sido la mejor, o la peor). Nosotras, en concreto, lo programamos en NodeJS por tres razones (y una de bonus):
1) Mi pasado como front-end developer, más de cinco años programando en JavaScript, hace que me sienta muy cómoda con el lenguaje.
2) Tanto si queríamos plantear una arquitectura en la que el "cacharro" que conecte con la lámpara via bluetooth sea el que haga directamente la petición a la API de Twitter, como si de un modo más elegante, queremos alojar esta parte en algún tipo de servicio que corra en background (en Azure), NodeJS será una solución que podremos reutilizar.
3) Tanto para Visual Studio como para Visual Studio Code, tenemos total integración con este lenguaje.
4) Tenemos este paquete de NPM que nos hace la interaccion con la API de Twitter (también la de Streaming) el procedimiento más sencillo del mundo.
Todo el código de la solución esta publicado en este repositorio (mío) de GitHub.
En concreto, el archivo que utiliza la API de Twitter y hace esta consulta es este: server.js
Para que no te abrumes con el código, hago una extracción de las líneas importantes:
var twitter = require('twitter'); //enlazamos el paquete npm de twitter var tweetsTopic = "LaPalabraQueQuierasBuscar"; //ya veremos cómo informar de esta palabra dinámicamente var tweetsLanguage = "es"; //"es", "en", "fr", "pt" //sólo queremos resultados en español function search() { var myJSON = { "documents": [] }; stream = client.stream('statuses/filter', { track: tweetsTopic, language: tweetsLanguage }); stream.on('data', handleTweet); //cada vez que recibimos un tuit hacemos un pequeño "tratamiento" para limpiarlo stream.on('error', function (error) { console.log('search: '+error); }); analyzeTweets(); //nos encargaremos más adelante de saber qué hace esta función exactamente (analiza el sentimiento) }
El archivo completo con este código finalmente ha terminado en un WebJob en Azure. Un WebJob es un servicio muy sencillito que nos permite ejecutar tareas en segundo plano dentro de una Web Application.
Como ves en la documentación, crear un WebJob es muy asequible, tan sólo hay que añadir uno nuevo y subir el código dentro de un fichero .zip que puede contener cualquier tipo de script. Nuestro fichero .zip también está subido en github, por si quieres ver la estructura del mismo. (package.zip)
 Conectar mi Azure WebJob con algún dispositivo no es algo que nos preocupara seriamente: tenemos muchos servicios IoT en Azure, o a las malas, comunicarse con algún otro mecanismo no va a resultar muy complicado.
Conectar mi Azure WebJob con algún dispositivo no es algo que nos preocupara seriamente: tenemos muchos servicios IoT en Azure, o a las malas, comunicarse con algún otro mecanismo no va a resultar muy complicado.
Lo que a estas alturas nos resultaba un verdadero reto es: ¿cómo conseguimos saber si los mensajes de los tuits son buenos o malos?
¡No te pierdas el próximo post!
Isabel Cabezas
@isabelcabezasm
Technical Evangelist
(Editado) Links a todos los post de la serie:
Invisible o desaparece (El principio o cómo se nos ocurrió la idea)
Invisible o desaparece (Consumiendo la API de Twitter)
Invisible o desaparece (Interpretando los tuits)
Invisible o desaparece (el Internet de los Cacharritos)
Invisible o desaparece (comunicándonos con las nubes)
Invisible o desaparece... (el Internet de los Cacharritos)
Parece mentira todos los cachivaches que somos capaces de conectar a Internet. Hace poco quise añadir mi báscula con WiFi a la red de casa (que está filtrada con MAC) y me encontré diecisiete dispositivos conectados. (Y tú estás pensando: si conectaste la báscula, pocos me parecen).
 Y es que el Internet de las Cosas, si es que la palabra "cosa" referido a "algo" se considerara medianamente respetable, se está convirtiendo en el "Internet de los Cacharritos": no hay cosas que más nos guste que un cachivache que se conecte a la WiFi: las luces, el termostato, interruptores, enchufes, la webcam de video vigilancia, la lavadora o el frigo, un espejo, la cámara de fotos, los sensores que monitorizan la presión que hay dentro de mi casa y por supuesto... la humedad de mis macetas!
Y es que el Internet de las Cosas, si es que la palabra "cosa" referido a "algo" se considerara medianamente respetable, se está convirtiendo en el "Internet de los Cacharritos": no hay cosas que más nos guste que un cachivache que se conecte a la WiFi: las luces, el termostato, interruptores, enchufes, la webcam de video vigilancia, la lavadora o el frigo, un espejo, la cámara de fotos, los sensores que monitorizan la presión que hay dentro de mi casa y por supuesto... la humedad de mis macetas!

Tengo el honor (o la poca vergüenza) de decir que he utilizado varios modelos de Arduino (uno, mini, nano, lilypad...), alguna Raspberry Pi 2, varias placas de Intel como Galileo 1 y 2, Joule (en un Hackthon que organizó Intel en la última edición del IoT World Congress) y Edison.
Creo que sería muy interesante comparar estas placas de desarrollo (y muchas más que hay en el mercado - #NoMeDaLaVida-) porque muchas veces termino usando una placa con muchísimas más características de las necesarias (y mucho más caras), cuando una mucho más simple me podría solucionar la necesidad de ese momento.
No te quiero influir sobre la placa que he elegido para conectarla a la lámpara, de hecho, tanto es así que hemos hecho el proyecto para dos versiones:
Yo he utilizado la Intel Edison, mientras que Juliet ha hecho exactamente lo mismo, utilizando la Raspberry Pi 2.

En el caso de la Raspberry Pi 2, le hemos tenido que añadir dos adaptadores Bluetooth y WiFi, que la Edison trae de serie.
Empezar a usar cualquiera de las dos placas es muy sencillo. En concreto estas tienen unos talleres (Hands On Lab) en la web https://thinglabs.io/labs/ . Talleres que te explican paso por paso, de una forma sencilla, cómo desplegar código en estas placas de desarrollo y cómo utilizarlas.
Después de muchas, muchas pruebas, terminamos confeccionando este archivo.

(De momento me centraré en cómo conectar con la lámpara via Bluetooth, y luego veremos la parte de la conexión con el WebJob).
Utilizamos esta librería de Playbulb que puedes ver cómo funciona con detalle en la web que incluye la documentación.
Pero si ves el fichero que estamos usando, está en nuestro repositorio, no cogemos el original. Y es que tuvimos que hacer algunas modificaciones (que explicaremos más adelante).
Siguiendo el ejemplo de la documentación:
Como verás en nuestro democandle.js, establecemos la conexión con la lámpara: var pb = new Playbulb.PlaybulbCandle("PLAYBULB CANDLE");
Una de las modificaciones que hicimos en 'playbulb' es que nosotras escribimos el nombre de todos los dispositivos que encuentra la placa, y una pequeña traza de "connected!" cuando encuentra el que coincide con el nombre que le hemos pasado por parámetro al constructor.
pb.ready(function () { pbReady = true; } if (pbReady) { pb.setColor(1, 255, 0, 0); }
Y así de fácil es mandarle una orden, via Bluetooth, a la lámpara.
En este caso los parámetros de setColor son: la saturación del color que le estamos enviando, Red, Green, Blue. Es decir, aquí: pb.setColor(1, 255, 0, 0); la inicializamos en rojo cuando se conecta.
Claro, si le echas un vistazo al fichero democandle.js, no es tan sencillo como poner un color u otro. En realidad, el color nos lo está enviando el WebJob, a través de un servicio en Azure.
Para no perdernos, echemos un vistazo a la arquitectura con todos los elementos que hemos visto hasta ahora.
- Consumo la API de Twitter desde el Azure WebJob.
- Consulto a un Servicio Cognitivo llamado "Text Analytics" sobre el "sentiemiento" del Tuit.
- Según ese sentimiento (o más bien la media de los sentimientos de la sesión) calculo un color que enviaré a una Intel Edison (o cualquier otra placa del estilo).
- La placa, se conecta por bluetooth a la lámpara, gracias a una librería de NodeJS que hemos tenido que modificar un pelín para nuestro caso concreto y la configura de un color, según el funcionamiento que hemos explicado.
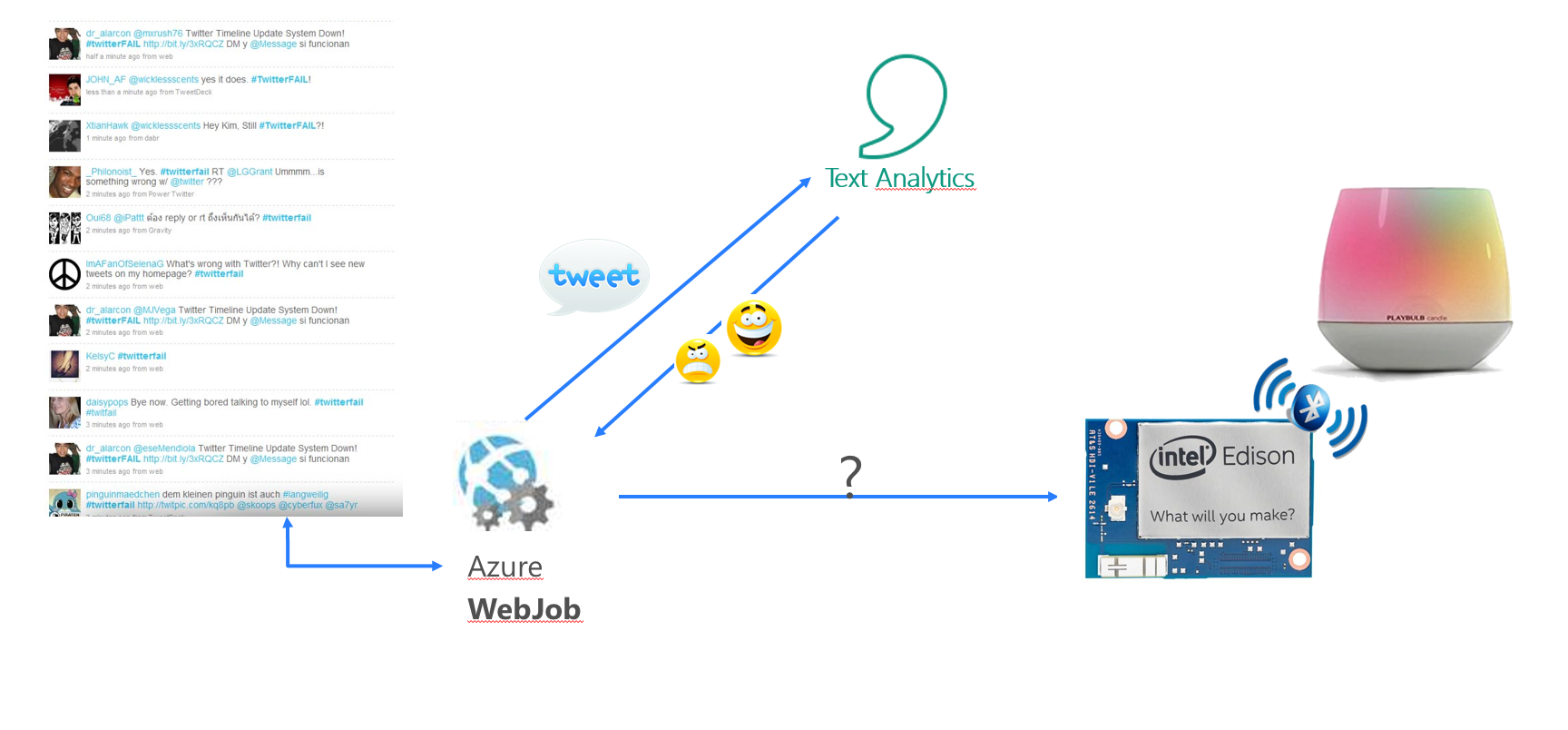
Si quieres saber cómo hemos resuelto esta comunicación (?) entre el WebJob y la placa Intel Edison, no te pierdas el próximo post.
Isabel Cabezas
@isabelcabezasm
Technical Evangelist
Invisible o desaparece (Interpretando los tuits)
Hasta ahora algunas capacidades inteligentes habían sido exclusivas de los humanos. Como interpretar el sentido de una frase, saber por la expresión de una persona si lo que le estamos diciendo le divierte, sorprende o asusta, saber si un padre se parece a su hijo, o entender que una frase como "no hay jabón" significa que "hay que comprar jabón".
Sin embargo, desde marzo del 2016, tenemos a nuestra disposición una serie de servicios que permiten humanizar nuestras aplicaciones.
Los llamados Servicios Cognitivos se agrupan en cinco categorías dependiendo de su idiosincrasia: de visión, que nos permite reconocer caras, emociones, objetos... tanto en imágenes como en videos; de voz, que habla y escucha a los usuarios, reconociendo a la persona y lo que dice; de lenguaje (escrito), que procesa textos y entiende qué necesitan los usuarios; de conocimiento, que basándose en la web, fuentes académicas o en sus propias fuentes es capaz de interpretar información, representarla, evaluarla o compararla; y de búsqueda, que usa las APis de Bing para acceder a millones de web, buscar imágenes, etc...

Como la fuente de información de la que queremos extraer resultados es twitter, nos centraremos en la categoría de "lenguaje", ya que el procesamiento de textos posiblemente nos acerque a nuestras necesidades de interpretar si un tuit es bueno o malo.
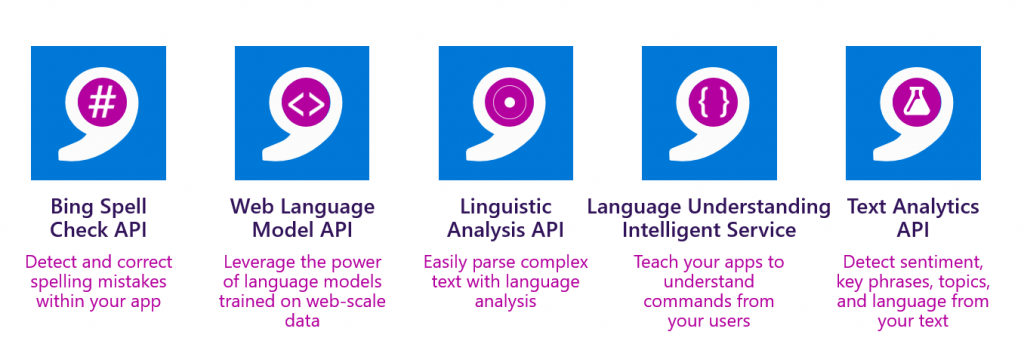
Y leyendo un poco las descripciones de casa uno de los cinco servicios disponibles para texto, rápidamente encontramos lo que estábamos buscando: la API de análisis de texto nos permite detectar el sentimiento, las palabras clave de una frase, los temas que menciona, y el idioma del texto.
Puedes hacer una prueba sobre cómo funciona esta API en esta web.
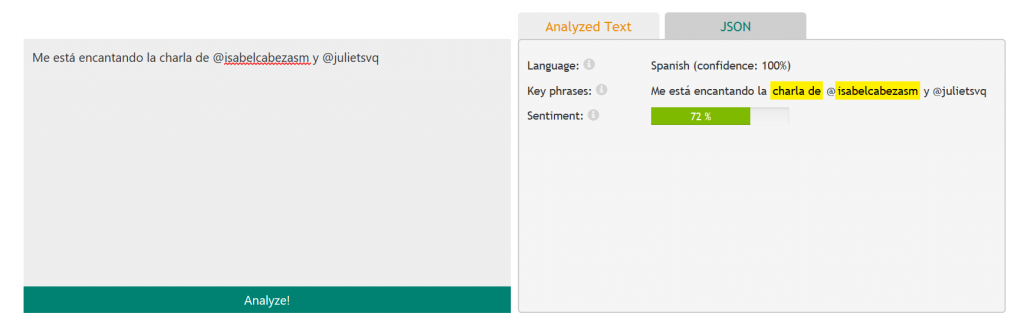
Parece evidente que el parámetro "sentiment" del resultado que devuelve el servicio es justo lo que necesitamos.
Así que, de nuevo, en el fichero que está ejecutándose en nuestro WebJob, puedes ver la llamada a la API de Text Analytics y cómo aislamos el parámetro.
Para pedir la "SUBSCRIPTION_KEY" y probarlo gratuitamente puedes ir a esta página y suscribirte en unos segundos.
Este plan que permite probar gratis los servicios cognitivos es gratis, con ciertas limitaciones en cuanto al número de peticiones que hagas. Puedes ver estas limitaciones en la página de pricing.

Una vez realizada la llamada a la API con las opciones que detectamos necesarias para analizar nuestro tuit, vemos que el parámetro que nos indica el sentimiento de la frase se llama "score".

Si observas el código, no dejes que te confunda que hacemos una media ponderada, los mensajes más recientes pesan más a la hora de realizar el cálculo del sentimiento general. Tampoco cambia el color con cada mensaje, porque en caso de un uso intenso del término en twitter los cambios en la lámpara más que darnos información relevante, nos pueden marear. :)
Una vez calculado el sentiemiento, decidiremos el color que aplicamos a la lámpara:
if (sentiment > 0.6) color = green; else if (sentiment < 0.4) color = red; else color = blue;
... y ya?
Pues ahora estaría bien que la lámpara se iluminara (¿no?).
¡No te pierdas el próximo post!
Isabel Cabezas
@isabelcabezasm
Technical Evangelist
(Editado) Links a todos los post de la serie:
Invisible o desaparece (El principio o cómo se nos ocurrió la idea)
Invisible o desaparece (Consumiendo la API de Twitter)
Invisible o desaparece (Interpretando los tuits)
Invisible o desaparece (el Internet de los Cacharritos)
Invisible o desaparece (comunicándonos con las nubes)
Las máquinas virtuales también escalan
El escalado automático de soluciones IaaS suele ser complicado, pero gracias a los Virtual Machine Scale Sets vamos a ver cómo podemos crear un conjunto de máquinas virtuales que escalen automáticamente cuando necesitemos añadir potencia a nuestra aplicación. Los VMSS se pueden crear basados en un listado de imágenes de sistema que tenemos en la plataforma o bien sobre una imagen de máquina virtual personalizada. Este último tiene la ventaja de que nuestro script de arranque será mucho más sencillo y rápido, pues el trabajo de instalación y actualización ya lo tendremos hecho. En el artículo sobre Node.js en IaaS, creamos un Ubuntu 16 que incluía un servidor Node.js actualizado a la última versión y que se ejecutaba como servicio sobre una carpeta donde teníamos la aplicación. Ahora vamos a crear el conjunto de escalado sobre esta imagen y usaremos un script personalizado para descargar e instalar una versión actualizada de nuestra aplicación, de forma que no tengamos que actualizar la imagen básica tan a menudo.
IaaS y el escalado
Cuando usamos máquinas virtuales, tanto en cloud como en nuestro propio datacneter, y nuestra aplicación necesita escalar, necesitamos:
- Una imagen del sistema operativo con todo lo básico para nuestra aplicación ya instalado. Dicha imagen tiene que estar preparada para arrancar como una nueva máquina, es decir, no debe que contener valores que tienen que ser únicos, como el nombre de la máquina, opciones de usuario, etc. Esto en Windows se consigue con el comando sysprep.
- Scripts que desplieguen de forma automatizada los paquetes y aplicaciones que no vayan en la imagen base
- Un conjunto de máquinas físicas y/o virtuales donde desplegar esas imágenes
- Un balanceador de carga, que establezca qué máquinas están disponibles y dirija el tráfico en función de la carga de cada una de las VM
- Un orquestador, que gestione el despliegue de las imágenes y la actualización de las mismas
- Un conjunto de scripts que arranquen y paren las máquinas en función de las necesidades y de las métricas de uso establecidas (uso de CPU, memoria, cola de llamadas, etc.), si queremos automatizar el escalado
Todo esto puede llegar a ser bastante complicado, por suerte, hay muchos productos que nos permiten gestionar un despliegue en alta disponibilidad.
En Azure, disponemos de los conjuntos de escalado (Azure Scale Sets) que ya cuentan con muchas de las funcionalidades que necesitamos para tener nuestra aplicación en alta disponibilidad, con un escalado flexible con el que podemos añadir y quitar máquinas para ajustar el coste de nuestra solución a las necesidades reales de nuestros usuarios.
En este artículo vamos a crear un conjunto de escalado basado en una imagen personalizada de un sistema operativo, junto con un script que nos permita desplegar nuestra aplicación web cuando la actualicemos, sin necesidad de volver a generar la imagen base del sistema operativo.
Nota: si quieres hacer el mismo ejercicio que presento en este artículo necesitarás:
Imagen personalizada para el conjunto de escalado
Al usar conjuntos de escalado tenemos dos opciones:
- Usar una imagen proporcionada por la plataforma: esto nos facilitará la creación del conjunto, pero tendremos que añadir un script que instalará los elementos necesarios para que se ejecute nuestra aplicación. Esto puede ralentizar el proceso de escalado dependiendo de las necesidades de nuestra aplicación.
- Usar una imagen personalizada: podemos crear una imagen con las actualizaciones, configuraciones e instalación necesarias para ejecutar nuestra aplicación. Es lo que hicimos en el artículo anterior y vamos a utilizar como base para crear la plantilla.
Escalado horizontal automático
Si queremos que el sistema escale de forma automática, según unas métricas que vamos a proporcionar, tendremos que indicar esto en la plantilla de despliegue, pues por ahora no tenemos disponible esa configuración en el portal. Las plantillas de Azure Resource Manager nos ayudan a escribir las especificaciones de infraestructura como código, de forma que podamos repetir de forma automatizada el despliegue o actualizar uno existente. La plantilla no es más que un archivo .json que contiene esa especificación. Este archivo puede estar acompañado de un archivo de parámetros y archivos adicionales que necesiten ser desplegados con nuestra plantilla, como pueden ser scripts, imágenes u otras plantillas que hayamos anidado en nuestra plantilla principal.
Tenemos algunos ejemplos en GitHub de las plantillas más comunes y encontrarás unas cuantas sobre conjuntos de escalado, como un Ubuntu con escalado automático, o un despliegue de Windows sobre una imagen personalizada. Para editar la plantilla podemos usar cualquier editor de texto. En Visual Studio Code podemos descargar plugin que nos ayudará con la edición de las plantillas:

Y para una experiencia mucho más completa podemos usar Visual Studio, que nos permitirá crear recursos desde multitud de plantillas. En el apartado Cloud de Visual C# o Visual Basic (aunque usemos cualquier otro lenguaje), tenemos la plantilla de Azure Resource Group:

Además, Visual Studio nos proporciona un selector para añadir el esqueleto de los elementos más comunes, de forma que no tengamos que escribirlo todo desde cero. Podremos elegir entre las plantillas que ya tenemos instaladas, o las que tenemos disponibles en la cuenta oficial de Github:

Para este ejercicio, yo utilicé la plantilla Linux Virtual Machine Sale Set y luego fui extendiendo la funcionalidad.
Estructura de las plantillas
Los archivos de plantilla de ARM suelen tener una estructura similar a la siguiente, con 4 secciones principales:

Podemos ver una sección de parámetros, otra de variables, una de recursos y otra opcional con los outputs.
La sección de salida es útil cuando queremos devolver algo a un script o queremos encadenar diferentes plantillas. En nuestro caso nos devolverá el nombre DNS asignado a la IP pública del recurso, de forma que podamos lanzar un navegador sobre la página principal al acabar el despliegue:

Parámetros de la plantilla
Las plantillas de ARM sirven para que podamos repetir el mismo despliegue tantas veces como necesitemos y se pueden parametrizar de forma que podamos cambiar algunos valores. Por ejemplo, si permitimos cambiar el tamaño de la máquina virtual, podemos establecer un parámetro basado en una lista cerrada de opciones:
"parameters": { "vmSku": { "type": "string", "defaultValue": "Standard_D1", "metadata": { "description": "Size of VMs in the VM Scale Set." }, "allowedValues": [ "Standard_D1", "Standard_DS1", "Standard_D2", "Standard_DS2", "Standard_D3", "Standard_DS3", "Standard_D4", "Standard_DS4", "Standard_D11", "Standard_DS11", "Standard_D12", "Standard_DS12", "Standard_D13", "Standard_DS13", "Standard_D14", "Standard_DS14" ] },
También podemos proporcionar un tamaño mínimo o máximo del valor, e incluso si es un password evitar que se muestre mientras lo escriben:
"adminPassword": { "type": "securestring", "metadata": { "description": "Admin password on all VMs. It must be at least 12 characters in length." }, "minLength": 12 },
Para utilizar estos parámetros desde dentro de la plantilla llamaremos a la función parameters() con el nombre del parámetro:
"sku": { "name": "[parameters('vmSku')]", "tier": "Standard", "capacity": "[parameters('capacity')]" },
Variables
Además de los parámetros, podemos definir variables, que pueden estar basadas o calculadas a partir de los parámetros, de forma que no haga falta crear parámetros para todos los valores que necesitamos rellenar. Tenemos un conjunto de funciones para realizar estos cálculos.
"variables": { "vmssuniqueName": "[toLower(substring(concat(substring(parameters('vmssName'),0,6), uniqueString(resourceGroup().id)), 0, 9))]",
Construcción de la plantilla
Tras esta breve explicación de cómo funciona el sistema de plantillas, vamos a crear la plantilla de VMSS que pueda utilizar la imagen del VHD que creamos en el ejercicio anterior. Dentro de la plantilla vamos a crear todos los recursos de infraestructura que necesitará el sistema:
- Provisionado de discos para las VMs
- La red virtual donde estarán las máquinas
- Una IP pública para el balanceador de carga
- Un balanceador de carga con sus reglas de balanceo y puertos
- El conjunto de escalado automático(VMSS) que apuntará a la imagen personalizada y a un script personalizado de inicialización
- Las reglas de escalado automático
Como necesitamos un mínimo de discos ya preparados para el conjunto de escalado automático, las plantillas tienen una forma de utilizar un array de valores para crear múltiples copias, usaremos la variable "vmssStorageAccounts" que ya hemos inicializado con 5 valores diferentes:
{ "type": "Microsoft.Storage/storageAccounts", "name": "[concat(variables('vmssStorageAccounts')[copyIndex()], variables('vmssnewAccountSuffix'))]", "location": "[resourceGroup().location]", "apiVersion": "2015-06-15", "copy": { "name": "storageLoop", "count": "[variables('vmsssaCount')]" }, "properties": { "accountType": "[variables('vmssaccountType')]" } },
La red virtual de esta plantilla será muy sencilla, pues sólo tendremos una capa de front-end web, así que tendremos todas las máquinas dentro de la misma subnet:
{ "type": "Microsoft.Network/virtualNetworks", "name": "[variables('virtualNetworkName')]", "location": "[resourceGroup().location]", "apiVersion": "2016-03-30", "properties": { "addressSpace": { "addressPrefixes": [ "[variables('addressPrefix')]" ] }, "subnets": [ { "name": "[variables('subnetName')]", "properties": { "addressPrefix": "[variables('subnetPrefix')]" } } ] } },
Podéis ver que el "type" está definido como Microsoft.Network/virtualNetworks y luego utilizamos algunas variables para los prefijos de red, tanto de la red virtual como de la subred.
En el balanceador de carga, necesitamos crear una sonda ("probe") para indicarle qué puerto de las máquinas tiene que probar para saber si puede dirigir el tráfico a esa máquina:
{ "name": "[variables('httpProbeName')]", "properties": { "protocol": "Tcp", "port": 80, "intervalInSeconds": 5, "numberOfProbes": 2 } },
Luego esas sondas se configuran en la regla:
"loadBalancingRules": [ { "name": "HTTPRule", "properties": { "loadDistribution": "Default", "frontendIPConfiguration": { "id": "[variables('feIpConfigId')]" }, "backendAddressPool": { "id": "[variables('bepoolID')]" }, "protocol": "Tcp", "frontendPort": 80, "backendPort": 80, "enableFloatingIP": false, "idleTimeoutInMinutes": 5, "probe": { "id": "[concat(variables('lbId'), '/probes/', variables('httpProbeName'))]" } } },
Finalmente creamos el conjunto de escalado automático (VMSS), donde usaremos todos los elementos que hemos creado anteriormente: discos, red, balanceador, reglas y además usaremos la imagen del VHD que creamos en el ejercicio anterior. En la sección virtualMachineProfile definimos un perfil de almacenamiento donde usaremos la imagen personalizada:
"virtualMachineProfile": { "storageProfile": { "osDisk": { "name": "vmssosdisk", "caching": "ReadOnly", "createOption": "FromImage", "osType": "Linux", "image": { "uri": "[parameters('sourceImageVhdUri')]" } } }
Y más abajo encontraremos las extensiones, en este caso usaremos una extensión que nos permite ejecutar un script personalizado durante el arranque de la máquina. El script lo subiremos a un blob privado definido en la propiedades _artifactsLocation y _artifactsLocationSasToken:
"extensionProfile": { "extensions": [ { "name": "updatescriptextension", "properties": { "publisher": "Microsoft.Azure.Extensions", "type": "CustomScript", "typeHandlerVersion": "2.0", "autoUpgradeMinorVersion": true, "settings": { "fileUris": [ "[concat(parameters('_artifactsLocation'), '/scripts/', parameters('customScriptName'), parameters('_artifactsLocationSasToken'))]", "[concat(parameters('_artifactsLocation'), '/app/', parameters('appPackage'), parameters('_artifactsLocationSasToken'))]" ], "commandToExecute": "[concat('bash ',parameters('customScriptName'), ' ', variables('quote'),parameters('appPackage'),variables('quote'),' ',parameters('destinationFolder'),' ',parameters('serviceName'))]" } } } ] }
Podemos usar un script que acompaña a la plantilla que ya sube esos ficheros por nosotros, o podremos indicar en la propiedad _artifactsLocation un sitio público como una carpeta de un proyecto en GitHub.
El script puede recibir parámetros al crear la línea de comando de llamada dentro del parámetro "commandToExecute", de forma que podemos pasar valores provenientes de la plantilla, tanto de los parámetros definidos como de otros elementos usando las funciones que tenemos para ello. En este caso el script recoge algunos de los parámetros definidos y luego se usarán dentro del updateapp.sh:
# script start echo "Welcome to updateapp.sh" echo "Number of parameters was: " $# if [ $# -ne 3 ]; then echo usage: $0 {sasuri} {destination} {serviceName} exit 1 fi echo "downloading: " $1 "into " $2 update_app $1 $2 echo "restarting service " $3 restart_service $3
Despliegue de la plantilla
La plantilla se puede desplegar ejecutando desde la línea de comando o bien podemos configurarla directamente en el portal, basta abrir este enlace que desplegará en nuestro portal de Azure la plantilla que ya tenemos alojada en GitHub. En el portal se nos solicitarán algunos parámetros como el nombre del conjunto de disponibilidad. También tendremos que indicar dónde está alojada la imagen de la máquina virtual que generalizamos en el artículo anterior. Será la URL que nos da directamente el portal, aunque esté en un blob privado, pues el archivo .vhd tiene que estar en nuestra cuenta y en la misma región donde vayamos a desplegar.

Una vez desplegado, podremos abrir el navegador en la IP pública que se ha generado para comprobar que ya funciona. En la plantilla hemos creado también unas reglas de NAT en el balanceador, para poder acceder directamente a las máquinas por SSH. Para las dos primeras podremos acceder por los puertos 10022 y 10023. Una vez allí podremos ver qué ha pasado durante la instalación del script en la máquina y los logs de salida del mismo.
- En /var/log/azure/custom-script encontraremos un handler.log donde veremos qué ha pasado durante la descarga e instalación del script
- En /var/lib/waagent/custom-script/download/0 veremos qué se ha descargado y, si se ha ejecutado, los archivos stderr y stdout contendrán la salida del script.
- Y en /var/log encontraremos el waagent.log, donde también encontraremos eventos relacionados con el script:

Recursos útiles
Que la IaaS os acompañe!
@jmservera
Senior Technical Evangelist
Developer eXperience
Machine Learning para principiantes - Bonus Track: visualización de datos con PowerBI e interacción desde un bot
Si después de crear los experimentos te quedaste con ganas de más, en este ultimo capítulo veremos como exporter los datos resultantes para que puedan ser consumidos tanto desde PowerBI como desde un bot conversacional.
Lo primero que debemos hacer es cambiar el tipo de datos de la columna "Drafted" a entero, así que vamos a añadir otro modulo "Edit Metadata" y realizar esta transformación:
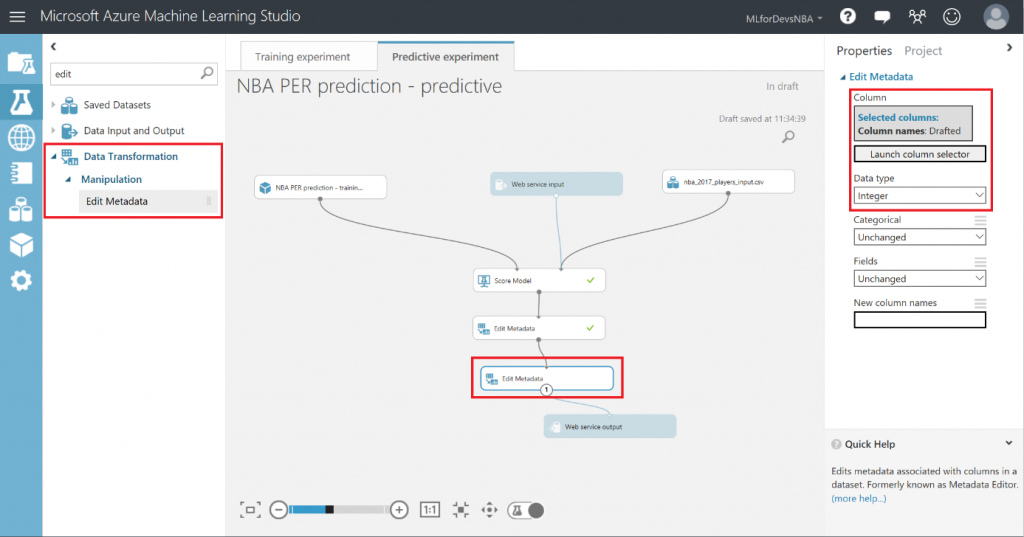
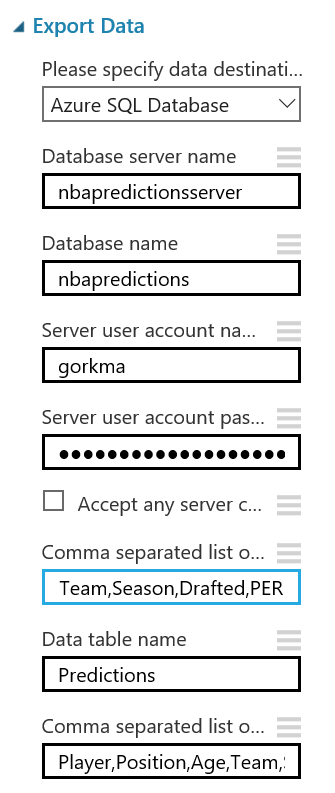
Después de esto, vamos a exportar el resultado de las predicciones a una base de datos SQL en Azure, de forma que tanto PowerBI como el bot puedan conectarse a los datos e interactuar con ellos. Para hacer esto, busca el modulo "Export Data" en el menú de la izquierda, dentro de la categoría "Data Input and Output" , arrástralo al canvas y conecta su entrada con la salida del último modulo "Edit Metadata" :
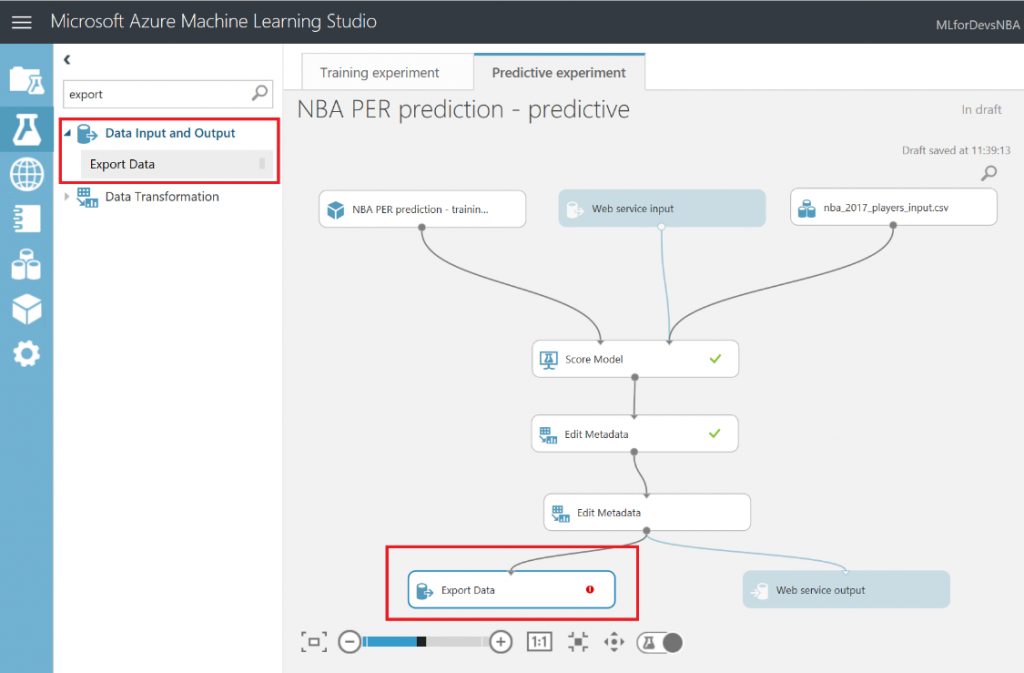
Con el modulo "Export Data" seleccionado, podrás configurar el servicio de almacenamiento en el que prefieras almacenar tus datos. En este caso, la opción elegida es una base de datos Azure SQL, que necesitarás desplegar de antemano. Si no lo has hecho nunca, en este enlace puedes encontrar un tutorial paso a paso para hacerlo. Asegúrate de incluir tu IP en la whitelist del firewall del servidor SQL, o toda consulta será rechazada.
Una vez tengas la base de datos en funcionamiento, necesitarás el nombre del servidor, el nombre de la base de datos y las credenciales del usuario para acceder a ella (todo puedes encontrarlo en el portal de Azure). Para continuar, simplemente escribe la lista (separada por comas) de columnas que se seleccionarán del dataset (en este caso: Player, Position, Age, Team, Season, Drafted, PER), indica el nombre de la tabla en la que quieres que se almacenen estos datos, y con otra lista de nombres de columnas separados por comas puedes elegir el nombre de las columnas en la base de datos (en este caso, se recomienda mantener los mismos nombres y usar la misma lista que antes):
Tras ejecutar de nuevo el experimento predictivo, todas las predicciones se almacenarán en la base de datos y estarán disponibles para que se consulten y consuman desde Power BI y cualquier otra aplicación que pueda leer desde una base de datos SQL.
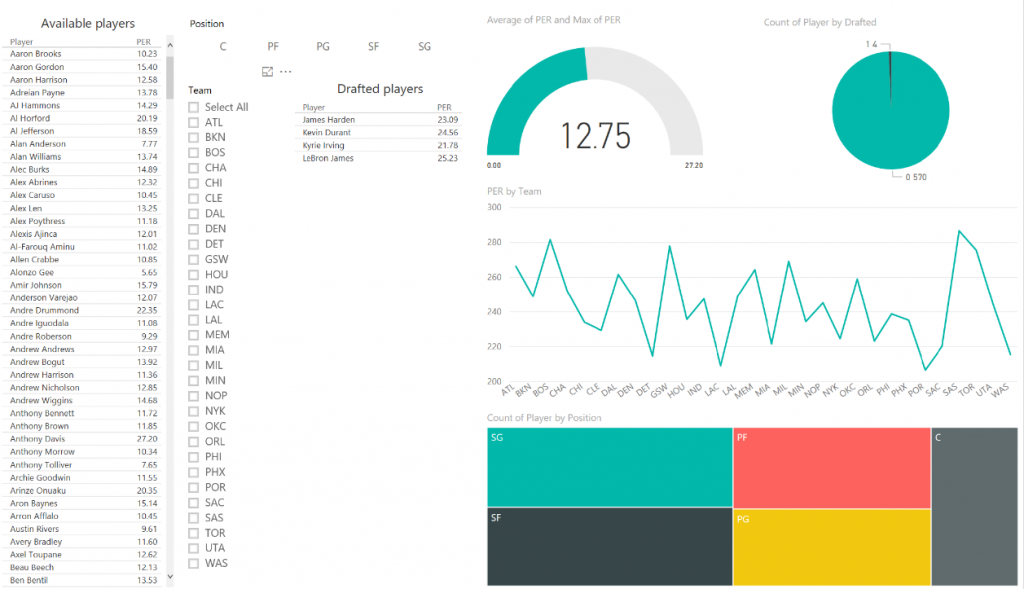
Con los datos ya almacenados, puedes seguir estos pasos para conectarse a ellos desde Power BI y comenzar a crear visualizaciones interactivas que te ayuden a interactuar con tus datos fácilmente: https://powerbi.microsoft.com/en-us/documentation/powerbi-azure-sql-database-with-direct-connect/
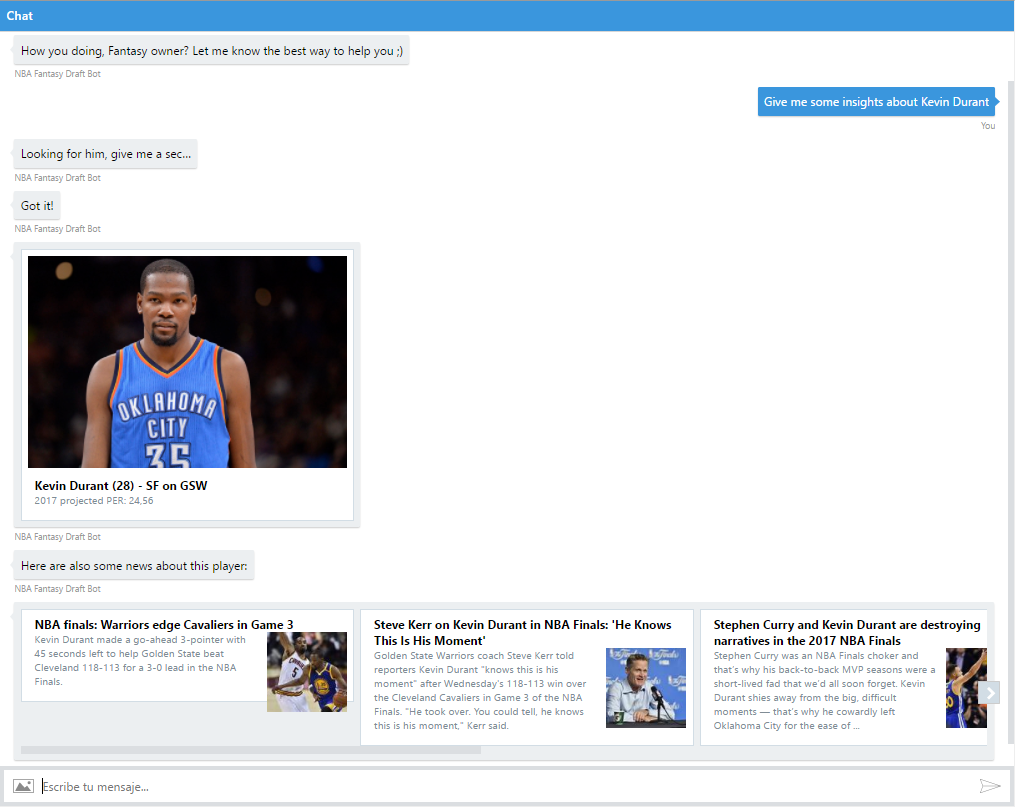
En este repo de Github (https://aka.ms/predict-nba-stats) también puedes encontrar el código de un bot que te permitirá interactuar con las predicciones almacenadas a través de una conversación real. Necesitarás, eso sí, configurar tu LUIS con diferentes intents, para que el bot pueda entender lo que se le está pidiendo (en este caso: saludo, información sobre un jugador específico por nombre, draftear un jugador, lista de los mejores jugadores disponibles y lista los mejores jugadores disponibles por posición). También puedes encontrar el bot publicado en https://aka.ms/nba-draft-bot, incluyendo tarjetas con fotos y noticias sobre los jugadores gracias a los Cognitive Services, que nos ayudan a añadir inteligencia a nuestras apps de una manera tan simple como añadir un par de peticiones HTTP:
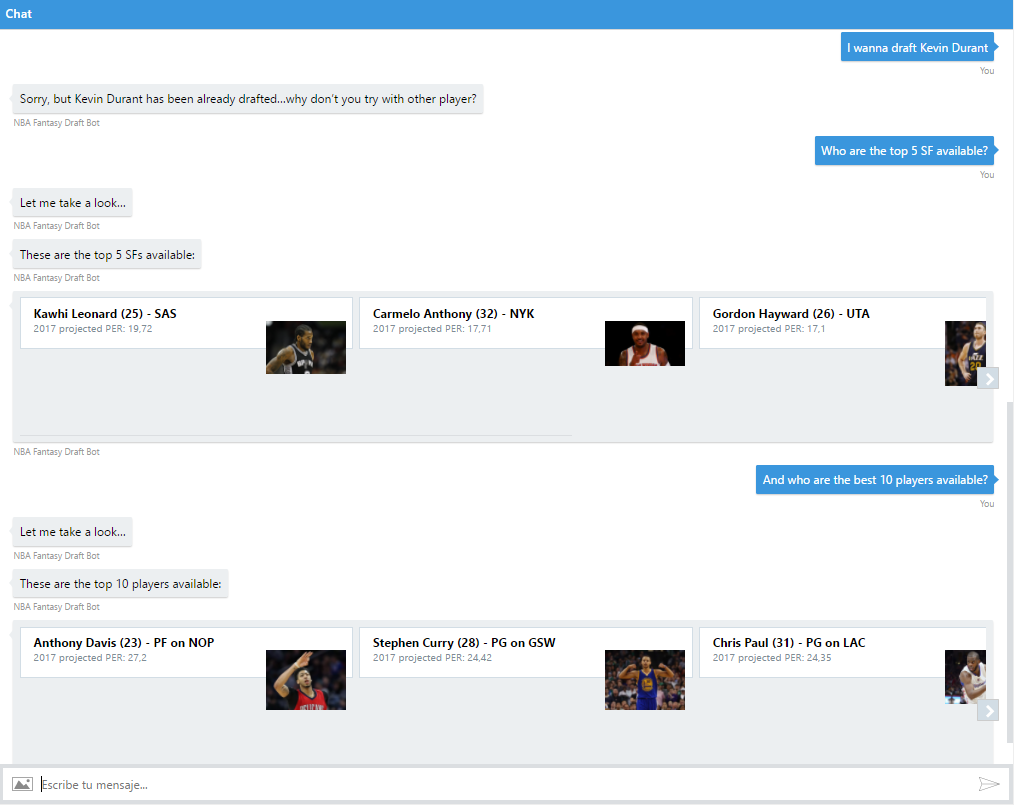
Esto es solo un ejemplo de cómo puedes interactuar fácilmente con los resultados de tus experimentos de Machine Learning y enriquecer los datos con algunas fuentes externas, ya que solo teníamos cold hard facts (números e información sobre el jugador), pero carecíamos de contexto específico sobre el jugador, que podría ayudarnos a entender el aumento/disminución en su valoración, o si deberíamos elegirlo o no debido a distintos factores (lesiones, cambios en el equipo, problemas con el entrenador o con algún compañero...). Es sólo cuestión de tener un objetivo claro en mente y encontrar los datos correctos para crear tu solución.
Como aprendizaje durante la construcción de este experimento, me quedaría con las siguientes ideas:
- Regla del 80/20: la preparación y limpieza de los datos es CLAVE en cualquier experimento de Machine Learning, y se lleva la mayor parte del tiempo empleado en ello.
- Probar diferentes enfoques y ajustes suele mejorar bastante el rendimiento del modelo, y se trata de un proceso de prueba-error (lo de llamarse "experimentos" no es casualidad) en el que cada detalle cuenta...sigue probando hasta que consigas los resultados deseados!
- El conocimiento que se tenga sobre el dominio de los datos a estudiar es crucial para determinar el éxito de una solución de Machine Learning, y no es suficiente con dominar las habilidades técnicas necesarias para crear soluciones de este estilo. Este conocimiento sobre el dominio nos ayudará a entender mejor las posibles correlaciones entre features y el impacto de los ajustes que hagamos, así como la importancia de filtrar los datos acorde a ciertos criterios, con el fin de mejorar la calidad de nuestro dataset.
Por último, algunos enlaces que pueden resultar útiles para continuar aprendiendo sobre Azure ML Studio y Data Science:
Espero que hayas disfrutado de esta serie tanto como yo creándola :)
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist
Machine Learning para principiantes - Capítulo 1: preparando el entorno
Con la analítica de datos en aumento, Machine Learning se está convirtiendo en un tema de rabiosa actualidad. La manera en que los sistemas actuales son capaces de imitar el pensamiento humano está excediendo rápidamente las capacidades humanas en muchos ámbitos, y tenemos ejemplos tan claros como partidas de ajedrez, selección de ganadores de concursos o reconocimiento de caras y expresiones en imágenes. Machine Learning es un tema difícil de abordar y saber por dónde empezar es, a menudo, el paso más difícil.
El propósito de esta serie de posts es guiarte a través de la creación de un experimento de predicción de Machine Learning muy simple usando Azure ML Studio. El escenario sería el siguiente: te estás preparando para la próxima temporada de tu NBA Fantasy League, y quieres predecir el rendimiento (Player Eficiency Rating, un valor numérico absoluto) de cada jugador, de manera que puedas elegir a los mejores jugadores para tu equipo al empezar la temporada.
Esta serie de posts contiene 7 capítulos, los primeros seis cubrirán toda la creación del experimento de Machine Learning de principio a fin, y el último será un bonus track para que puedas entender diferentes formas de interactuar con los resultados del experimento después de su finalización y cómo añadir más inteligencia a los resultados obtenidos.
Objetivos
Después de completar esta serie de posts, tendremos los siguientes resultados:
- Comprender los fundamentos de machine learning, estadística y análisis de datos
- Aprender a aplicar estos conceptos en un escenario real desde cero aprovechando las funcionalidades que nos ofrece Azure Machine Learning Studio
- Consumir los resultados de nuestros experimentos de Machine Learning de forma novedosa a través de visualizaciones de Power BI y bots conversacionales
Pre-requisitos
- Subscripción activa de Microsoft Azure (puede ser la trial gratuita: https://azure.microsoft.com/en-us/free/)
- Conocimientos muy básicos de SQL
Preparando nuestro workspace
Una vez que hayamos activado nuestra suscripción de Azure, pasamos a crear nuestro espacio de trabajo de Azure ML e iniciar sesión en la herramienta. Para ello, lo primero será crear un espacio de trabajo de Machine Learning en nuestra suscripción:
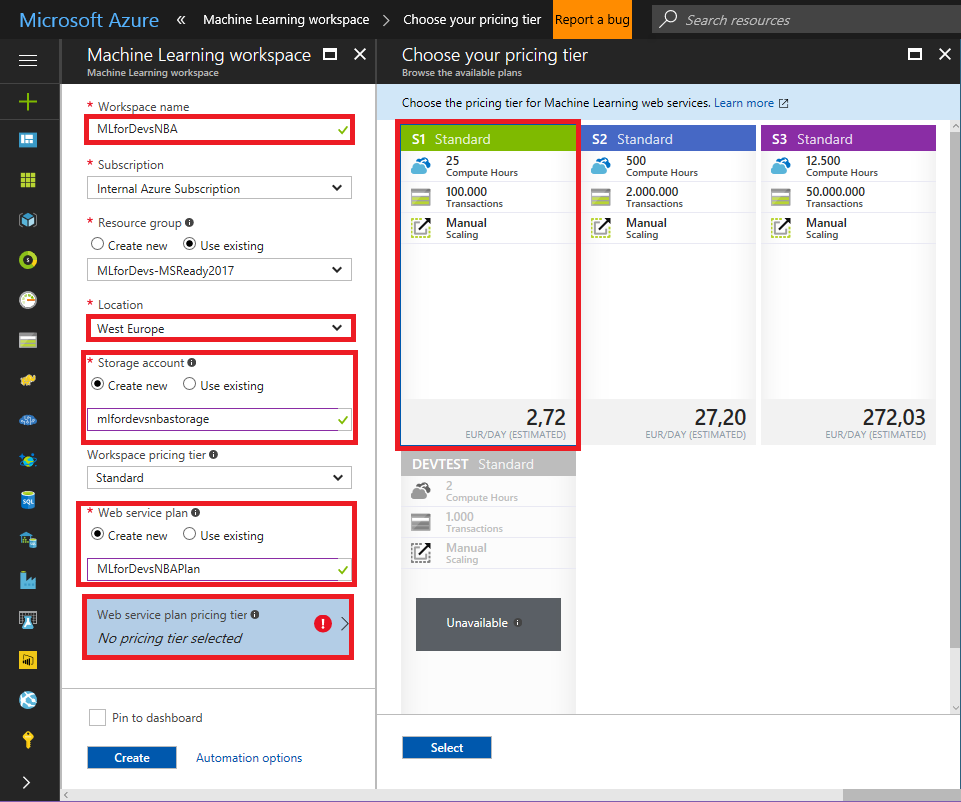
Selecciona el nombre del espacio de trabajo, la ubicación, la cuenta de almacenamiento que se va a utilizar y el nivel del plan de servicio para implementar el servicio web del experimento después de su creación:
Ahora, puedes encontrar los 3 servicios en el grupo de recursos en el que se han creado:
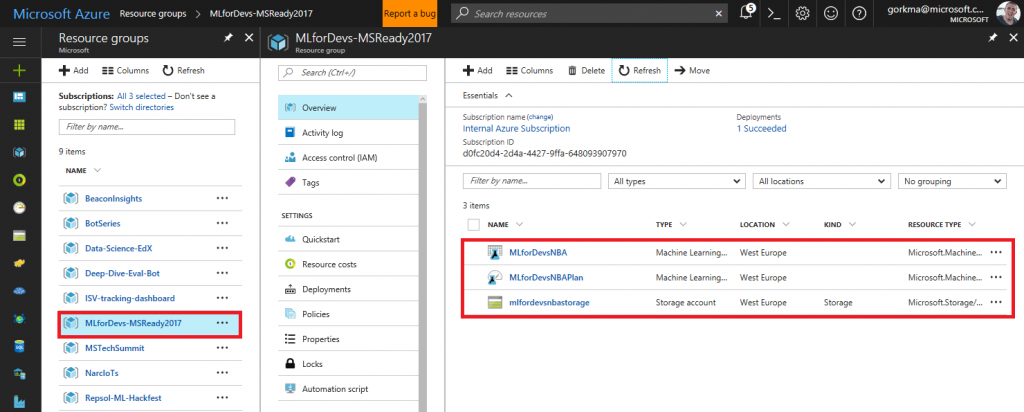
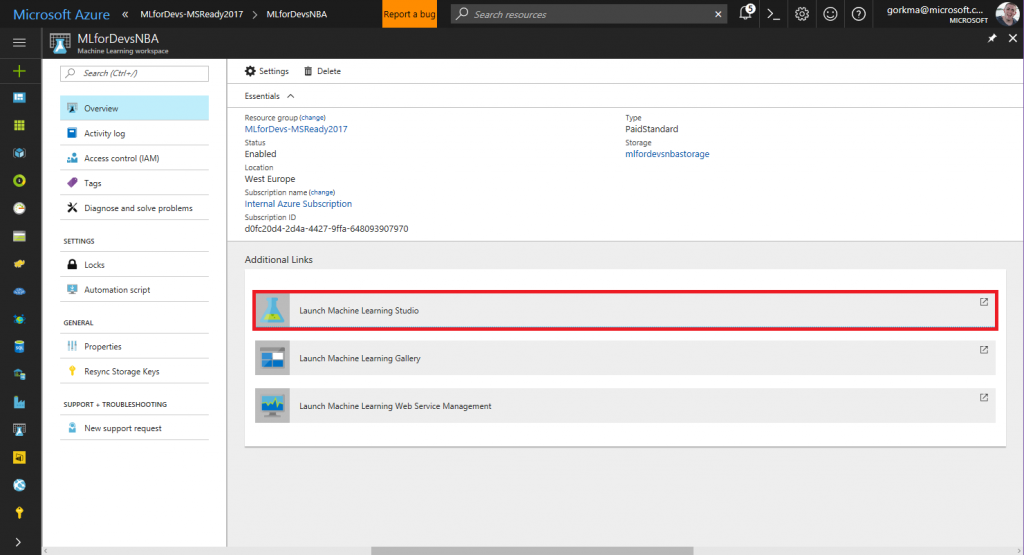
Haciendo click en el primero, que es el espacio de trabajo de Machine Learning, podrás acceder a la herramienta online pulsando en "Ejecutar Machine Learning Studio" y luego en "Sign In":
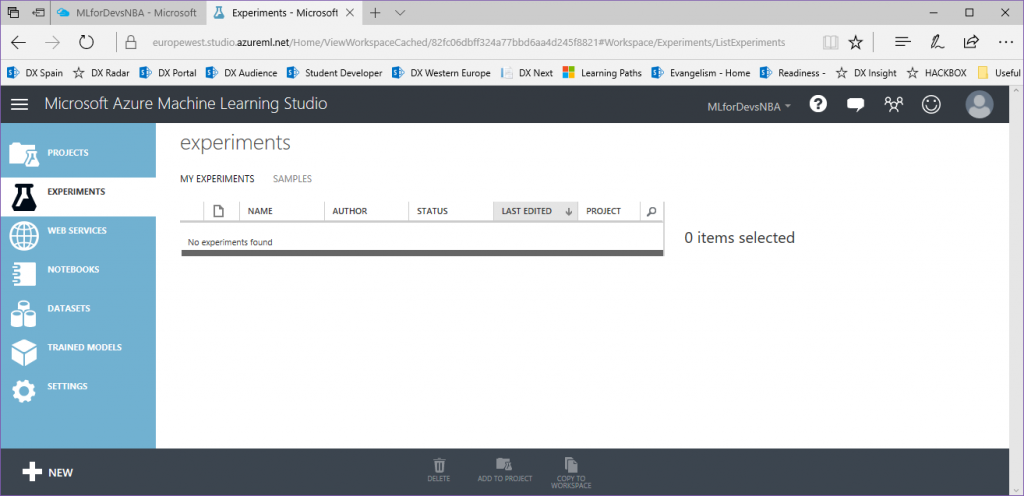
Este es el primer vistazo de Azure Machine Learning Studio, una lista vacía de experimentos. Ten en cuenta que la región que seleccionaste como ubicación para el espacio de trabajo es el inicio de la url y también puedes buscar diferentes regiones o espacios de trabajo en la barra superior:
En el próximo capítulo, dejaremos preparados nuestros datasets y los primeros módulos de nuestro experimento de aprendizaje, organizando todo en un proyecto para tener todos los recursos agrupados.
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist
Machine Learning para principiantes – Capítulo 2: creando el proyecto e importando datos
Lo primero que necesitamos para nuestro experimento son los datos que usaremos para entrenar/evaluar nuestro modelo, y los que usaremos para generar predicciones futuras con nuestro modelo entrenado. Usando la herramienta Azure ML Studio podemos importar nuestros datos de múltiples maneras (directamente desde las bases de datos SQL, DocumentDB, Azure Storage...y otras opciones de almacenamiento, usando el módulo "Import Data" de la herramienta), pero vamos a hacerlo más fácil subiendo tres archivos csv a nuestra cuenta de Azure ML:
- leagues_NBA_totals_master: archivo que contiene las estadísticas totales (puntos, asistencias, rebotes, robos, partidos jugados, minutos jugados, etc.) para cada jugador de la NBA desde 1981 hasta 2016, que será utilizado para entrenar y evaluar nuestro modelo
- leagues_NBA_advanced_master: archivo que contiene las estadísticas avanzadas (PER, porcentaje de tiros reales, porcentaje de victorias ofensivas, cuota de victorias defensivas, porcentaje de victorias totales, etc.) para cada jugador de la NBA desde 1981 hasta 2016, que será utilizado para entrenar y evaluar nuestro modelo
- nba_2017_players_input: archivo que contiene la información para cada jugador que jugó en la temporada de la NBA 2016-2017 (rookies incluidos), que se utilizará para crear las predicciones
Ten en cuenta que cada archivo CSV comparte 5 campos comunes (Player, Pos, Age, Tm y Season), que serán las características que usaremos para nuestro experimento.
Una vez descargados, vamos a cargar nuestros tres archivos en el espacio de trabajo de Azure ML:
1. Comenzamos cambiando la vista a la pestaña "Datasets" y haciendo clic en el botón "New" en la esquina inferior izquierda:
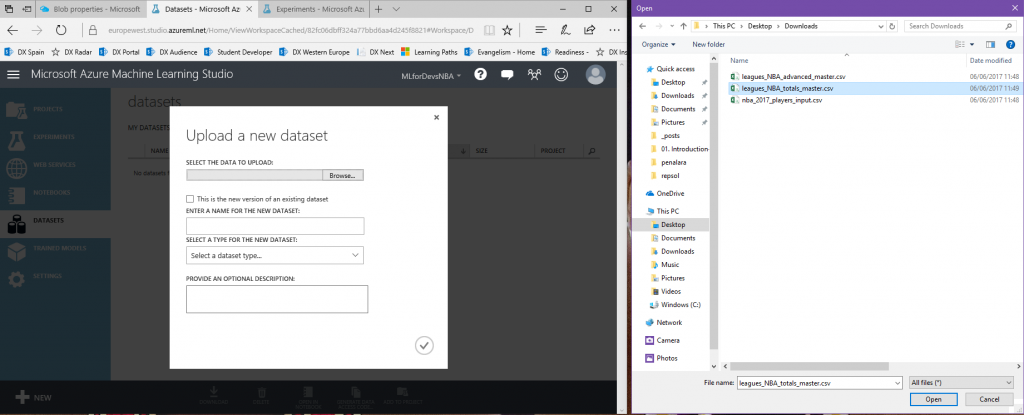
2. En el blade de "New", haz click en "From local file" y selecciona el archivo que deseas subir (repite este paso para cada archivo):
3. Una vez cargado, podemos encontrar nuestros tres archivos en la lista de "Datasets":
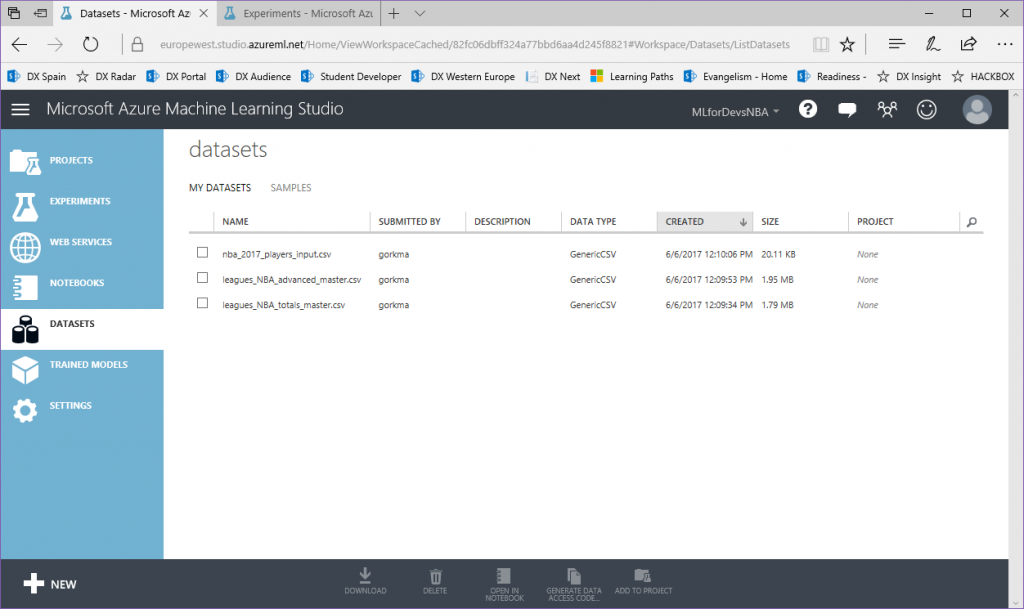
Como puedes ver, hay una columna llamada "Project" que está vacía. Los proyectos nos permiten organizar nuestros conjuntos de datos, experimentos y otros componentes agrupándolos en el mismo lugar. Vamos a crear un nuevo proyecto para añadir nuestros conjuntos de datos subidos recientemente y los experimentos que estamos a punto de crear.
1. Selecciona los 3 archivos csv y haz click en el botón "Add to project" en la barra inferior:
2. Haz click en "New project" e introduce el nombre deseado para tu proyecto:
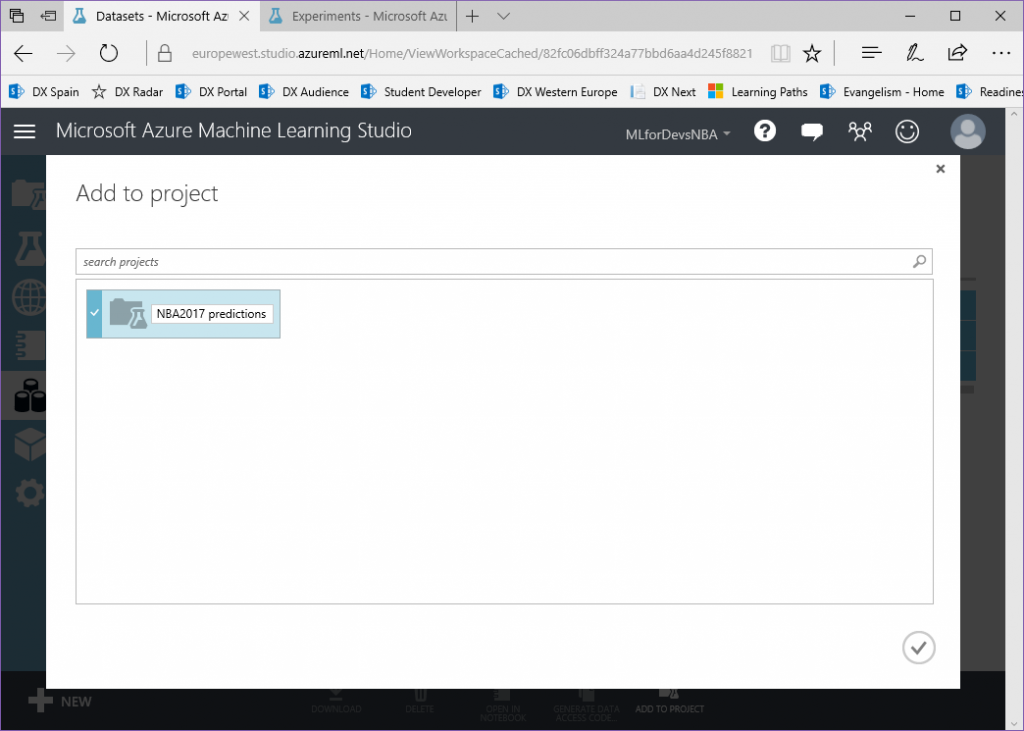
3. Puedes comprobar que el proyecto con nuestros 3 conjuntos de datos se ha creado cambiando a la vista "Projects":
Ahora, vamos a crear nuestro primer experimento, en el que definiremos el flujo para limpiar y preparar nuestros datos, y donde también vamos a entrenar a nuestro modelo para generar las predicciones para la temporada 2016-2017:
1. Cambia a la vista "Experiments" y haz click en el botón "New" en la esquina inferior izquierda:
2. En el blade de "New", selecciona "Blank experiment" para continuar:
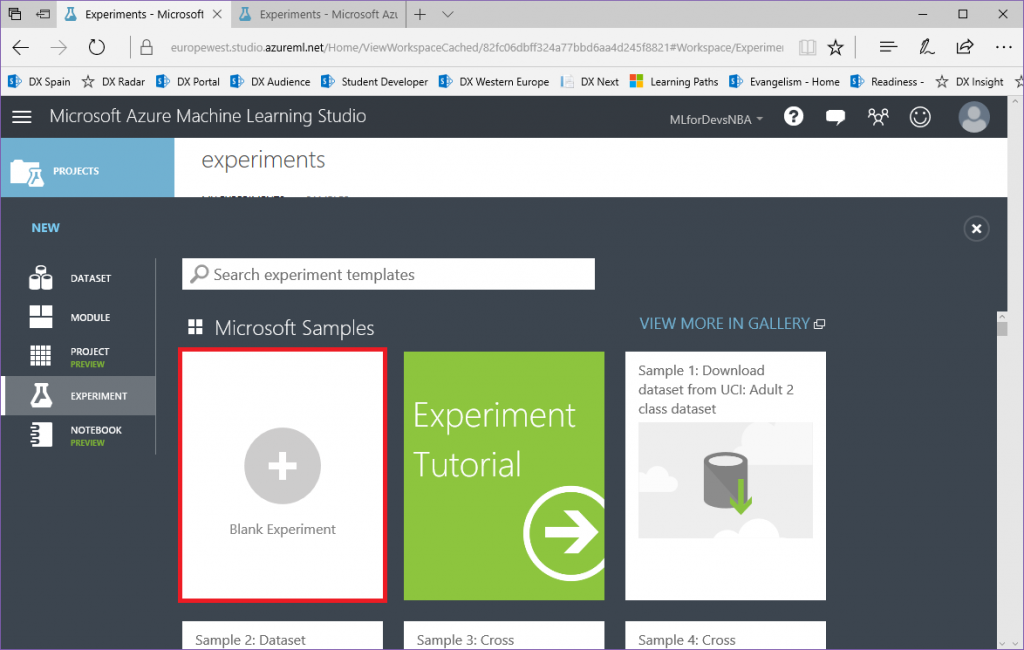
3. Una vez creado, cambie el nombre del experimento a uno menos genérico:
Como no podemos guardar un experimento sin módulos, comencemos agregando nuestros conjuntos de datos de training y uniéndolos utilizando los campos que tienen en común:
1. En la columna izquierda, tenemos la lista de los diferentes módulos que podemos utilizar en nuestros experimentos. Agrega los datasets de "totals" y "advanced" navegando por "Saved datasets > My datasets", arrastrando y soltando ambos archivos:
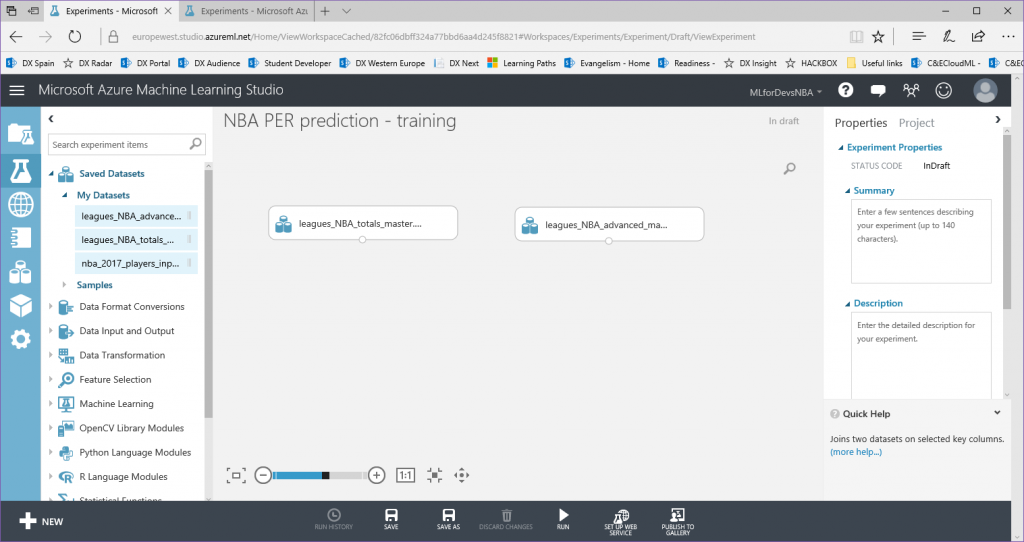
2. En la misma columna de la izquierda, busca el módulo "Join Data" y arrástralo al canvas. Una vez que lo hayas hecho, conecta los dos conjuntos de datos con el módulo "Join Data", arrastrando desde el punto inferior del conjunto de datos a la parte superior del módulo "Join Data":
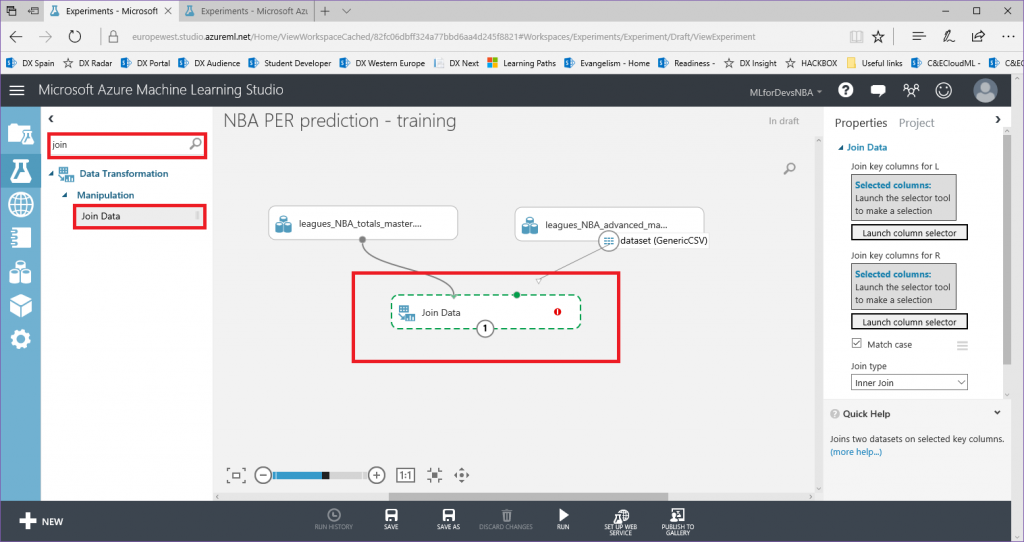
3. Con el módulo "Join Data" seleccionado, vamos a elegir las columnas comunes para unir los dos conjuntos de datos. Haz click en el selector de columnas para el primer conjunto de datos, selecciona las columnas comunes (Player, Post, Age, Tm, Season), haz click en la flecha derecha que hay entre ambas listas, y haz click en el botón ok en la parte inferior-derecha para confirmar, repitiendo el proceso para el segundo conjunto de datos:
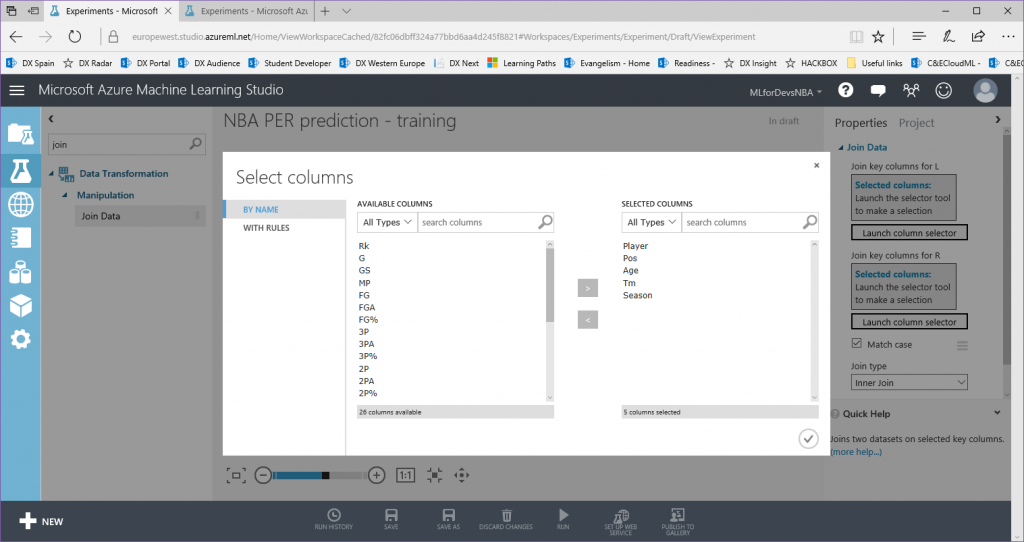
4. Para completar este paso, selecciona el tipo "Inner Join" en la lista desplegable y desmarca "Keep right key columns in combined table" para evitar columnas duplicadas en nuestro dataset unido:
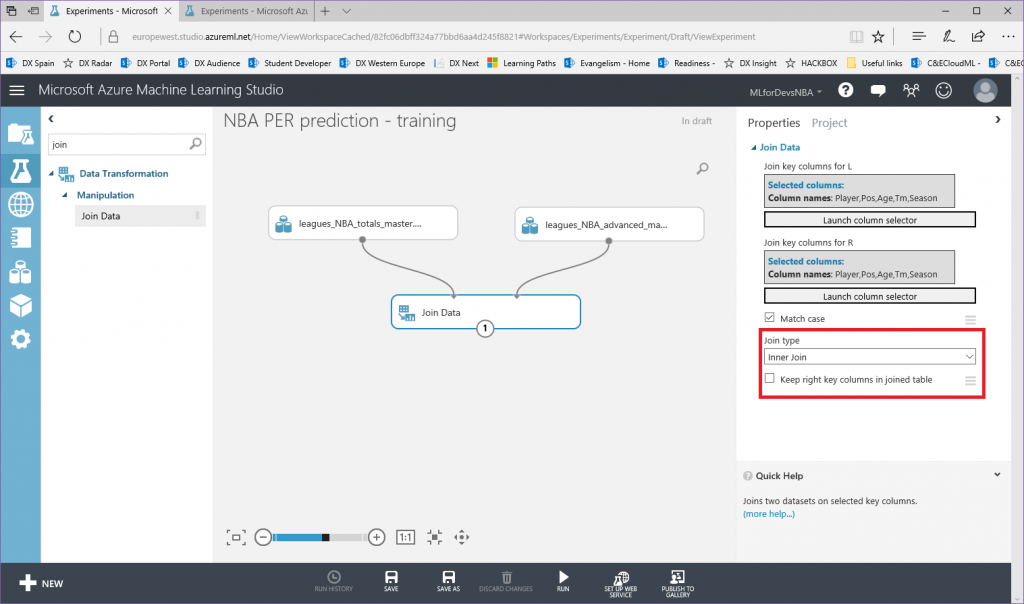
5. Puedes ejecutar el experimento (cuando se complete, aparecerá un signo de verificación verde en el módulo "Join Data") y echar un vistazo al conjunto de datos resultante haciendo click con el botón derecho en el punto inferior de "Join Data", y después "Visualize":
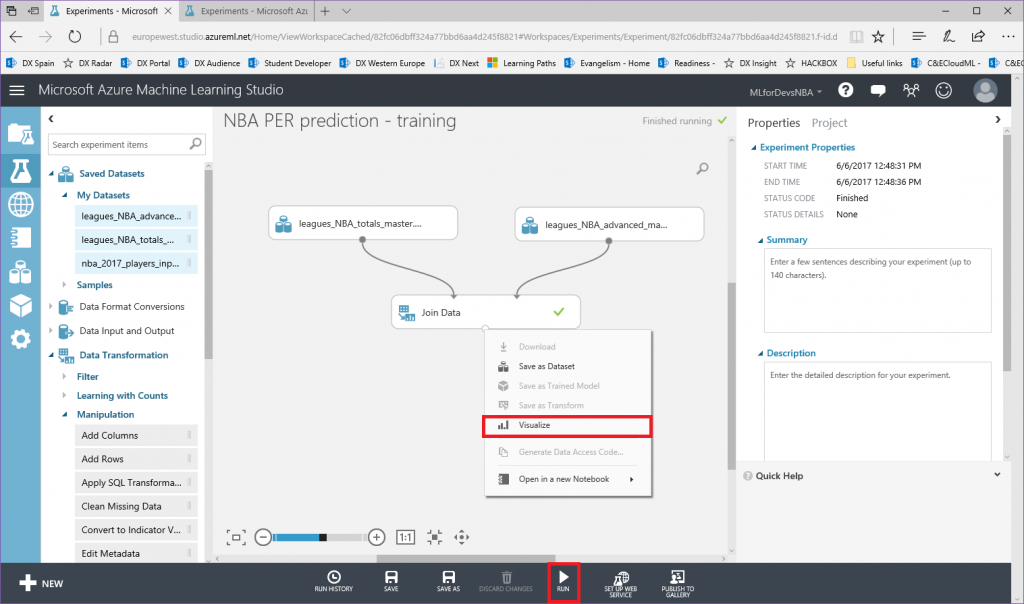
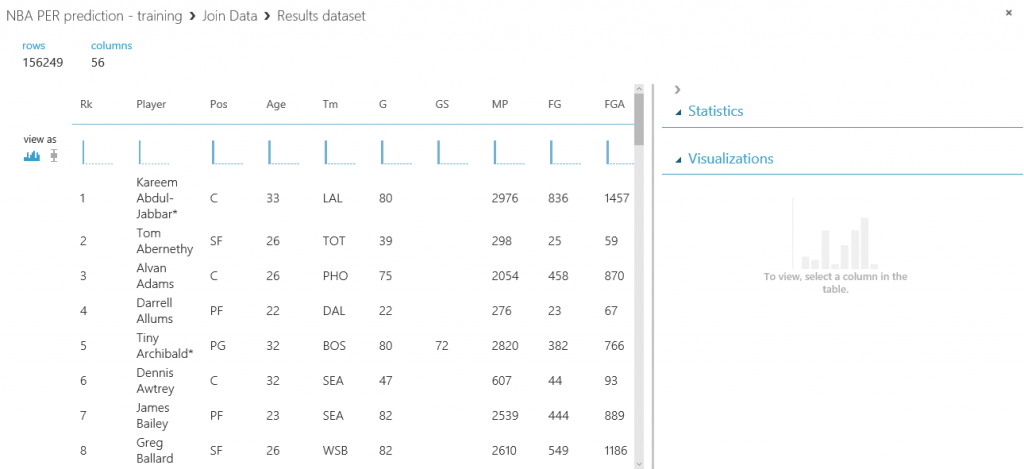
Finalmente, vamos a agregar nuestro experimento al proyecto que creamos antes, para tener todos nuestros elementos juntos:
1. Guarda el experimento (botón inferior de la barra), cambia a la vista "Projects", haz click en el proyecto creado anteriormente, y haz click en el botón "Edit" de la barra inferior:
2. En la vista de edición, abre el menú desplegable "Experiments", marca el experimento que acabamos de crear para añadirlo al proyecto, y haz click en la flecha derecha entre ambas listas:
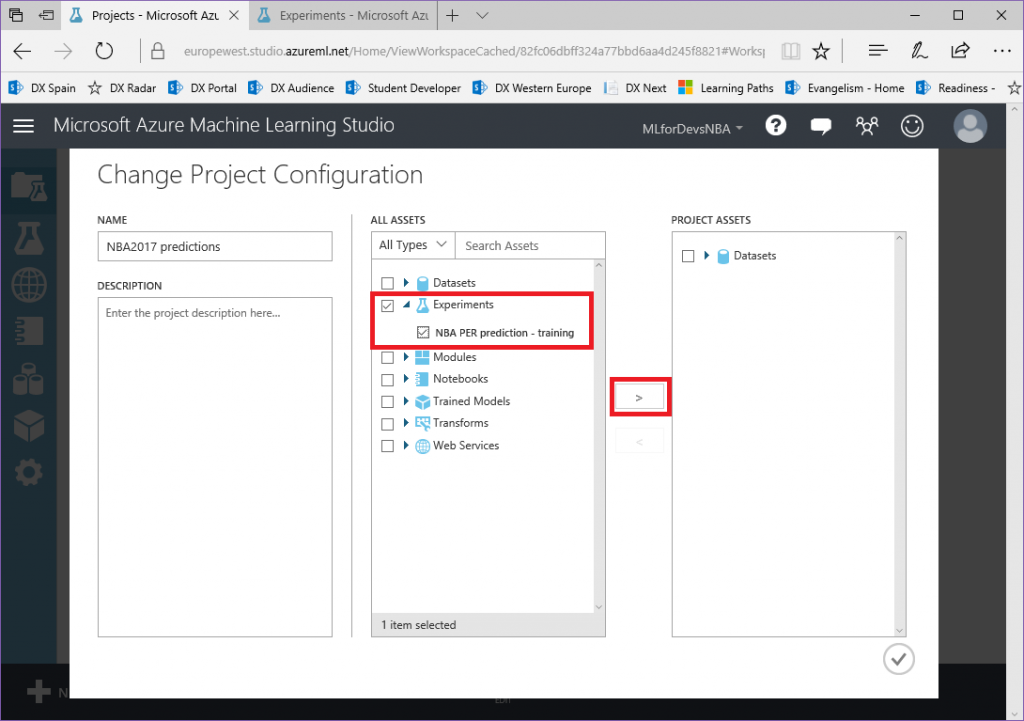
¡Todo preparado! Ya tenemos los conjuntos de datos, el experimento de entrenamiento con el primer paso en el flujo de datos y el proyecto que contiene todos los elementos creado, que debería tener este aspecto:
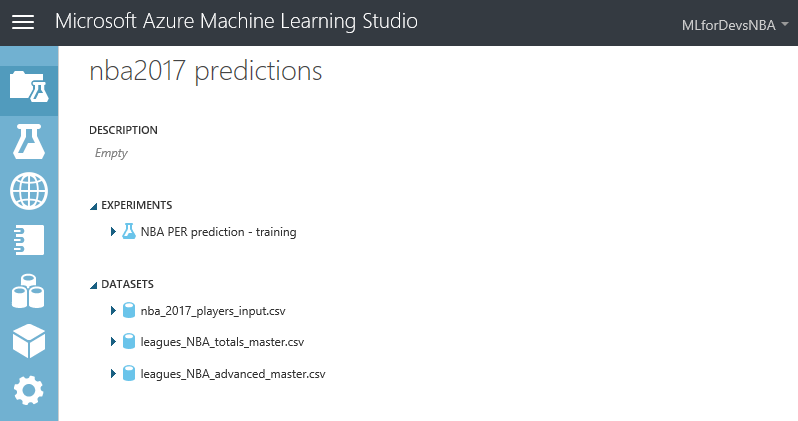
En el siguiente capítulo, comenzaremos a limpiar y preparar nuestros datos, parte fundamental de todo experimento de Machine Learning.
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist
Machine Learning para principiantes – Capítulo 3: preparación y limpieza de los datos
En este capítulo vamos a pasar a una parte clave de todo experimento de Machine Learning: el procesado previo de los datos, en el que limpiaremos y prepararemos los datos de entrenamiento y evaluación a utilizar, para que nuestro modelo entrenado funcione lo mejor posible.
Como podemos ver al explorar nuestros datos, hay varias cosas que "ensucian" nuestro conjunto de datos (caracteres especiales en los nombres, filas con datos de encabezado por todo el archivo ...), campos sin valor asignado, campos tratados como texto cuando son números...
Con el fin de obtener los mejores resultados de nuestro experimento, debemos preparar y limpiar nuestros datos correctamente, y en este capítulo vamos a aprovechar algunos de los módulos de Azure ML Studio para lograr nuestra meta.
En primer lugar, ya que algunos jugadores tenían algunas condiciones especiales en temporadas específicas, están marcados con un asterisco en sus nombres. Este carácter especial, que no forma parte del nombre real del jugador, podría distorsionar nuestro conjunto de datos afectando a la calidad de nuestros resultados, ya que el mismo jugador podría ser tratado como uno diferente por esta minúscula diferencia en el nombre.
En el menú de la izquierda, bajo la categoría "Text Analytics" , podemos encontrar el módulo "Preprocess Text" , que se ocupará de esto por nosotros simplemente desmarcando todos los checkboxes excepto el de "Remove special characters" . Ten en cuenta que debemos establecer también el idioma (inglés en este caso) en la primera lista desplegable, y seleccionar la columna deseada (Player, en la que encontramos el nombre del jugador) para aplicar la transformación.
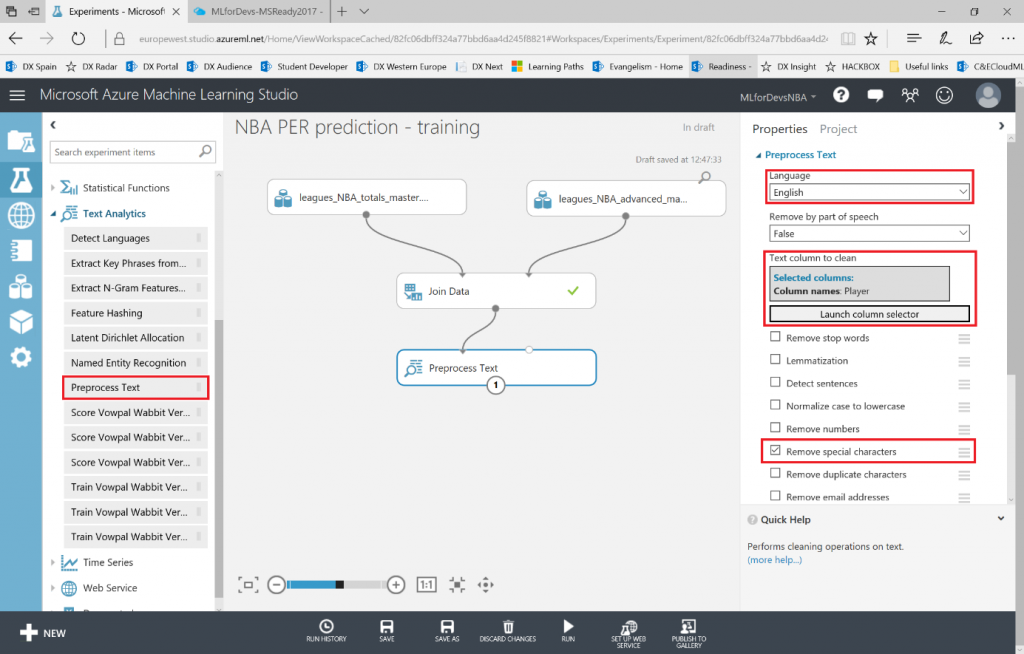
Si ejecutamos el experimento otra vez, tendremos un dataset como resultado, conteniendo tanto el nombre original del jugador (Player) como una nueva columna eliminando estos caracteres especiales (Preprocessed Player):
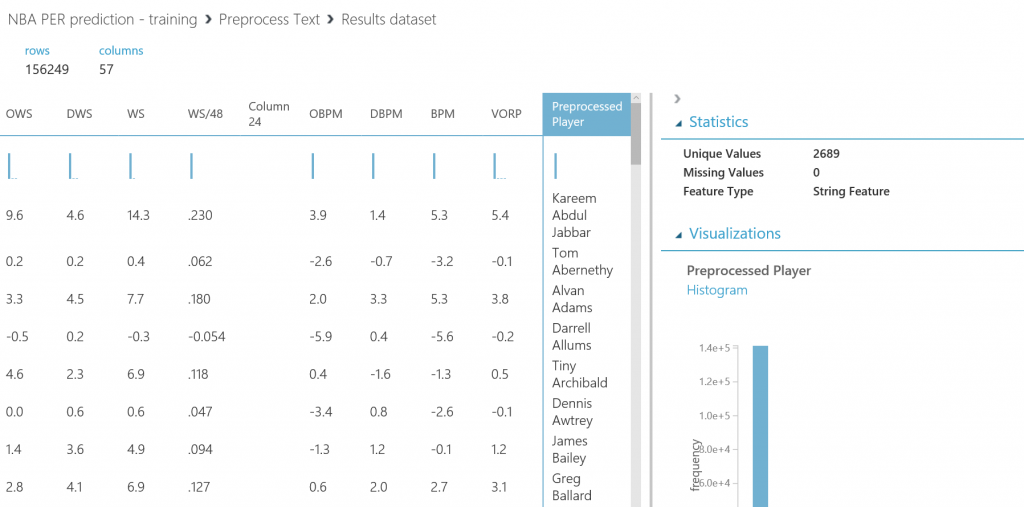
Además, para facilitarnos entender mejor el dataset, podemos cambiar los nombres de nuestras columnas usando el modulo "Edit Metadata" , para que podamos crear consultas más simples o encontrar las features de nuestro conjunto de datos con un nombre más descriptivo que el acrónimo. En este caso, cambiaremos el nombre de "Rk, Pos, Tm, G, GS, MP, FG, 3P, 2P, FT, Preprocessed Player" seleccionando las columnas del selector de columnas y escribiendo lo siguiente en el texbox de "New column names" :
Rank,Position,Team,GamesPlayed,GamesStarted,MinutesPlayed,FGM,3PM,2PM,FTM,PreprocessedPlayer
Ten en cuenta que el orden es importante, ya que lo que hace este módulo es cambiar el nombre de cada columna seleccionada con el texto en la misma posición en la lista separada por comas de nuevos nombres, por lo que ambas listas deben estar en el mismo orden y tener la misma longitud.
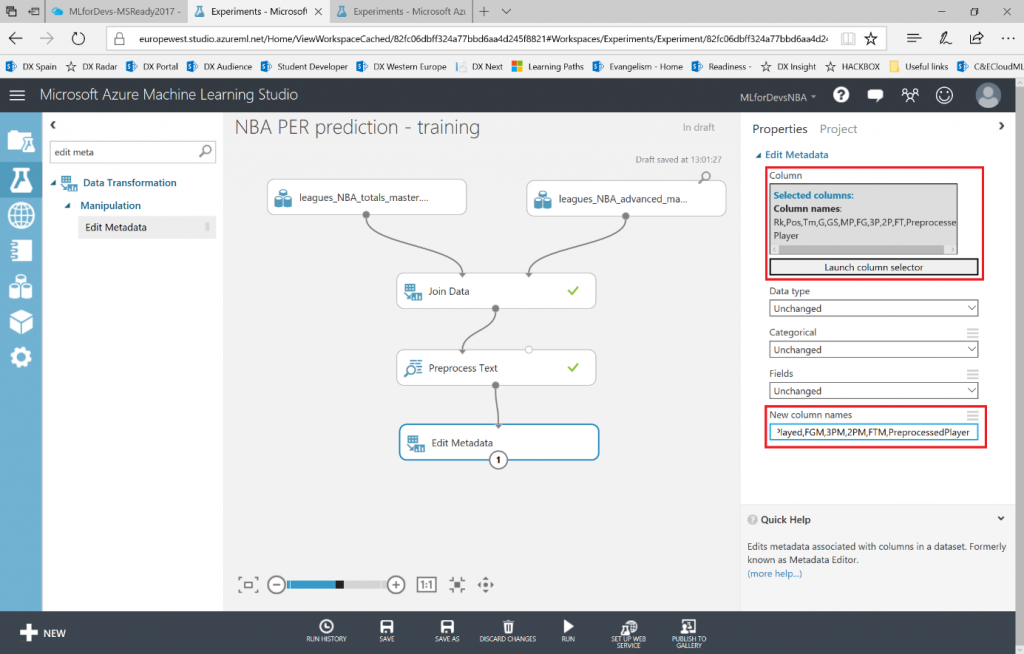
Para evitar duplicados y simplificar las cosas, asignaremos el valor "limpio" del nombre del jugador a la columna Player y también eliminaremos todas las filas de encabezado que podamos encontrar entre filas de datos. Para lograrlo, Azure ML tiene un módulo de consultas SQL que nos permitirá tratar nuestro conjunto de datos (o conjuntos de datos, hasta tres de ellos en cada módulo) como una tabla de base de datos, por lo que podemos realizar transformaciones a través de consultas t-SQL. Busca el módulo "Apply SQL transformation" en la categoría "Data Transformation > Manipulation" y conecta el conjunto de datos resultante con uno de los puntos de entrada del módulo de consultas SQL. Como tiene 3 puntos de entrada diferentes, uno para cada conjunto de datos posible, los tratará como t1/t2/t3 en la consulta. En este caso, ingresaremos una consulta simple filtrando esos valores de encabezado y reemplazando el valor Player por cada registro en nuestro dataset con la siguiente consulta:
update t1 set Player=PreprocessedPlayer;
select * from t1 where Rank<>"Rk";
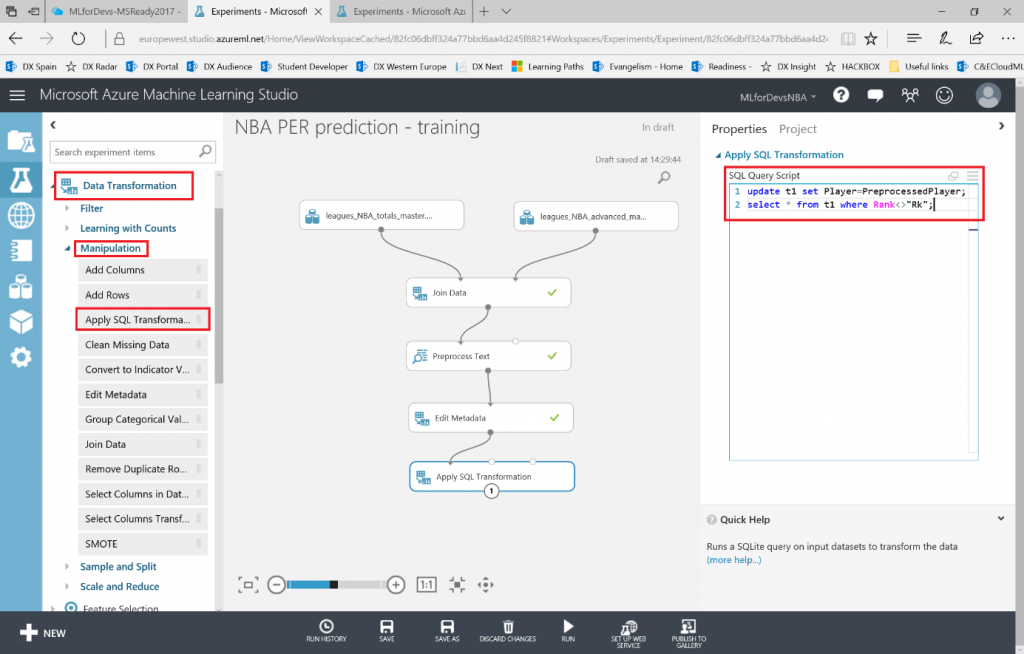
Si vuelves a ejecutar el experimento, notarás que ahora tenemos más de 14k filas en lugar de las 16k iniciales, y ninguna fila de encabezado se incluye ahora en nuestros datos.
Para realizar varias operaciones numéricas (como rangos aceptados, reemplazar valores no incluidos, etc.), debemos asegurarnos de que la herramienta esté tratando las columnas numéricas como el tipo que son (enteros o flotantes). El modulo "Edit Metadata" nos ayudará de nuevo a lograrlo, por lo que tendremos que añadir otros dos módulos, uno para las columnas de tipo Integer (Rank, Age, GamesPlayed, GamesStarted, MinutesPlayed, FGM, FGA, 3PM, 3PA, 2PM , 2PA, FTM, FTA, ORB, DRB, TRB, AST, STL, BLK, TOV, PF, PTS, Season) y otra para las columnas de tipo Floating Point (FG%,3P%,2P%,eFG%,FT%,PER,TS%,3PAr,FTr,ORB%,DRB%,TRB%,AST%,STL%,BLK%,TOV%,USG%,OWS,DWS,WS,WS/48,OBPM,DBPM,BPM,VORP), seleccionando las columnas con el selector de columnas.
Necesitamos ejecutar el experimento antes de añadir el segundo, ya que necesitará el conjunto de datos resultante anterior como entrada para el segundo, de modo que la herramienta conozca el nombre de cada columna. Una vez que tengas ambos módulos, el experimento debería tener este aspecto:
Ahora que estamos seguros de que cada columna se maneja correctamente, vamos a limpir los datos analizando cuántas veces faltan valores en las distintas columnas. Busca el modulo "Clean missing data" en el menú de la izquierda, en la categoría "Data Transformation > Manipulation" . En este caso, nos centraremos en los valores numéricos de nuestro conjunto de datos, y con este módulo podemos elegir qué hacer cuando no se encuentra un valor (podemos configurar el método de sustitución para reemplazar los valores que falten por uno de nuestra elección: media, mediana, moda, borrar la fila, borrar la columna o reemplazar usando el método Probabilistic PCA).
Normalmente, lo que debemos hacer es quitar toda la fila, pero en este caso vamos a reemplazar los valores numéricos que faltan con el valor medio seleccionando esta opción en el menú desplegable, para poder analizar cuántas veces sucedió y decidir si la característica afectada es relevante (pocas sustituciones, por lo que los datos son válidos) o no.
En este caso, ya que ya nos aseguramos de que los valores numéricos se traten como tal, podemos seleccionar las columnas por tipo en lugar de por nombre en el selector de columnas. Marca la pestaña "WITH RULES" , haz click en el botón "NO COLUMNS" y luego agrega una regla para cada tipo numérico (Numeric, Integer, Double) disponible en la lista desplegable:
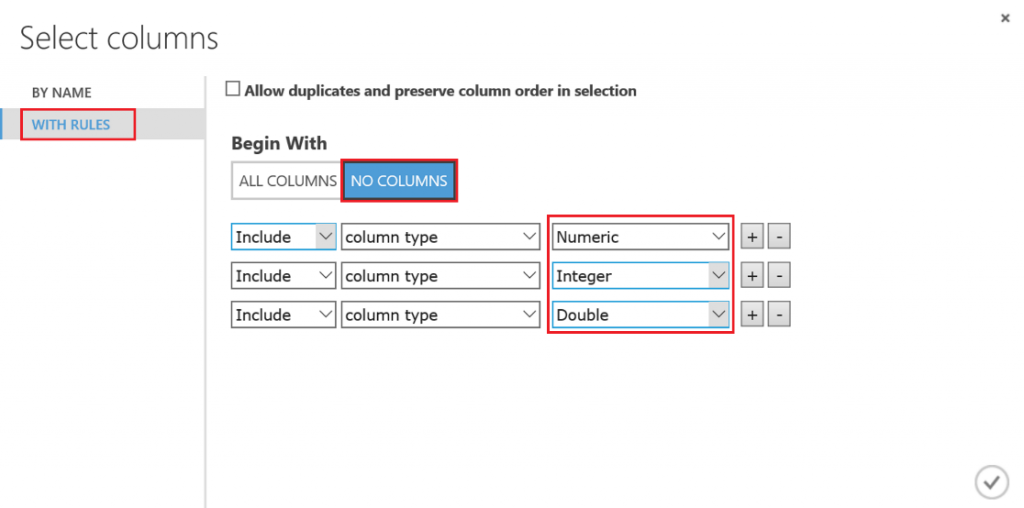
Ten en cuenta el ultimo checkbox de este módulo, llamado "Generate missing value indicator column" , ya que nos ayudará a analizar si una columna es relevante o no mediante un campo de tipo bool para ayudarnos a visualizar y entender cuántas veces se reemplazó algún dato en la columna. Marca el checkbox y ejecuta el experimento:
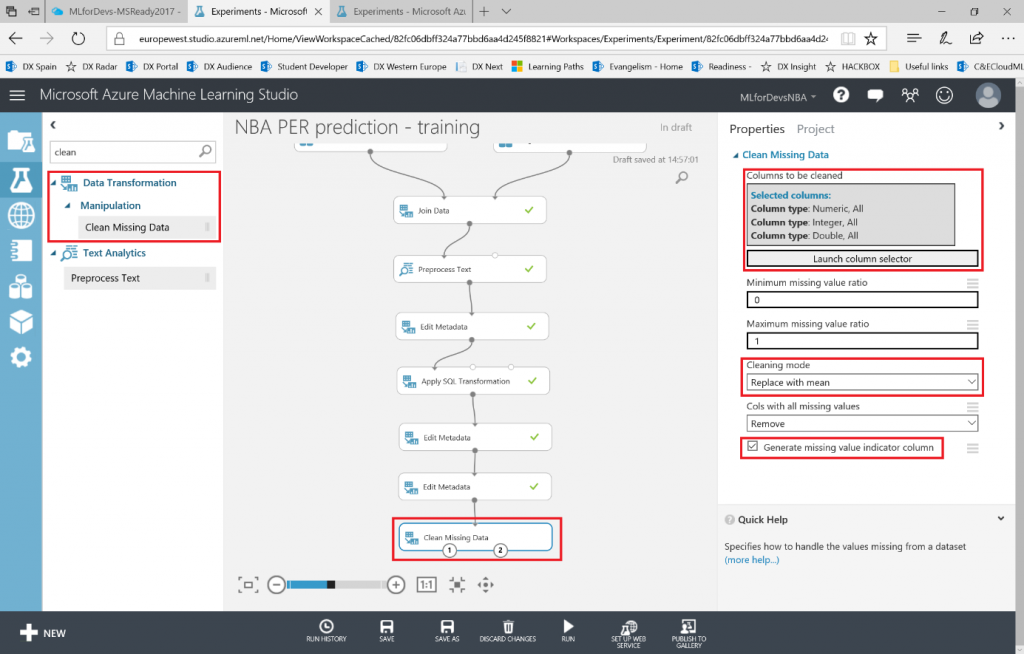
Después de ejecutar el experimento, al visualizar el dataset resultante y hacienda scroll hacia la derecha hasta las últimas columnas, podrás observar que varias columnas "<<feature_name>>_isMissing" se han añadido a su conjunto de datos, y tomando como ejemplo la columna "GamesStarted_isMissing" es fácil entender que, como los valores de esta columna han sido reemplazados la mayoría de las veces, no es relevante para nuestro experimento, ya que estaríamos utilizando más valores ficticios que reales. Para el resto de las columnas, ya que los valores reemplazados son realmente bajos, pueden seguir considerándose relevantes para el experimento:
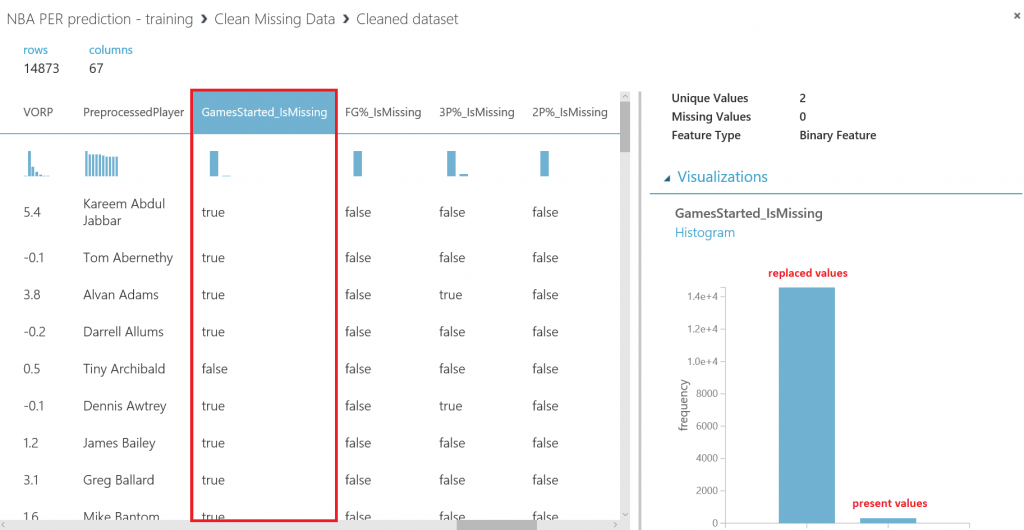
En cualquier caso, en este experimento no usaremos todos estos valores numéricos, ya que no los conoceremos antes de la temporada y estamos buscando una predicción del PER del jugador, el valor numérico que resume su valoración y nos ayudará a seleccionar a los mejores jugadores para nuestro equipo. Seleccionaremos sólo las columnas que usaremos:
- Las entradas conocidas para nuestro experimento (Player, Position, Age, Team y Season)
- La feature a predecir (PER)
En el menu de la izquierda, busca el modulo "Select Columns in Dataset" , en la categoría "Data Transformation > Manipulation" , arrástralo al canvas y conecta su punto de entrada con el punto de salida izquierdo del módulo anterior, el que contiene el conjunto de datos resultante del paso anterior. Para seleccionar las columnas necesarias, puedes escogerlas por nombre en el selector de columnas:
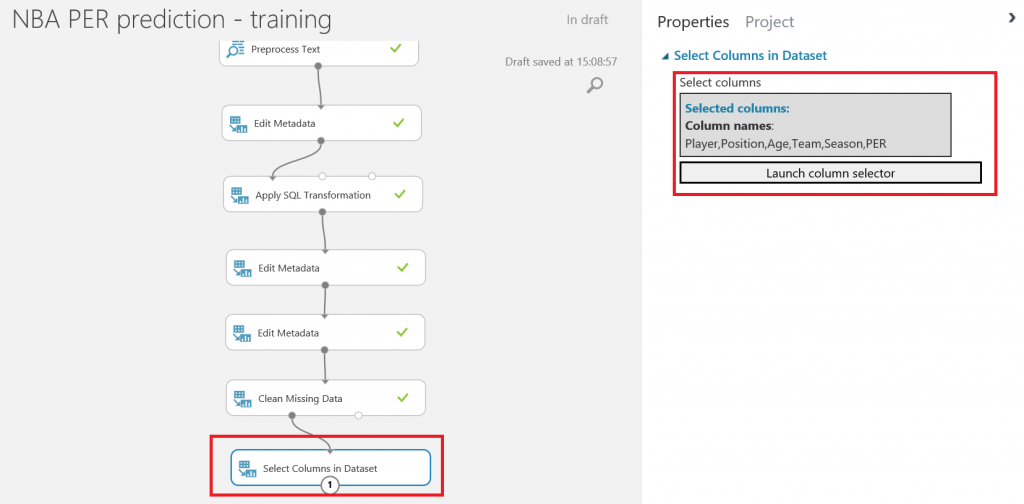
Después de ejecutar el experimento de nuevo, tendremos un conjunto de datos de 14k+ filas y 6 columnas, que utilizaremos para entrenar y evaluar nuestro modelo.
La última transformación a realizar en nuestro conjunto de datos es acotar los valores de la feature que queremos predecir, el PER (Player Efficiency Rating), ya que es una estadística bien conocida que nunca ha sido superior a 35. En este caso, también asumimos que cualquier jugador obtendrá un valor negativo de PER en una temporada completa, por lo que también recortaremos esos valores menores que cero.Lo que estamos tratando de lograr con esta acotación, tanto de peaks (valores altos por encima del umbral normal de una entidad) como de sub-peaks (valores bajos por debajo del umbral normal de la entidad), es crear un conjunto de datos normalizado, en el que la mayoría de los valores estará alrededor de la media, creando una curva de Gauss cuando se representa gráficamente. Es el mejor tipo de conjunto de datos para entrenar un modelo, ya que tendrá menos valores extremos (anómalos), y la mayor cantidad de valores será "normal", es decir, alrededor del valor promedio. Echa un vistazo a este link para aprender algo más sobre la distribución gaussiana o normal, ya que es una de las distribuciones de probabilidad de variable continua que aparece con más frecuencia en fenómenos reales.
Para normalizar los valores de nuestro PER, busca el modulo "Clip Values" en la categoría "Data Transformation > Scale and Reduce" en el menú de la izquierda y arrástralo a tu canvas. Cuando lo conectes al módulo anterior, selecciona la opción "ClipPeaksAndSubpeaks" en la lista desplegable, establece los valores para el umbral superior (35) y el umbral inferior (0) ya que serán los valores máximo y mínimo aceptados, y selecciona sólo la columna PER con el selector de columnas:
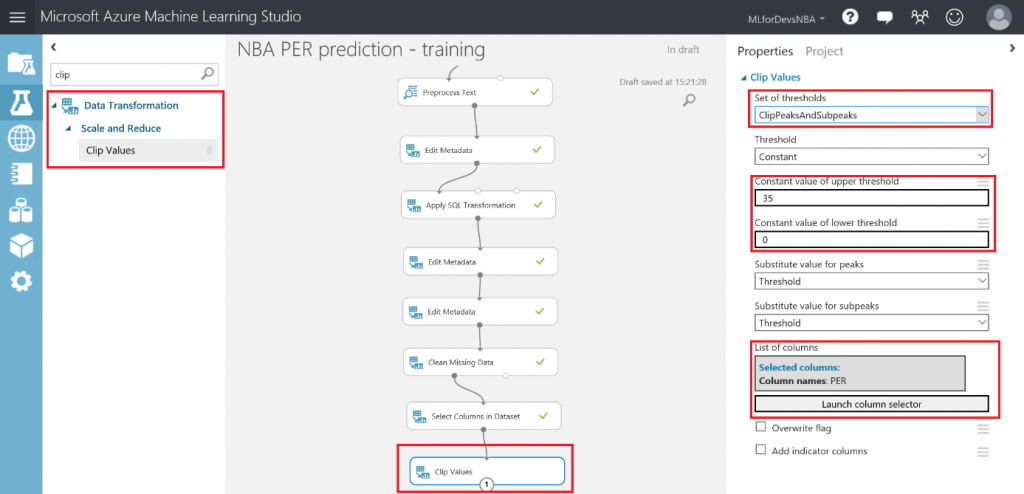
Después de ejecutar el experimento nuevamente, puedes comprobar que el PER es una distribución normal por definición. Haz click con el botón derecho en el punto de salida del modulo "Clip Values" , luego en "Visualize" , y selecciona la columna PER. En el panel derecho del pop-up de visualización, verás una representación gráfica de la columna seleccionada como un gráfico de barras verticales, mostrando una distribución normal (ligeramente sesgada a la izquierda, ya que hay más jugadores por debajo del promedio de la liga que por encima...zona también conocida como la Superstar Zone):
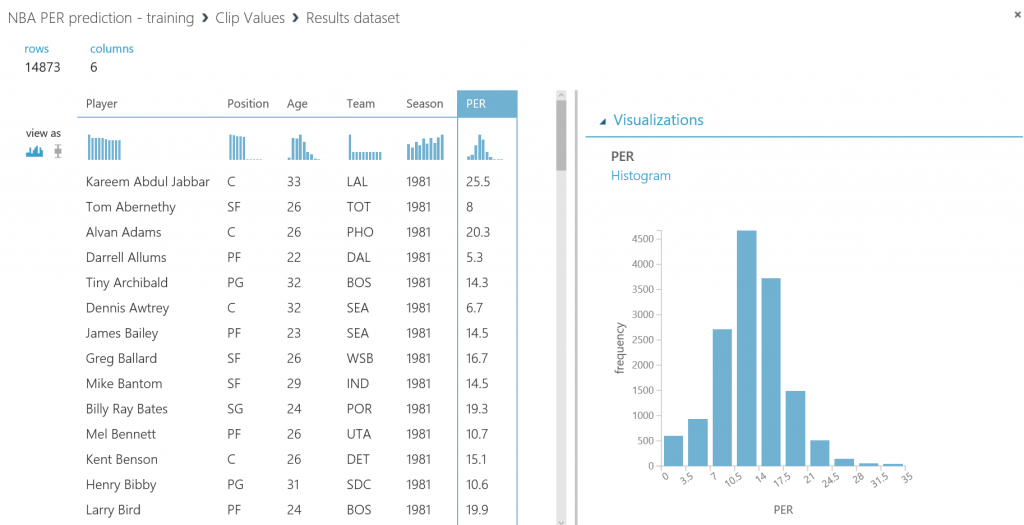
Con esto damos por finalizada la limpieza y preparación de nuestros datos, y en el siguiente capítulo empezaremos a entrenar nuestro modelo.
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist
Machine Learning para principiantes – Capítulo 4: entrenando y evaluando el modelo
Ahora que los datos están limpios y prepararados para el entrenamiento, es hora de crear un modelo entrenado que nos ayude a predecir los valores futuros del Player Efficiency Rating para cada jugador de la NBA. El primer punto a entender con respecto al entrenamiento es cómo funciona, que es básicamente comparando valores predichos con valores conocidos, para que podamos evaluar la precisión del modelo y seguir puliéndolo hasta obtener los mejores resultados posibles.
Para que podamos comparar estos valores predichos con los conocidos, tendremos que dividir nuestro conjunto de datos en dos:
- Training dataset: valores utilizados para formar el modelo que generará la predicción
- Testing dataset: a utilizar contra este modelo entrenado, y que tendrá el valor conocido (el valor real en el conjunto de datos) y el valor predicho por el modelo, por lo que se pueden comparar ambos
En este caso, al predecir un valor numérico, nos enfrentamos a un problema de regresión. En estos problemas, el resultado deseado es una representación gráfica con una línea diagonal de la predicción resultante cuando se traza con los valores conocidos, ya que indicará que los valores predichos son precisos o cercanos a los reales. Esta representación gráfica pondrá el valor conocido en un eje y el valor predicho en el otro eje, y pinta los puntos basados en esos pares de valores. Es por eso que cuanto más cercano a una diagonal exacta mejor, ya que más valores predichos coinciden o son cercanos a los valores reales. Pero no te preocupes, en un momento estaremos con ello.
Otros tipos de problemas a tratar con técnicas de Machine Learning podrían ser clasificaciones (aplicar 2 o más etiquetas o categorías a una determinada información de entrada), clustering y detección de anomalías. Afortunadamente para nosotros, no expertos en data science, hay una "chuleta" disponible para ayudarnos a decidir cuál es el mejor algoritmo para usar en nuestros experimentos (https://aka.ms/MLCheatSheet), y también te ayudará a obtener algo más de profundidad en los conceptos que hay tras este tipo de problemas y algoritmos.
Aquí, como nos enfrentamos a un problema de regresión típico, usaremos dos de los algoritmos de regresión más comunes: regresión lineal y regresión de redes neuronales, y los evaluaremos para decidir cuál rinde mejor y usar este modelo entrenado para predicciones futuras.
Pero lo primero es lo primero: vamos a dividir nuestro conjunto de datos para obtener tanto el training dataset como el testing dataset. Busca el modulo "Split Data" en "Data Transformation > Sample and Split" y arrástralo a tu canvas, conectando su entrada con la salida del modulo de "Clip Values" . Vamos a dejar "Split Rows" como el modo de división, y sólo seleccionaremos el porcentaje de filas para el primer conjunto de datos, en un valor entre 0 y 1. La mayoría de las veces, el 80% de las filas en el conjunto de datos están destinados a entrenamiento (training) y el otro 20% se deja para la puntuación/evaluación (testing), así que utilicemos estos valores por ahora. Como resultado, tendremos dos conjuntos de datos: uno con alrededor de 12k filas para training (punto de salida izquierdo) y otro con casi 3k filas para testing (punto de salida derecho), y puedes echar un vistazo a ambos, como siempre.
Una vez que tenemos ambos datasets listos, es hora de entrenar el modelo...o modelos en este caso, ya que vamos a utilizar dos algoritmos diferentes al mismo tiempo para compararlos. Para conseguir esto, necesitaremos dos módulos de "Train Model" (en la categoría "Machine Learning > Train" ), el módulo de algoritmo de la "Linear Regression" y el módulo de algoritmo de la "Neural Network Regression" (ambos bajo la categoría de "Machine Learning > Initialize Model > Regression" ).
Una vez añadidos al experimento, necesitaremos conectar cada algoritmo con el punto de entrada izquierdo de un modulo "Train Model" y el dataset de training (el punto de salida izquierdo del modulo "Split Data" ) con el punto de entrada derecho de ambos módulos "Train Model" , quedando así nuestros experimento:
Para configurar ambos módulos de "Train Model", solo necesitas seleccionarlos y elegir la columna de la que generar la predicción (en este caso, PER) usando el column selector:
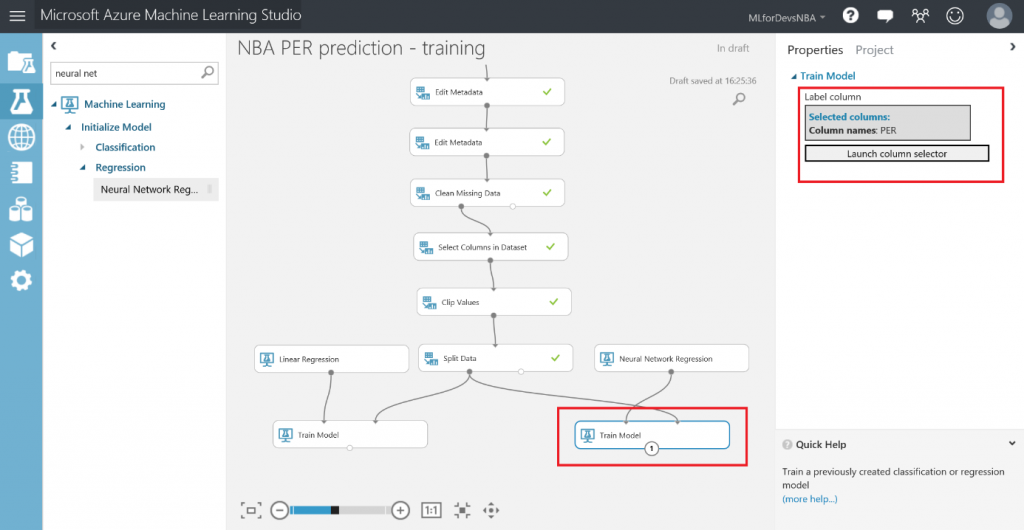
Tras ejecutar el experimento, con ambos modelos entrenados, vamos a evaluarlos puntuándolos con el testing dataset, el otro 20% de nuestros datos limpios. Busca el modulo "Score Model" en el menú de la izquierda (bajo la categoría de "Machine Learning > Score Model" ), y arrastra dos de ellos a tu canvas. En este caso, debemos conectar la salida de cada modulo "Train Model" a la entrada izquierda de cada módulo "Score Model" , y la segunda salida del módulo "Split Data" al punto de entrada derecho de ambos módulos de "Score Model" , quedando algo parecido a esto:
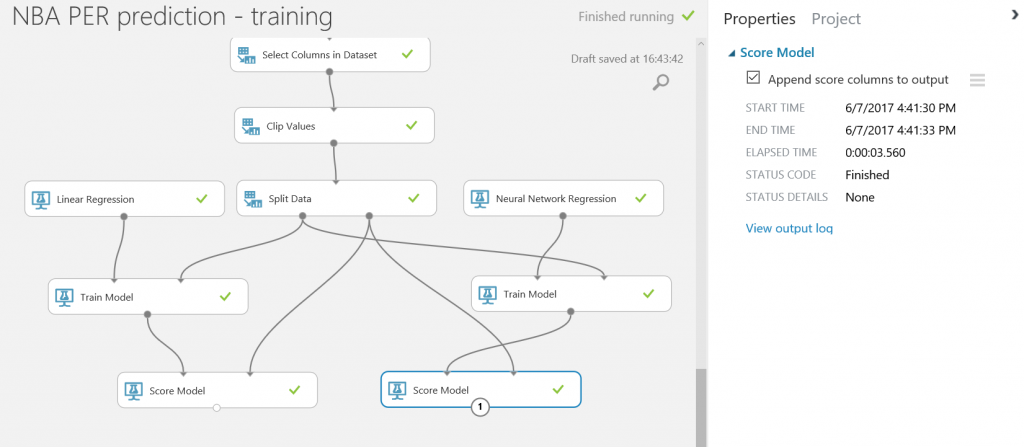
Ejecuta de nuevo el experimento y, una vez completado, podrás visualizar los resultados de las predicciones utilizando ambos algoritmos. Lo primero que puedes hacer para evaluar los resultados de su modelo es visualizar el conjunto de datos obtenido resultante y comparar el valor conocido (PER) con el valor predicho (etiquetas marcadas). Haz click con el botón derecho en el punto de salida de cualquier modulo "Score Model" y, con la ventana de visualización abierta, selecciona la columna "Scored Labels" (el valor predicho). En el panel derecho, selecciona la columna "PER" en la lista desplegable de "comparar con" y obtendrás el gráfico con el valor conocido y la predicción:
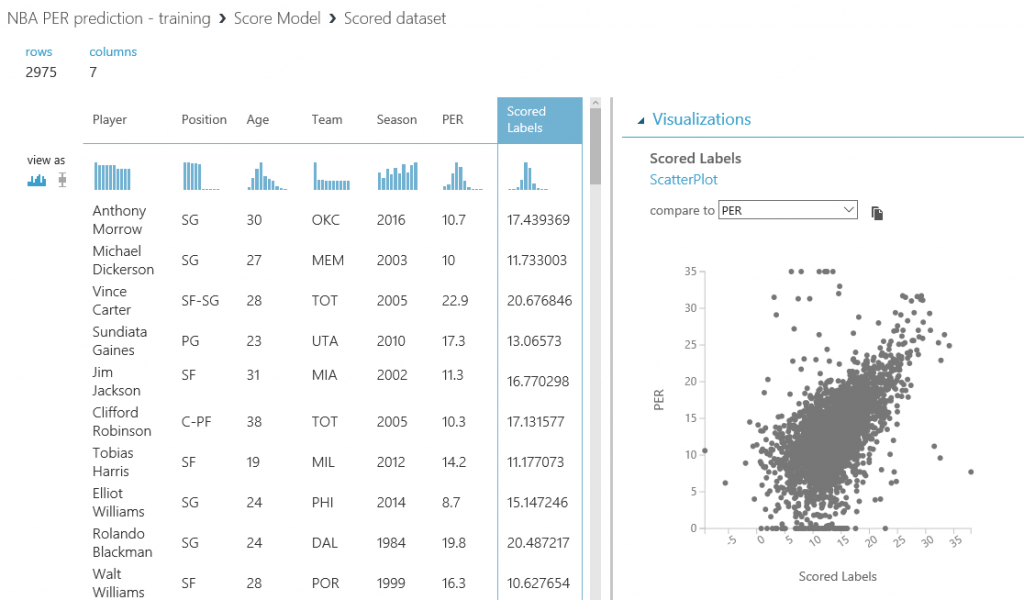
Como puedes ver, el resultado no se parece demasiado a diagonal en el gráfico mostrado, por lo que nuestro modelo no está funcionando muy bien. Por ejemplo, hay un montón de valores atípicos, el área cubierta es demasiado grande (mostrando que los resultados son muy dispersos y diferentes de la realidad)... Por lo tanto, todavía nos queda trabajo por hacer para mejorar nuestro modelo.
Pero, para no evaluar el modelo simplemente con la imagen de un gráfico, tenemos un módulo de "Evaluate model" en el menú de la izquierda, bajo la categoría "Machine Learning > Evaluate" , que nos dará más información sobre el rendimiento de nuestro modelo, con datos como el error absoluto medio y el coeficiente de determinación, entre otros. Simplemente conecta ambos módulos de "Score Model" con las entradas del modulo "Evaluate Model" , dejando nuestro experimento como sigue:
Vamos a comprobar estos valores haciendo click con el botón derecho en el punto de salida del módulo "Evaluate Model" y luego en "Visualizar" . Este último, el Coeficiente de Determinación, medirá el porcentaje de precisión que tiene nuestro modelo; así que, cuanto más alto, mejor!
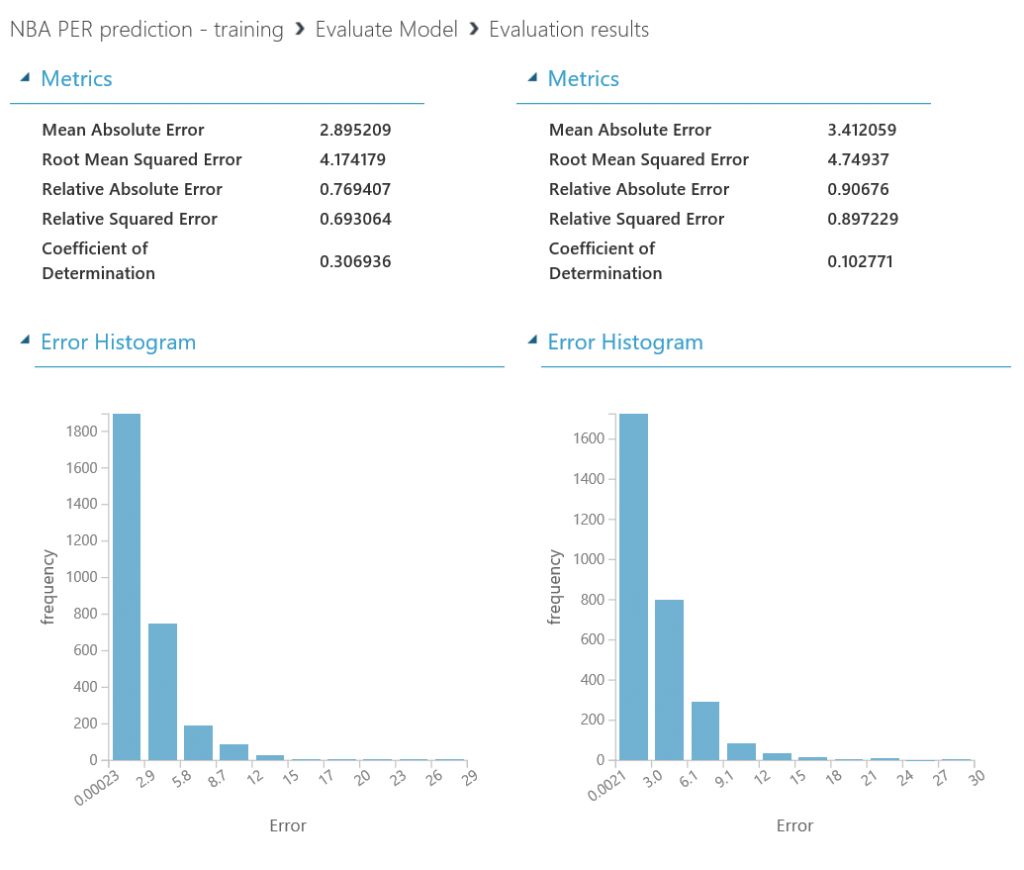
Como puedes ver, ambos algoritmos están rindiendo bastante mal, con solo un 30% y un 10% de precisión respectivamente, así que en el próximo capítulo veremos cómo mejorar nuestro modelo con algunos ajustes.
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist
Machine Learning para principiantes - Capítulo 5: refinando el modelo y volviendo a evaluar
Como pudimos ver en el capítulo anterior, los resultados de nuestro modelo no son muy prometedores...todavía! Vamos a mejorar algunos aspectos de la limpieza de nuestro conjunto de datos haciendo algunos ajustes que mejorarán el rendimiento de nuestro modelo.
Lo primero que hará que nuestros datos sean más precisos es filtrar por una cantidad mínima de partidos jugados, ya que es "más fácil" destacar en pocos pocos partidos o tener un pico de rendimiento en un partido en concreto en lugar de rendir consistentemente a un nivel alto. Después de algunas pruebas, 55 partidos fue uno de los valores que mejores resultados arrojaba, por lo que debemos actualizar la consulta SQL para reflejar ese filtro:
update t1 set Player=PreprocessedPlayer;
select * from t1 where Rank<>"Rk" AND GamesPlayed>=55
Si vuelves a ejecutar el experimento, notarás que el número de filas en el conjunto de datos disminuye significativamente, el plotting se ve mejor y el rendimiento mejora consistentemente alcanzando un 47% y un 48% de precisión, respectivamente:
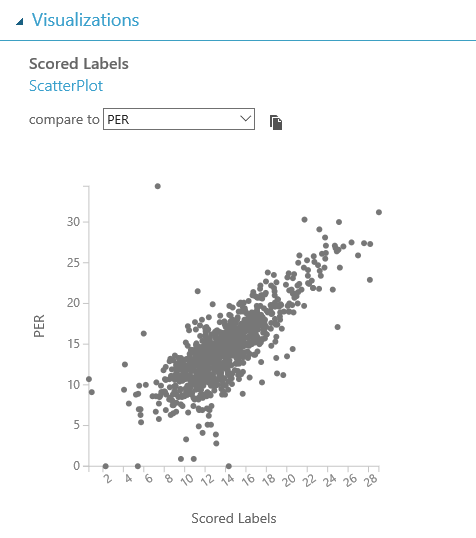
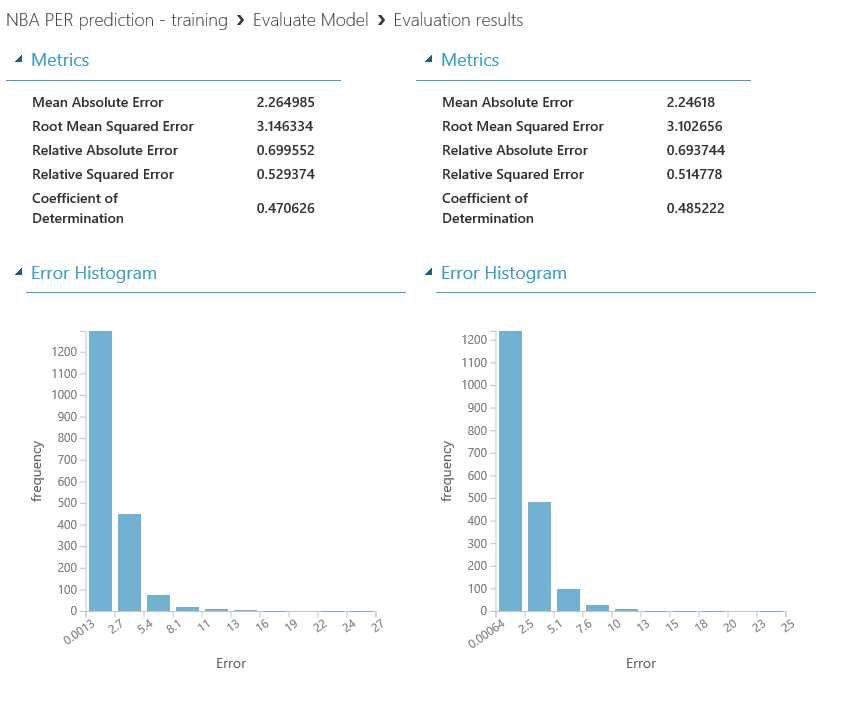
Cosas como esta son claros ejemplos de lo importante que es conocer el dominio de los datos que está manejando, y no sólo los conocimientos técnicos necesarios para estos problemas. En cada experimento de machine learning, tanto científicos de datos como personas de negocio con conocimiento del dominio deben ser incluidos, para que este tipo de detalles no se pierda.
Otra cosa que nos ayudaría a mejorar la calidad de nuestro modelo es usar un conjunto de pruebas de una longitud similar al que usaremos en el caso real. En este punto, nuestro conjunto de testing (el segundo conjunto de datos resultante del split), contiene casi 2k filas, cuando la realidad es que nuestro conjunto de datos de entrada para la predicción de la próxima temporada sólo contendrá 600-700 filas, que es el número de jugadores en activo en la NBA. Vamos a actualizar también la cantidad de datos utilizados para fines de entrenamiento, aumentando a 0.90 la cantidad de datos para el primer conjunto de datos de salida en el módulo "Split Data" , así como usar una semilla aleatoria para la división (en el ejemplo usamos 24832, pero es cuestión de probar diferentes valores y encontrar el que funciona mejor!):
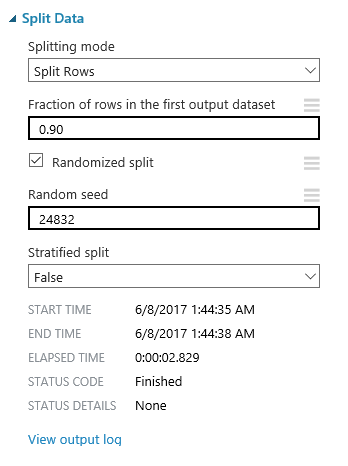
De nuevo, al ejecutar nuestro experimento tras el cambio, la precisión del modelo vuelve a mejorar bastante, alcanzando niveles de precisión de 0.56 y 0.51 respectivamente para cada algoritmo utilizado.
Por último, pero no por ello menos importante, la mayoría de los módulos de algoritmos permiten al usuario ajustar algunas de sus configuraciones, y su uso es muy útil para mejorar el rendimiento del modelo. En este caso, vamos a tomar el módulo de regresión de red neuronal (ya que es el que rinde un poco peor en esta momento) y hacer un pequeño ajuste.
En este algoritmo, hay diferentes parámetros que pueden ser editados, así que reduzcamos el número de nodos ocultos a 32 y también la tasa de aprendizaje a 0.001. Estos ajustes dependen del conjunto de datos utilizado y, de nuevo, sólo obtendrá los valores correctos al intentar diferentes ajustes y analizar el impacto en sus resultados. En este caso, estos ajustes en el algoritmo de regresión de redes neuronales han mejorado el rendimiento, alcanzando un valor de 0,60 en el Coeficiente de Determinación y haciendo que este algoritmo sea el mejor para nuestro modelo:
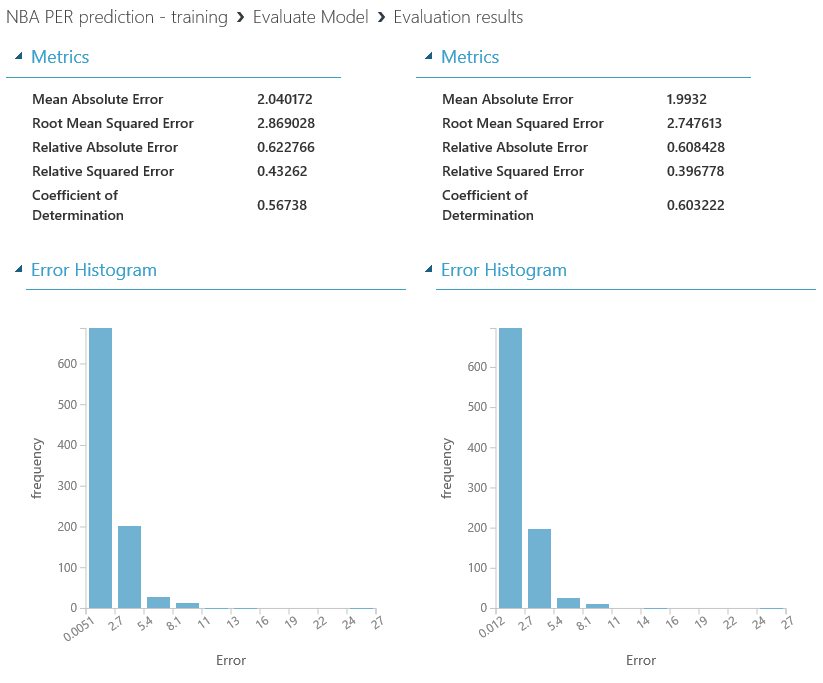
Con estos pequeños ajustes hemos conseguido multiplicar por bastante la precisión de nuestros modelos entrenados, y ahora sí que estamos preparados para predecir las valoraciones de nuestros jugadores favoritos para la próxima temporada...cosa que haremos en el próximo capítulo :)
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist
Machine Learning para principiantes – Capítulo 6: prediciendo el futuro
Ahora que hemos mejorado el modelo, es hora de aprovecharlo para predecir la valoración (Player Efficiency Rating) de los jugadores de la NBA en la próxima temporada. En este punto, todo lo que hemos creado es el experimento de entrenamiento, el que prepara los datos y entrena un modelo con datos históricos.
Vamos a llevarlo al siguiente nivel creando el experimento predictivo basado en el algoritmo que mejor funcionó después de los ajustes, la Neural Network Regression. Tendremos que configurar el Servicio Web predictivo, para que podamos usarlo como un módulo en Azure ML Studio o como un endpoint al que pedirle predicciones con algunos datos de entrada a través de una petición HTTP.
Para configurar el servicio web, selecciona el modulo "Train Model" conectado al algoritmo de Neural Network Regression (el que mejor rendimiento tuvo), busca el botón "SET UP WEB SERVICE" en la barra inferior y haz click en "Predictive Web Service [Recommended]" en el mini pop-up que aparece:
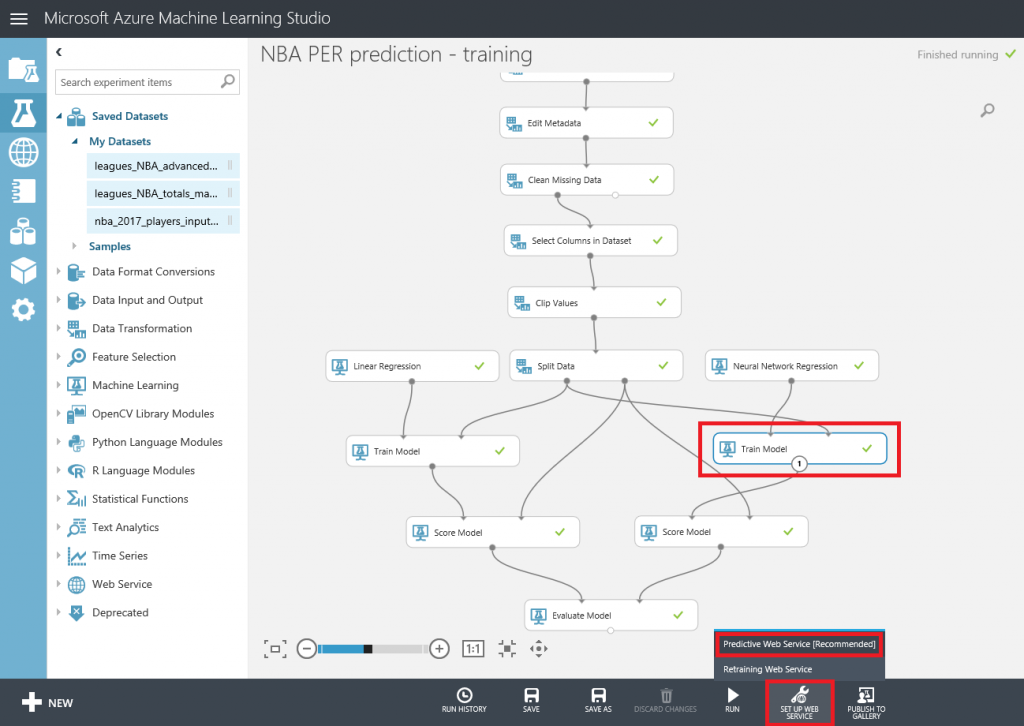
Una vez hecho esto, podrás ver algo parecido a lo siguiente:
Este nuevo experimento es nuestro experimento de predicción (denominado como Predictive Experiment, y que se muestra en una pestaña diferente), que contiene algunos de los pasos de preparación del experimento de entrenamiento, así como los módulos de "Web service input" y "Web service output" , que nos servirán para fijar en qué punto entran y salen los datos de nuestro web service, como datos de entrada de la petición y como cuerpo de la respuesta. Fíjate también en que hay un nuevo módulo con el mismo nombre que diste al experimento de entrenamiento, conectado a un módulo de "Score Model". Este módulo representa nuestro modelo entrenado con todo el trabajo previo que hemos hecho en el experimento de entrenamiento, y por eso se conecta directamente al módulo de puntuación/anotación, que lo que hará será utilizar este modelo entrenado con un dataset de datos futuros para generar las predicciones.
Para quedarnos solo con las partes necesarias y crear un experimento predictivo útil, vamos a conectar el módulo de "Web service input" como entrada de datos para el modulo "Score Model" , y a conectar el modulo "NBA PER prediction - training" como la otra entrada de nuestro "Score Model" . Mantengamos también el modulo "Score Model" y los módulos de entrada y salida del Web Service, eliminando todo lo demás. No necesitaremos todos los otros pasos involucrados, ya que nuestro conjunto de datos de entrada para la predicción futura ya contiene solo las columnas conocidas antes de que comience la temporada (Player, Position, Age, Team, Season) y no necesitamos realizar ninguna limpieza o procesamiento de estos datos, dado que ya vienen en el formato adecuado. Vamos a incluir también el conjunto de datos con los jugadores para la próxima temporada utilizando el tercer dataset que subimos al principio y que aún no hemos utilizado (nba_2017_players_input). Puedes encontrarlo en el menú de la izquierda, en la categoría "Saved Datasets > My Datasets" y, después de arrastrarlo al canvas, conéctalo también con el módulo de "Score Model" como entrada de datos. Tras hacer todo esto, el experimento predictivo debería quedar así:
Si ejecutas el experiment, tendrás un conjunto de datos que contiene las predicciones del PER de cada jugador de la NBA para la temporada 2016/2017, denominado como "Scored Labels" . Pero, de nuevo, es mejor darle a las cosas su nombre descriptivo, así que vamos a añadir un módulo de "Edit Metadata" después del "Score Model" para cambiar el nombre de la columna "Scored Labels" a su nombre real "PER" :
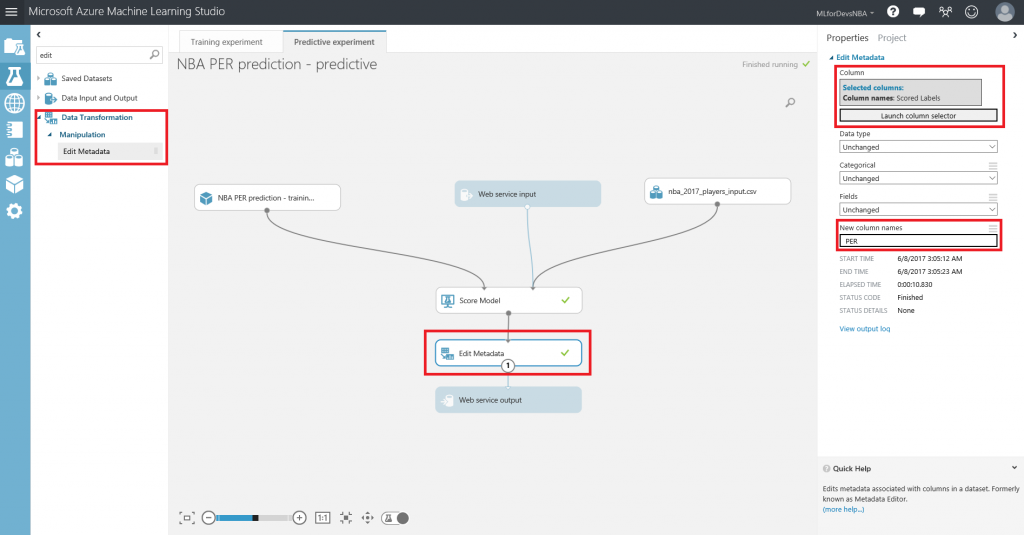
¡Enhorabuena! Si echas un vistazo al conjunto de datos resultante, estarás "leyendo el futuro" y viendo la predicción del PER/valoración para cada jugador en activo de la NBA durante la temporada 2016/2017. Ten en cuenta que también hay una nueva columna denominada "Drafted" , que será útil para la última parte (y bonus track de esta serie de posts) sobre visualización y consumición de datos de este experimento de Machine Learning.
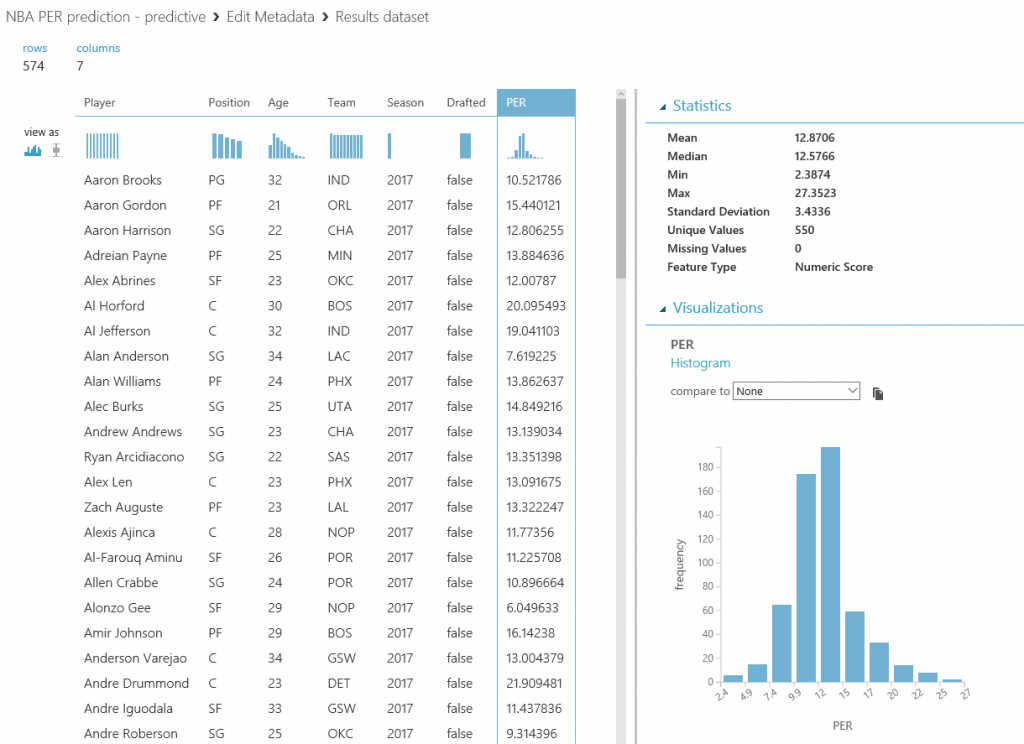
Un saludo,
Gorka Madariaga (@Gk_8)
Technical Evangelist
Popular posts from this blog
VSS yedekleme testi nasıl yapılır Exchange üzerinde bulunan verilerin yedeklenmesi (backup) ve geri yüklenmesi (restore) baslibasina çok önemli bir konudur. Bir yedegin saglikli alinmasi kadar restore isleminin basarili bir biçimde yapilabilmesi de test edilmesi gereken önemli bir islem. Exchange destegi olan (aware) diye adlandirdigimiz yazilimlar exchange writer'lari kullanarak VSS teknolojisi ile yedek alirlar. Yedekleme esnasinda karsilasilan sorunlarin büyük bölümünün nedeni, yazilimlarin uyumsuzlugu ya da bu yazilimlardaki yanlis bir ayar olabilmektedir. Bunun tespiti için, yani yedek alma sirasinda sorunun VSS Writer'dan mi, disk sisteminden mi ve/veya yedekleme yazilimindan mi kaynaklandigini anlayabilmek için Betest aracini kullanabilirsiniz. BETEST, Windows SDK yada Volume Shadow Copy Service SDK 7.2 (sonraki versiyonlarda mevcut) içerisinde bulunan yardimci bir araçtir. Araci kolaylikla bulabilir ve kurabilirsiniz. Kurulum islemini exchange sunucunuz...
Announcing the AdventureWorks OData Feed sample
Update – Removing Built-in Applications from Windows 8 In October last year I published a script that is designed to remove the built-in Windows 8 applications when creating a Windows 8 image. After a reading some of the comments in that blog post I decided to create a new version of the script that is simpler to use. The new script removes the need to know the full name for the app and the different names for each architecture. I am sure you will agree that this name - Microsoft.Bing – is much easier to manage than this - Microsoft.Bing_1.2.0.137_x86__8wekyb3d8bbwe. The script below takes a simple list of Apps and then removes the provisioned package and the package that is installed for the Administrator. To adjust the script for your requirements simply update the $AppList comma separated list to include the Apps you want to remove. $AppsList = "Microsoft.Bing" , "Microsoft.BingFinance" , "Microsoft.BingMaps" , "Microsoft.Bing...
ASP.NET AJAX RC 1 is here! Download now
Moving on with WebParticles 1 Deploying to the _app_bin folder This post adds to Tony Rabun's post "WebParticles: Developing and Using Web User Controls WebParts in Microsoft Office SharePoint Server 2007" . In the original post, the web part DLLs are deployed in the GAC. During the development period, this could become a bit of a pain as you will be doing numerous compile, deploy then test cycles. Putting the DLLs in the _app_bin folder of the SharePoint web application makes things a bit easier. Make sure the web part class that load the user control has the GUID attribute and the constructor sets the export mode to all. Figure 1 - The web part class 2. Add the AllowPartiallyTrustedCallers Attribute to the AssemblyInfo.cs file of the web part project and all other DLL projects it is referencing. Figure 2 - Marking the assembly with AllowPartiallyTrustedCallers attribute 3. Copy all the DLLs from the bin folder of the web part...

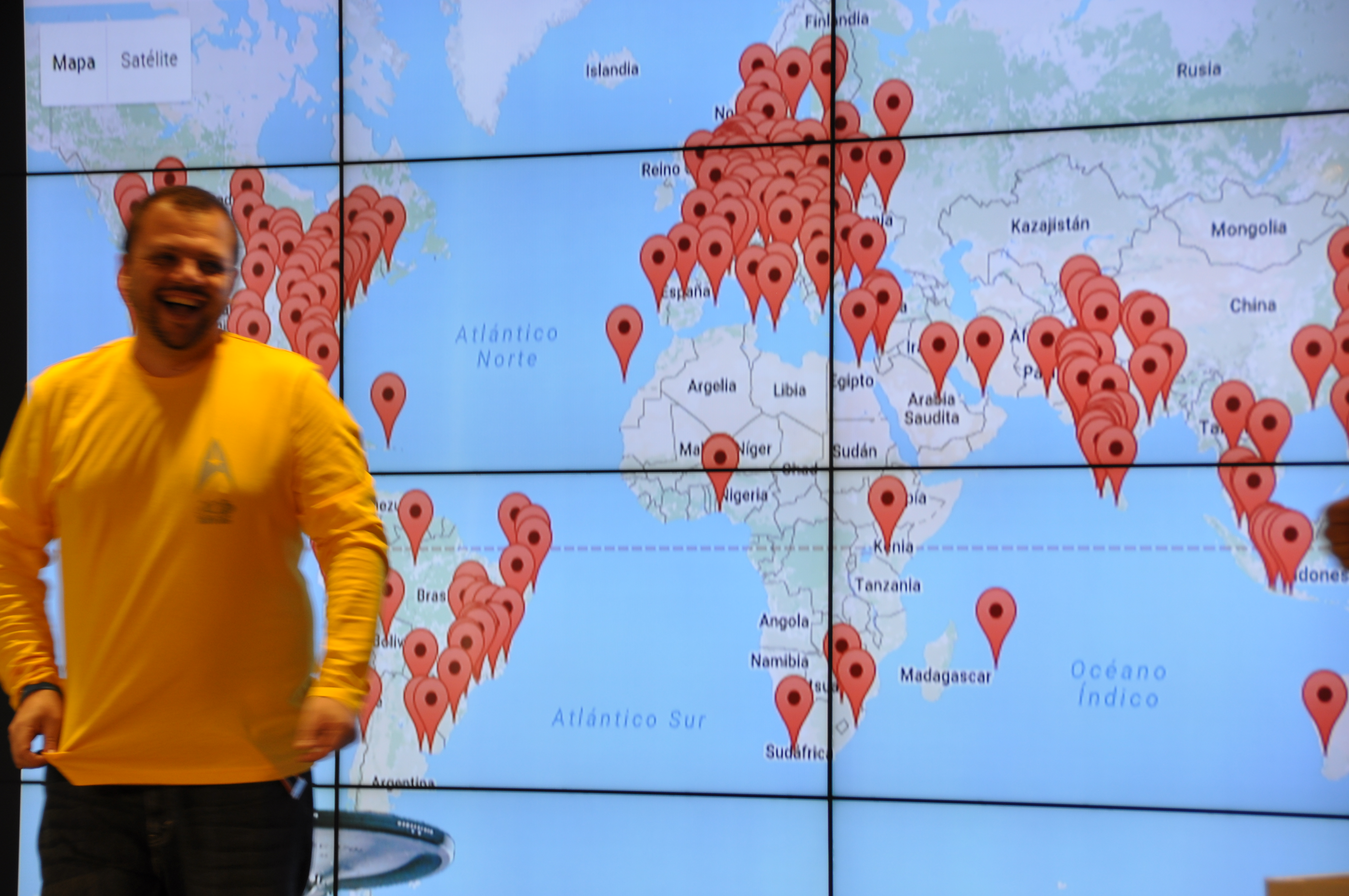




















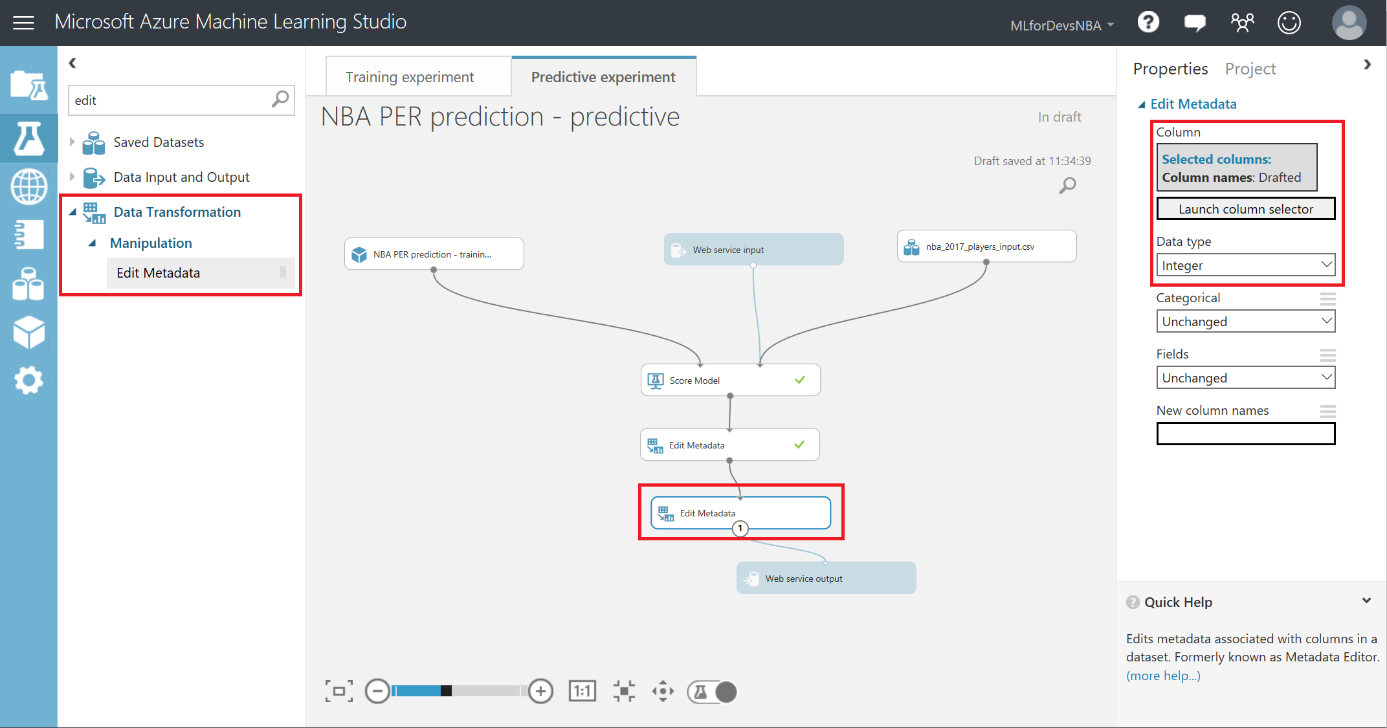
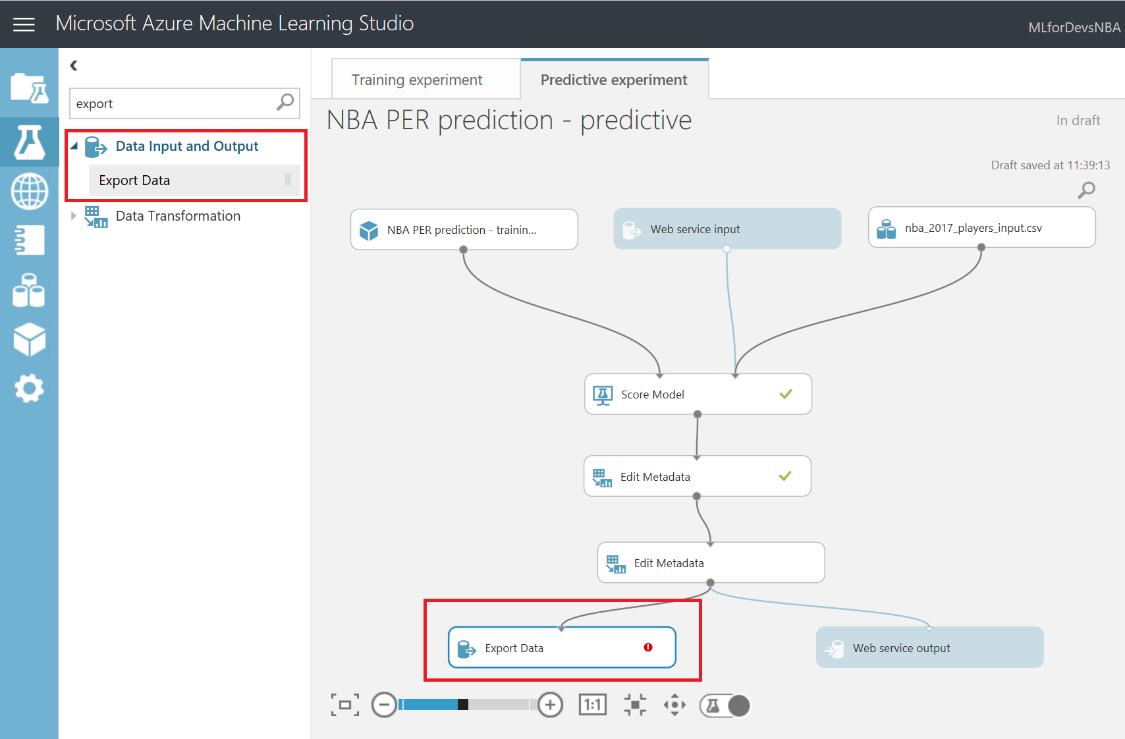
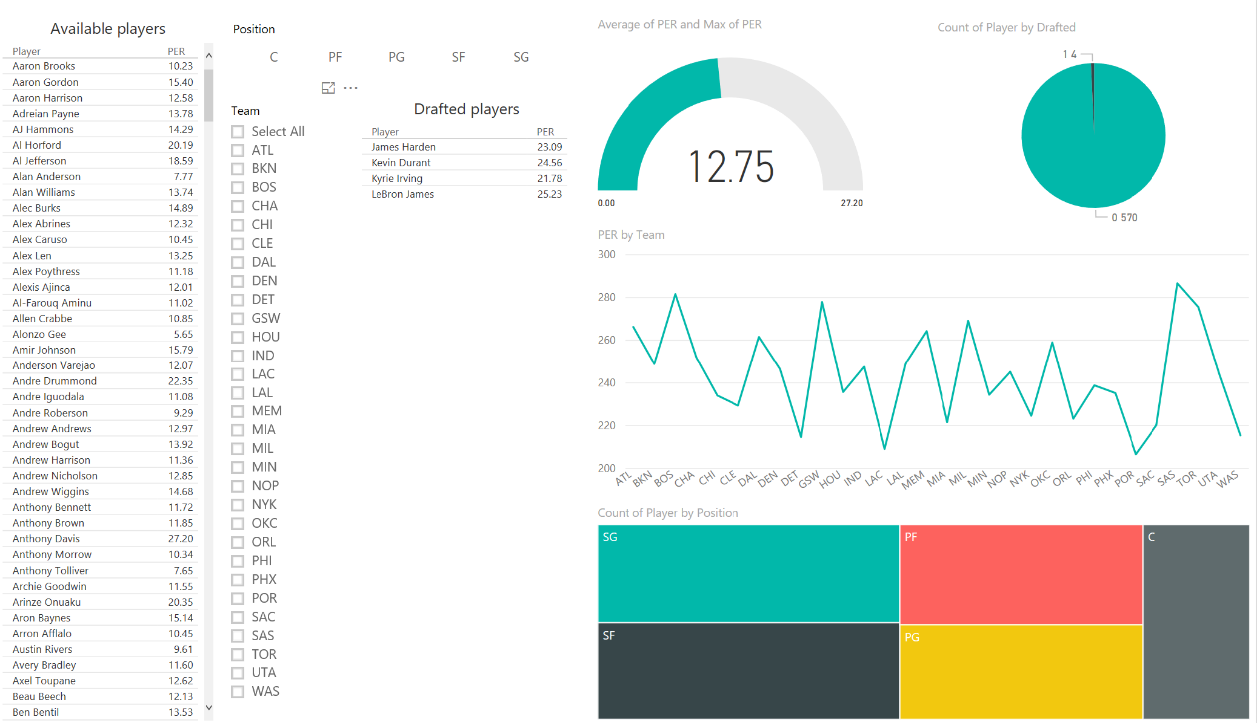
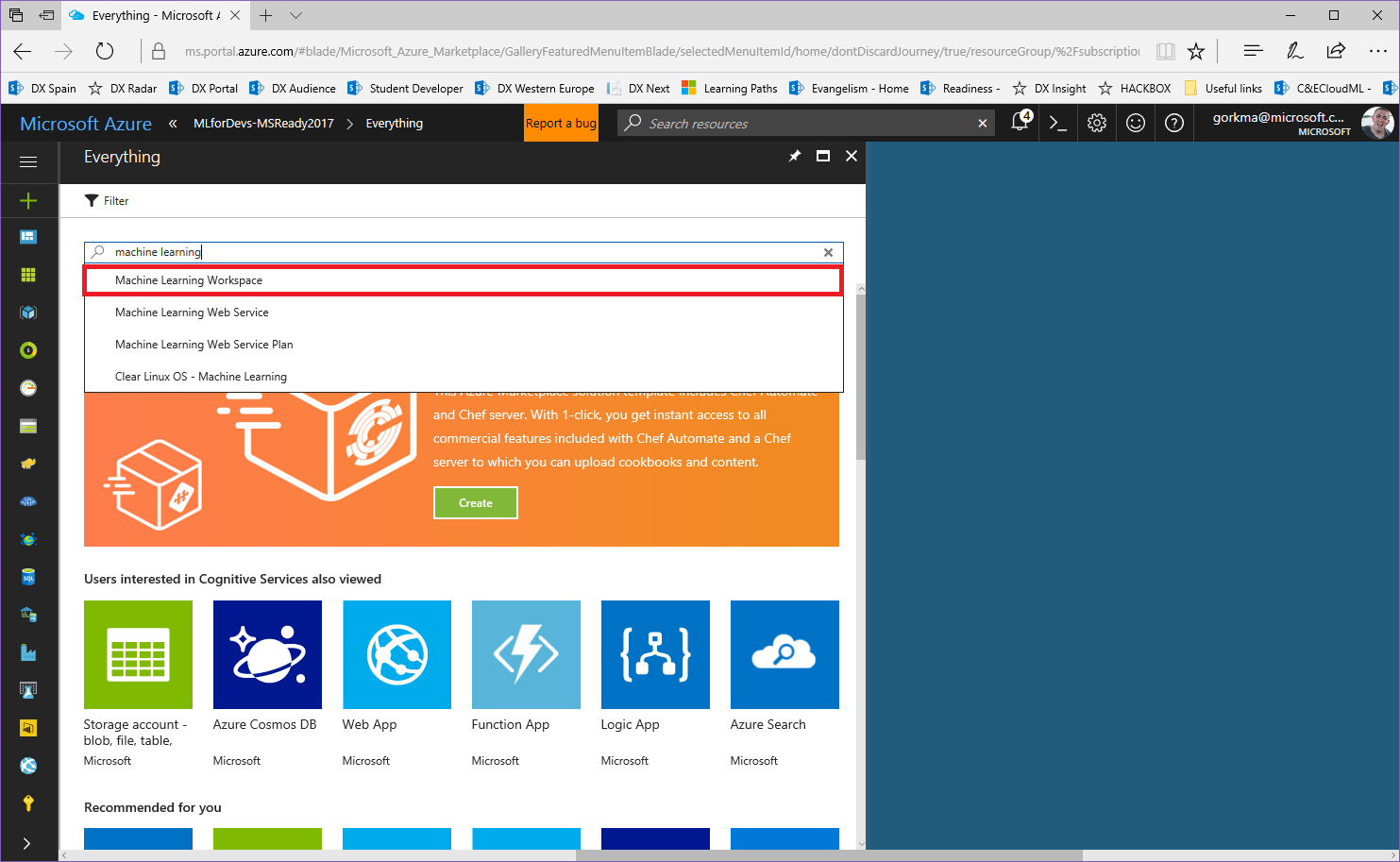
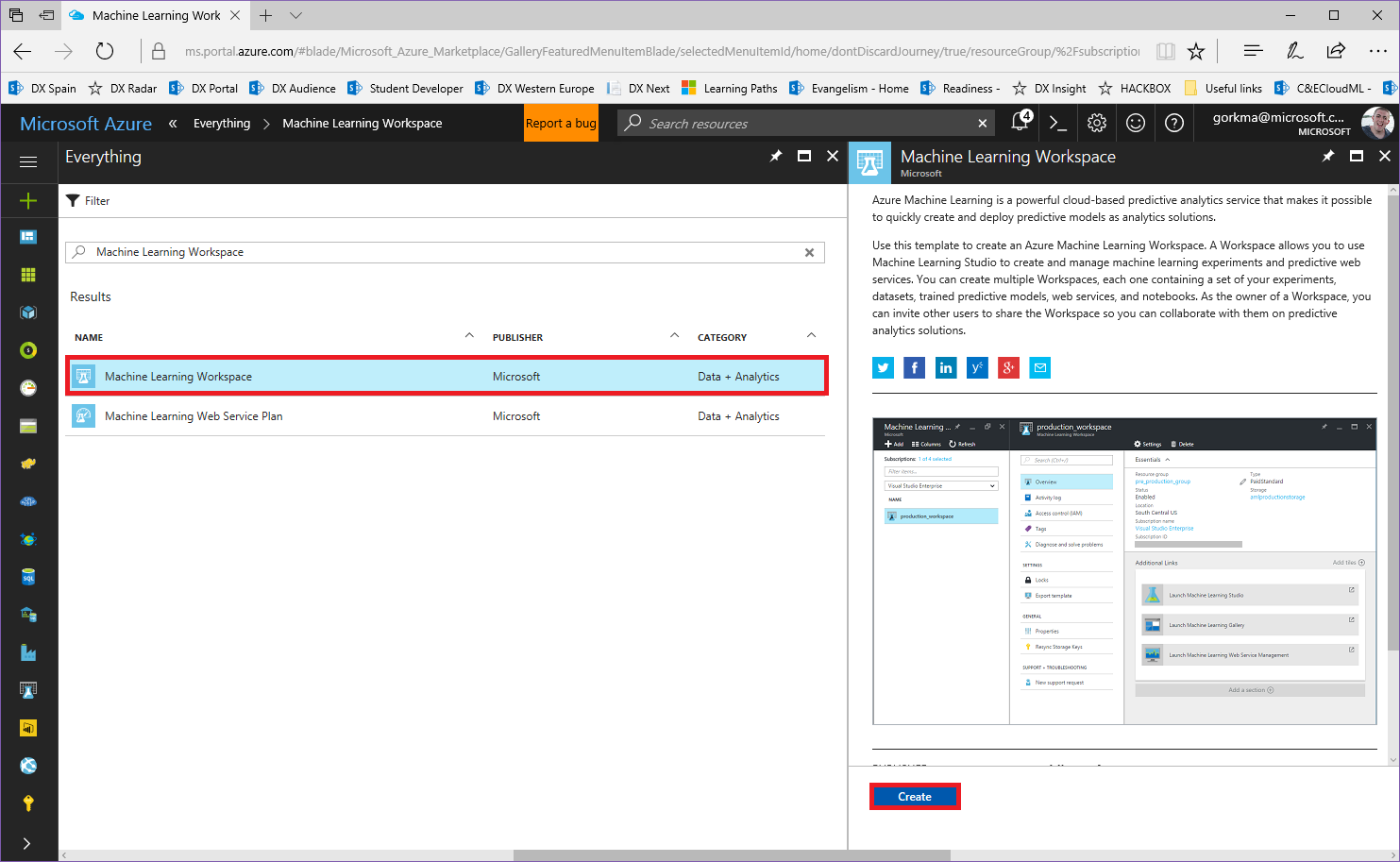
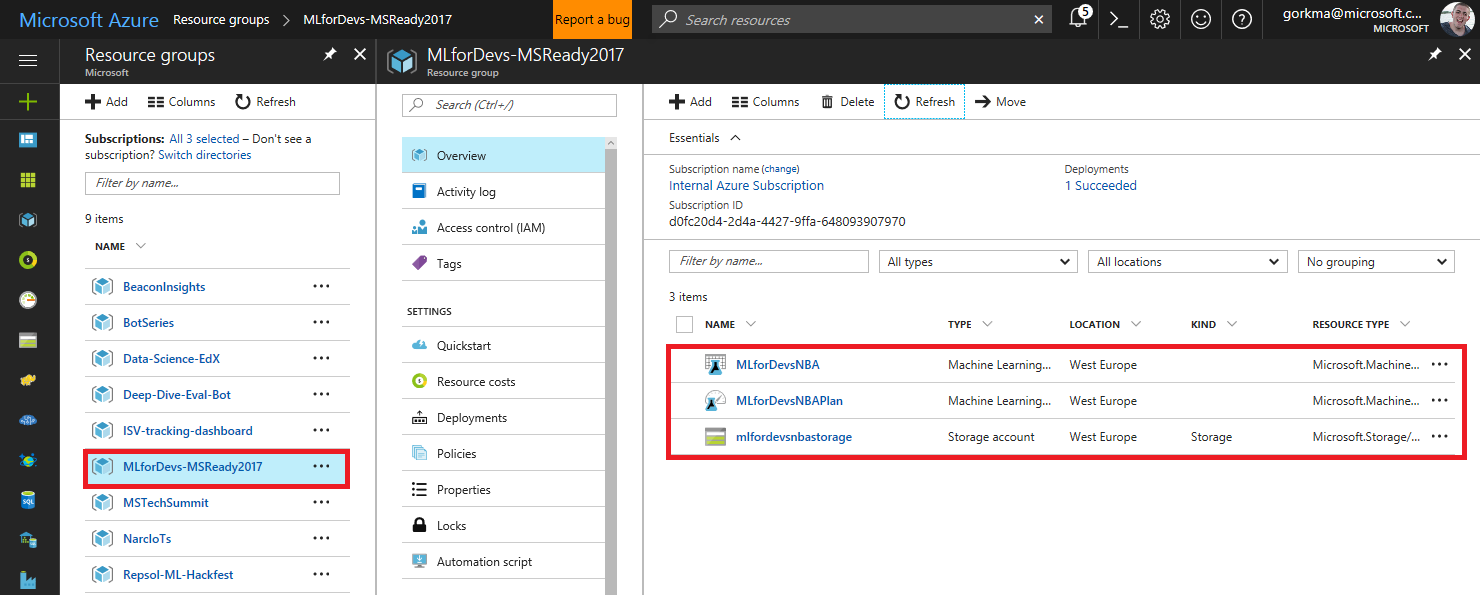
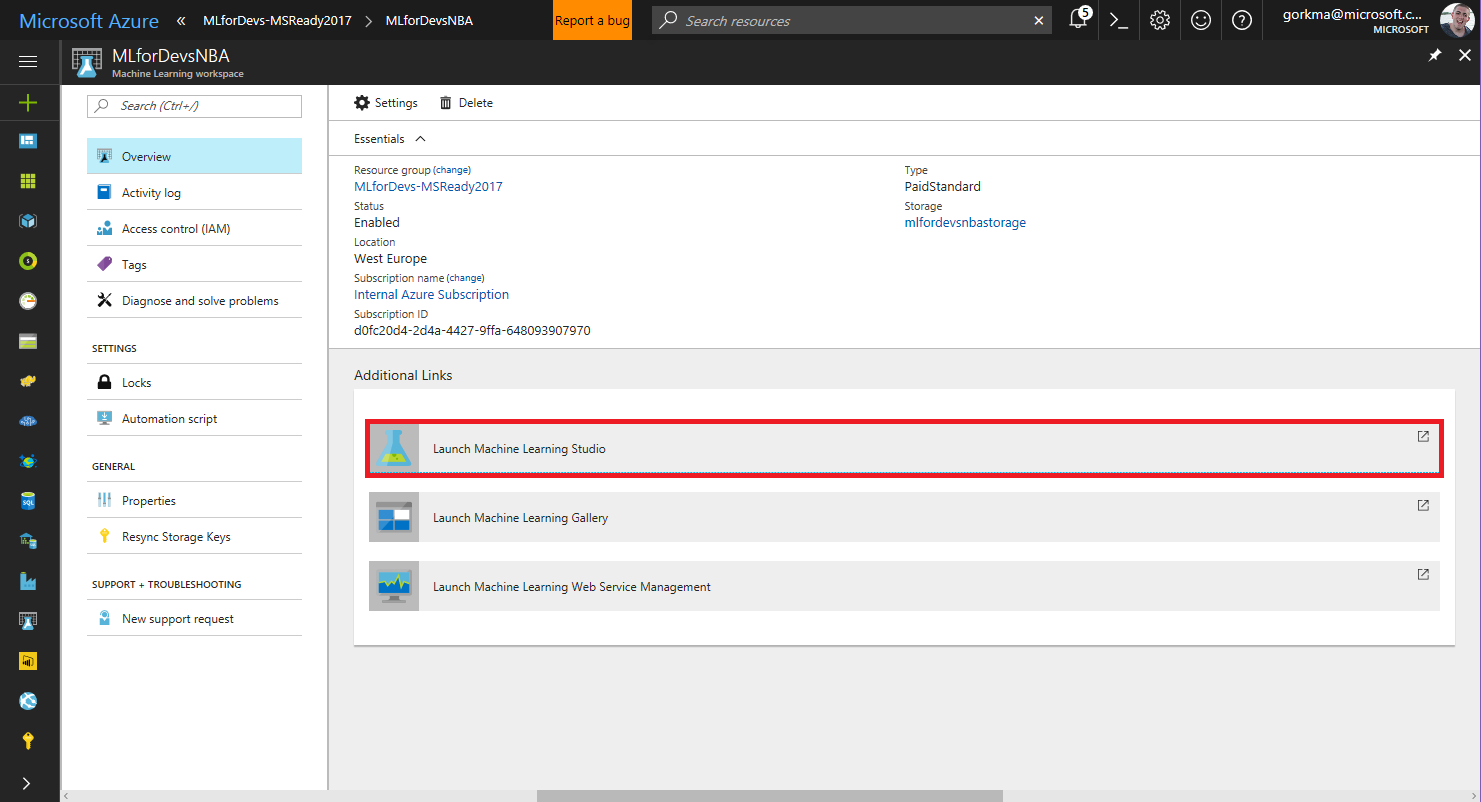
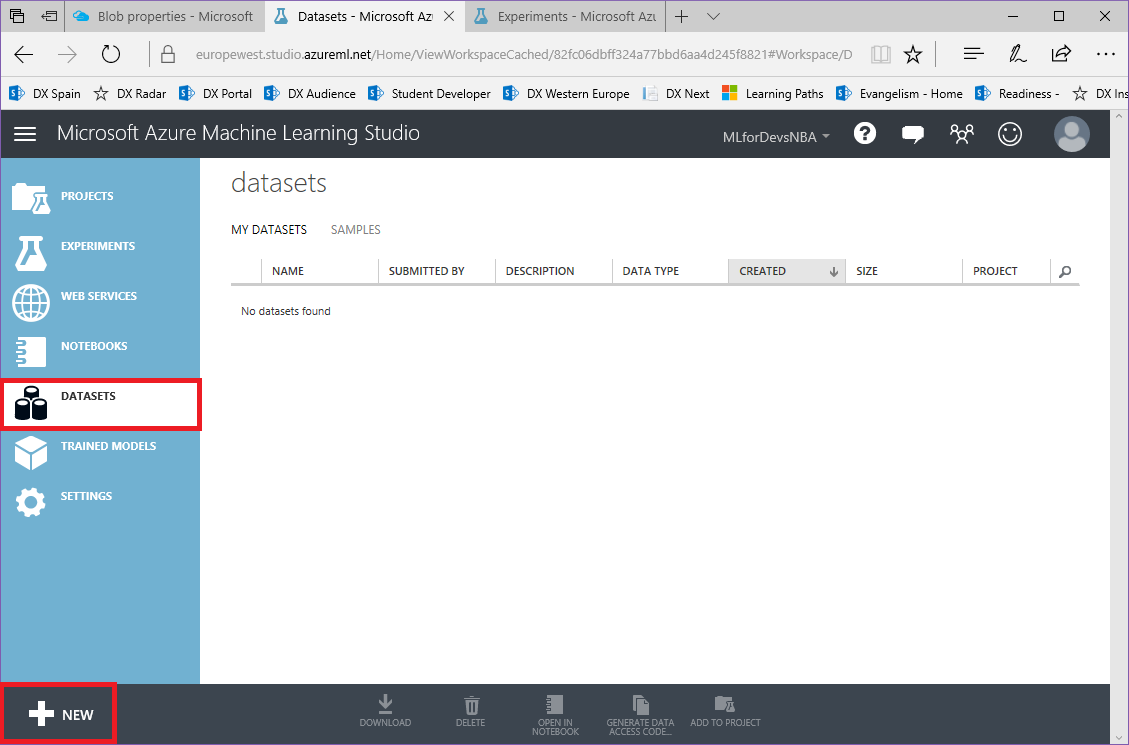
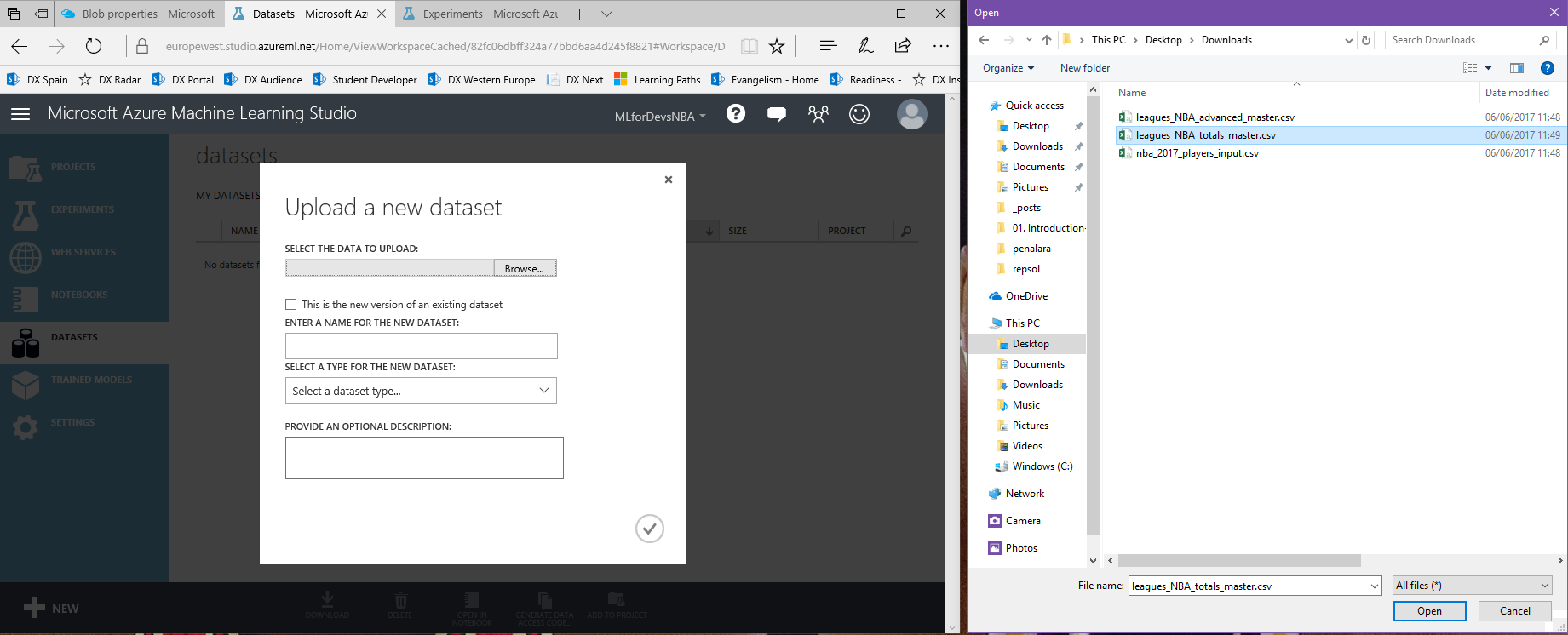
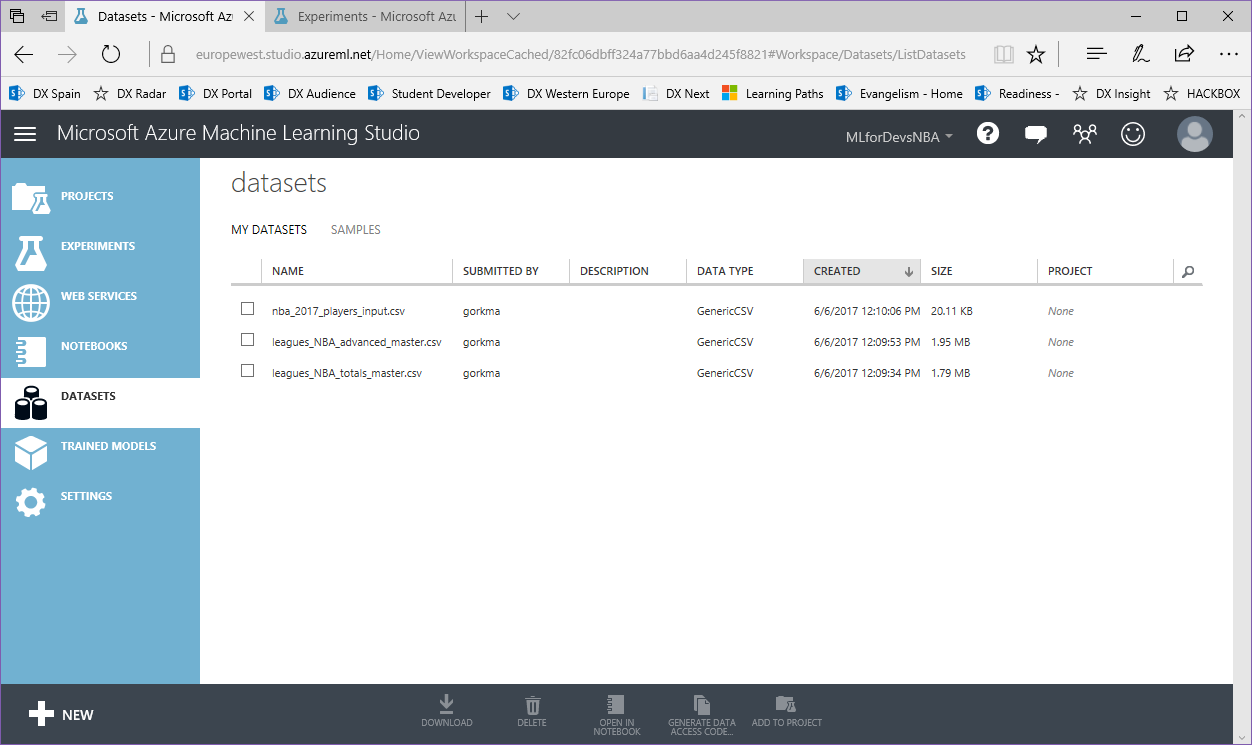

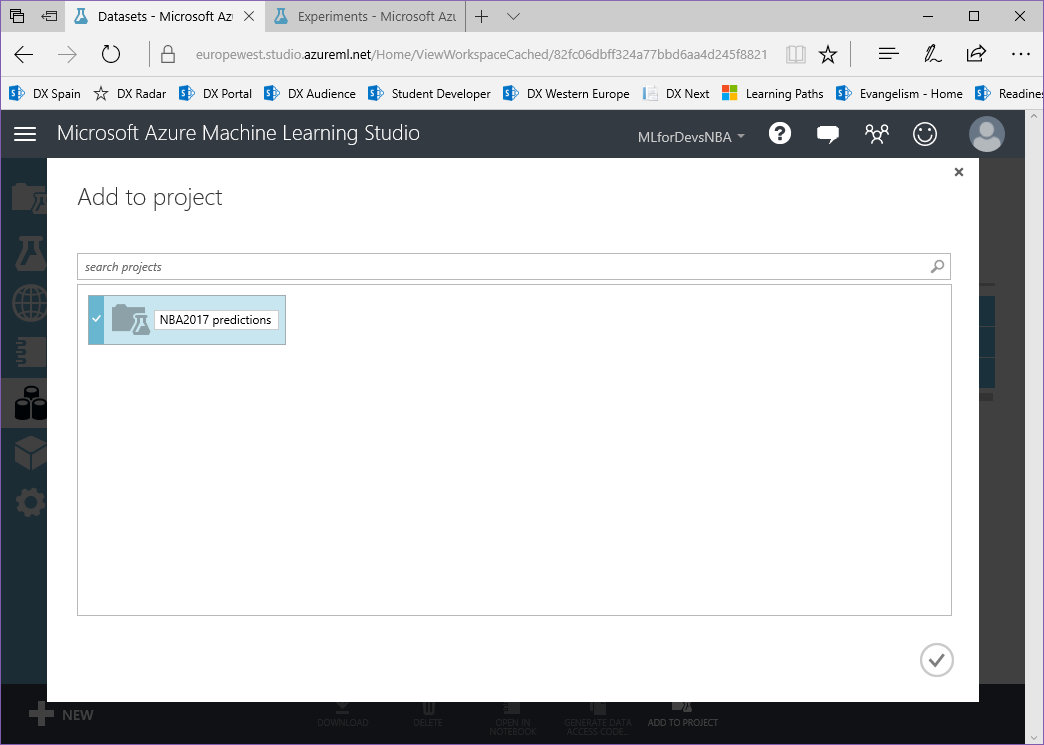

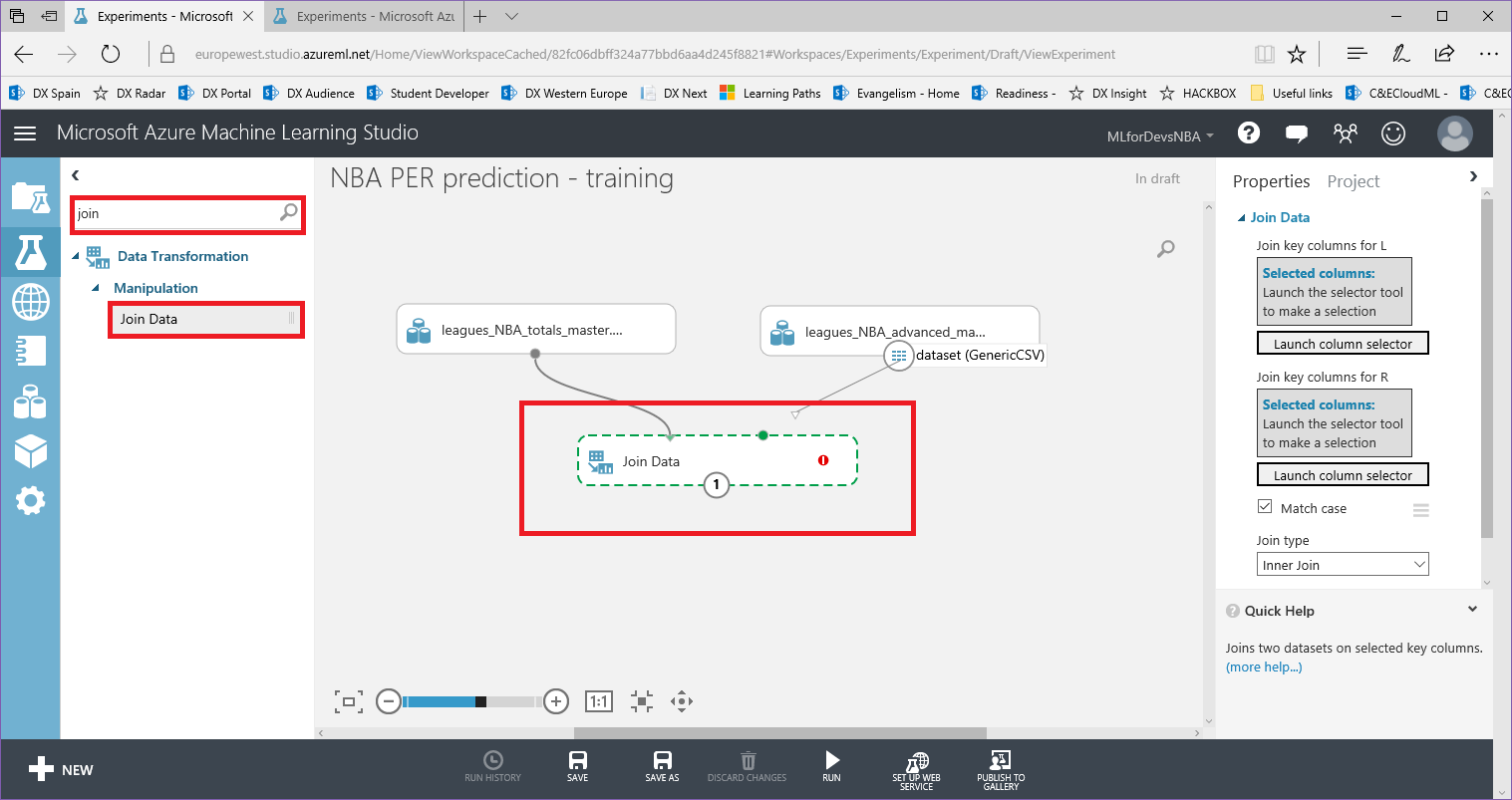




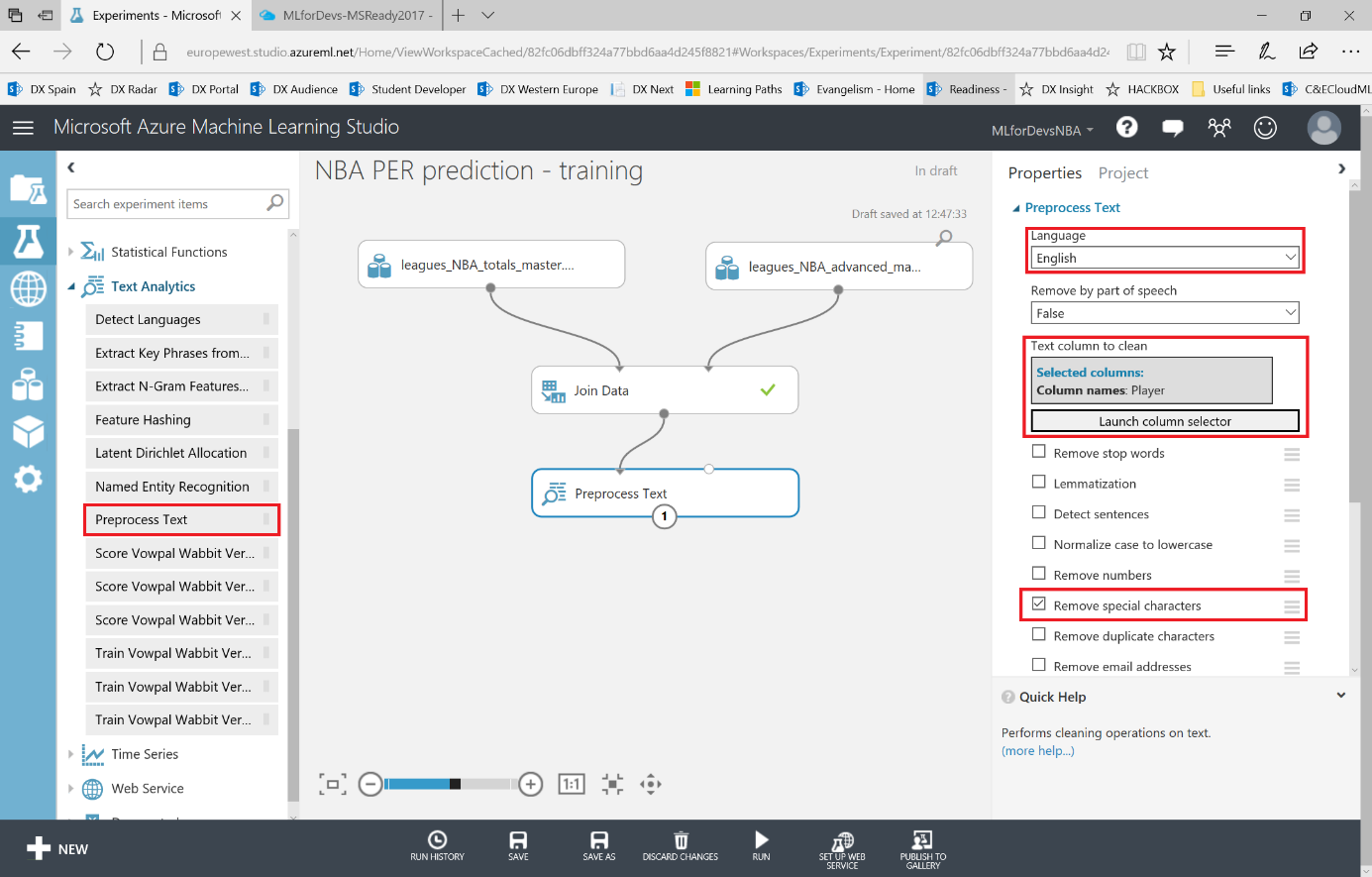
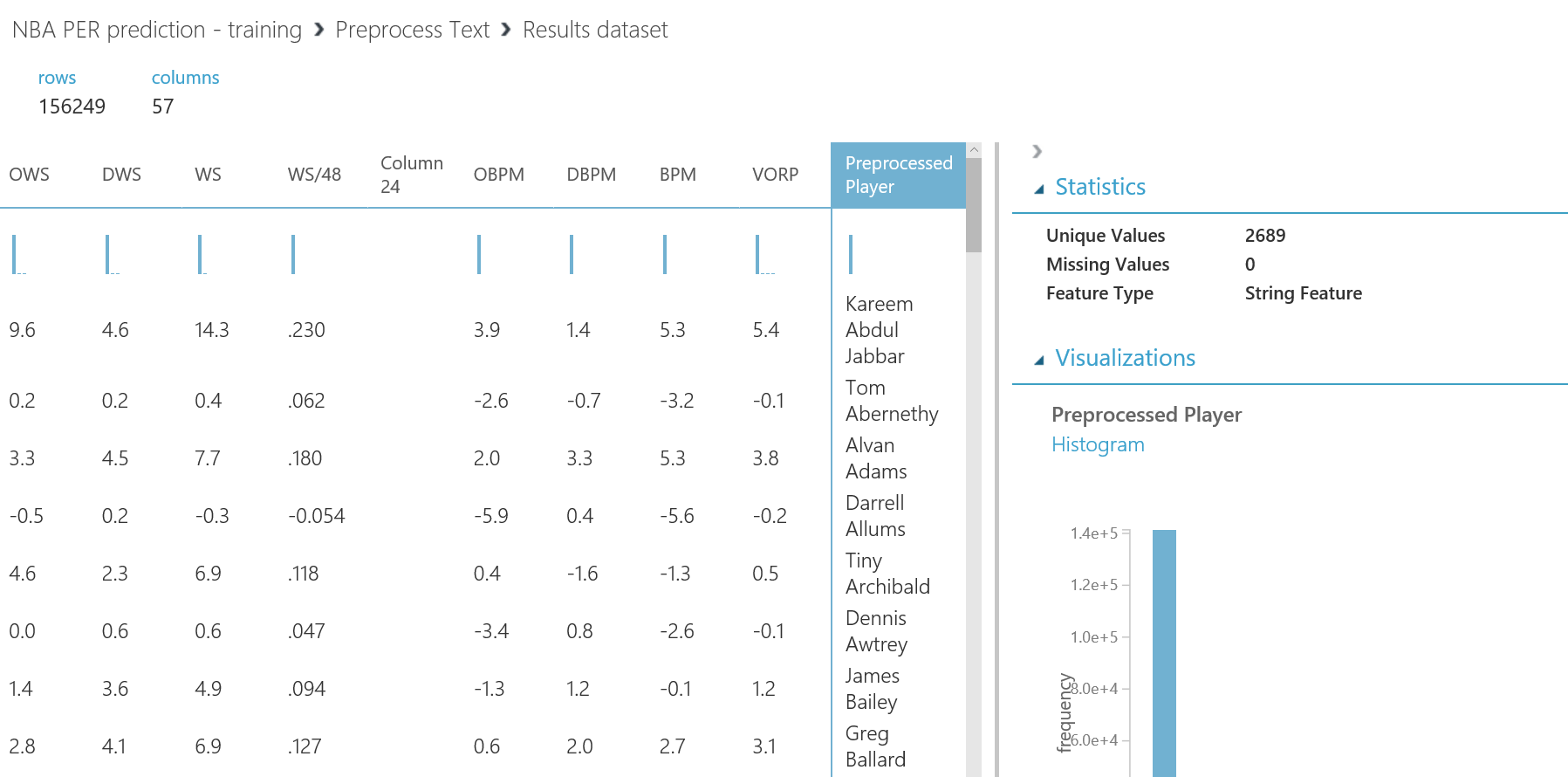
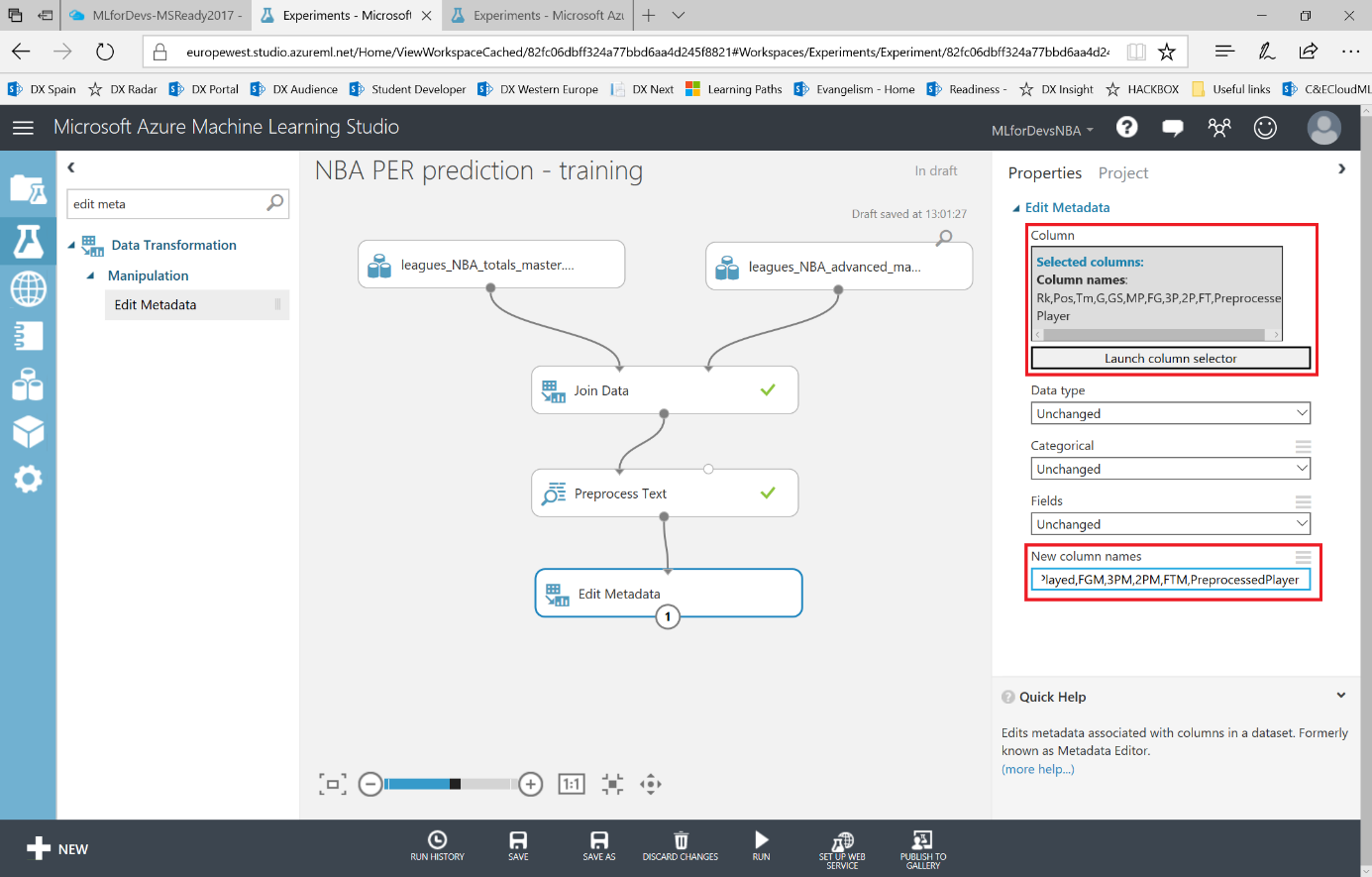
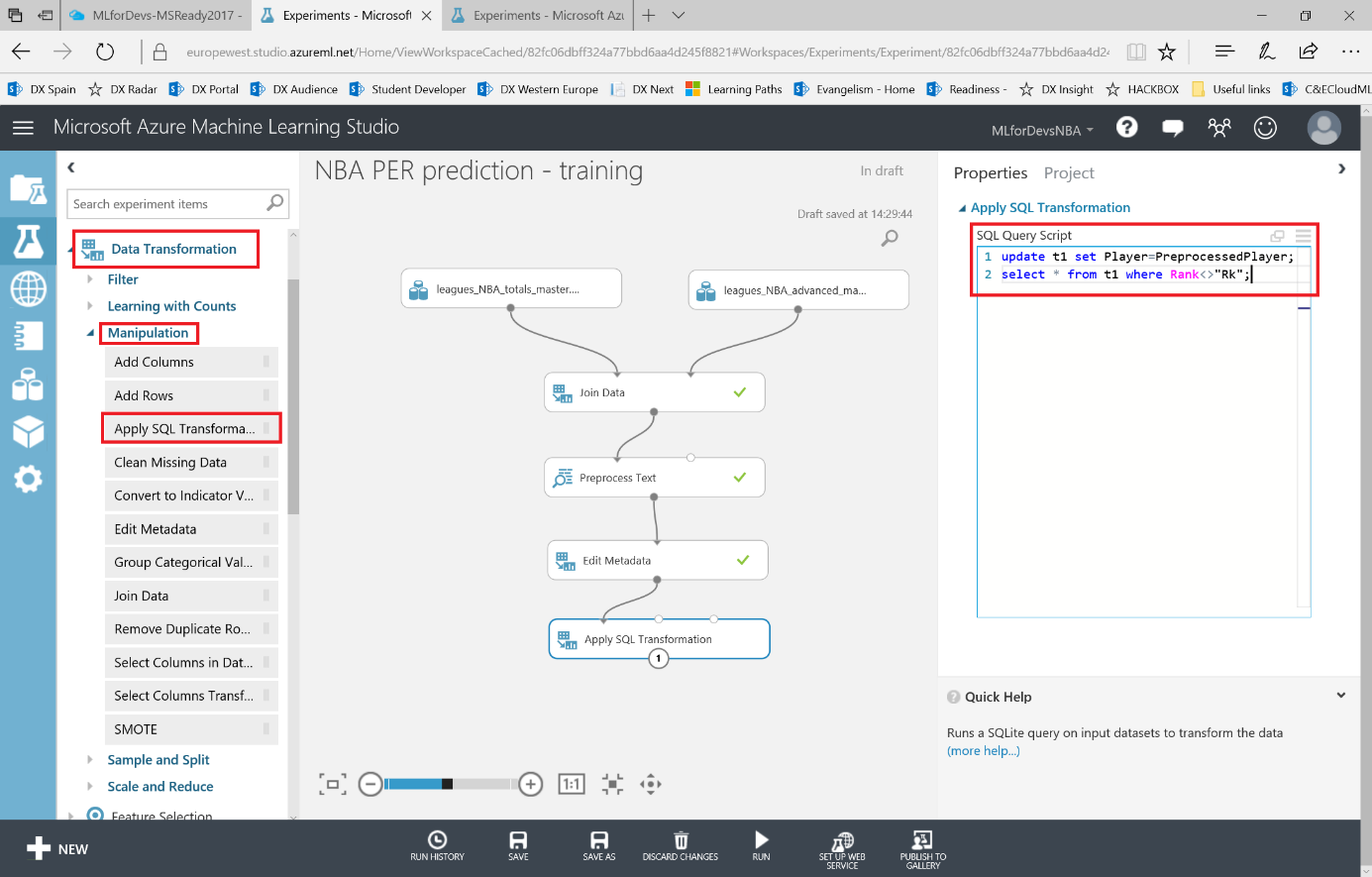
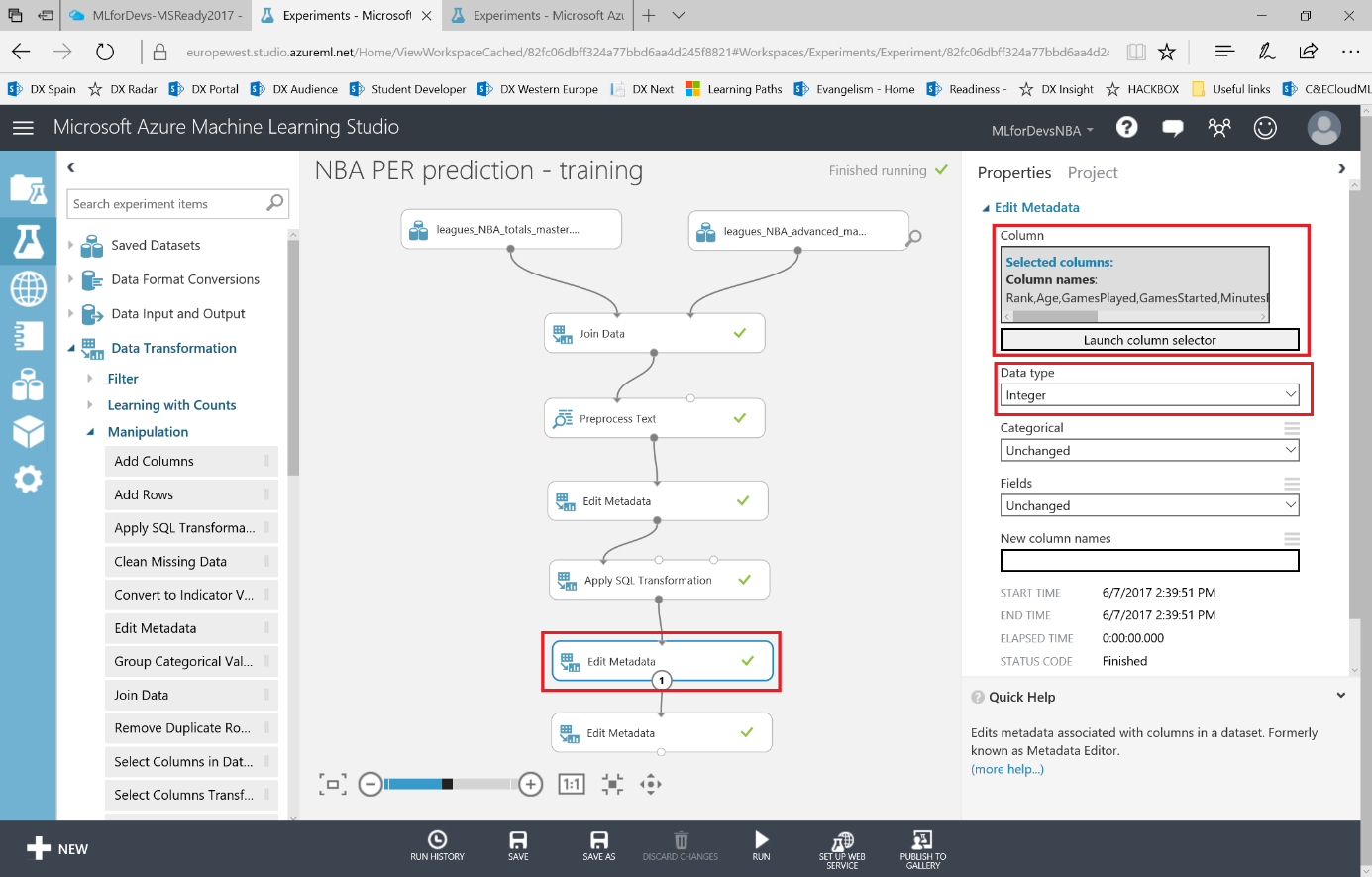
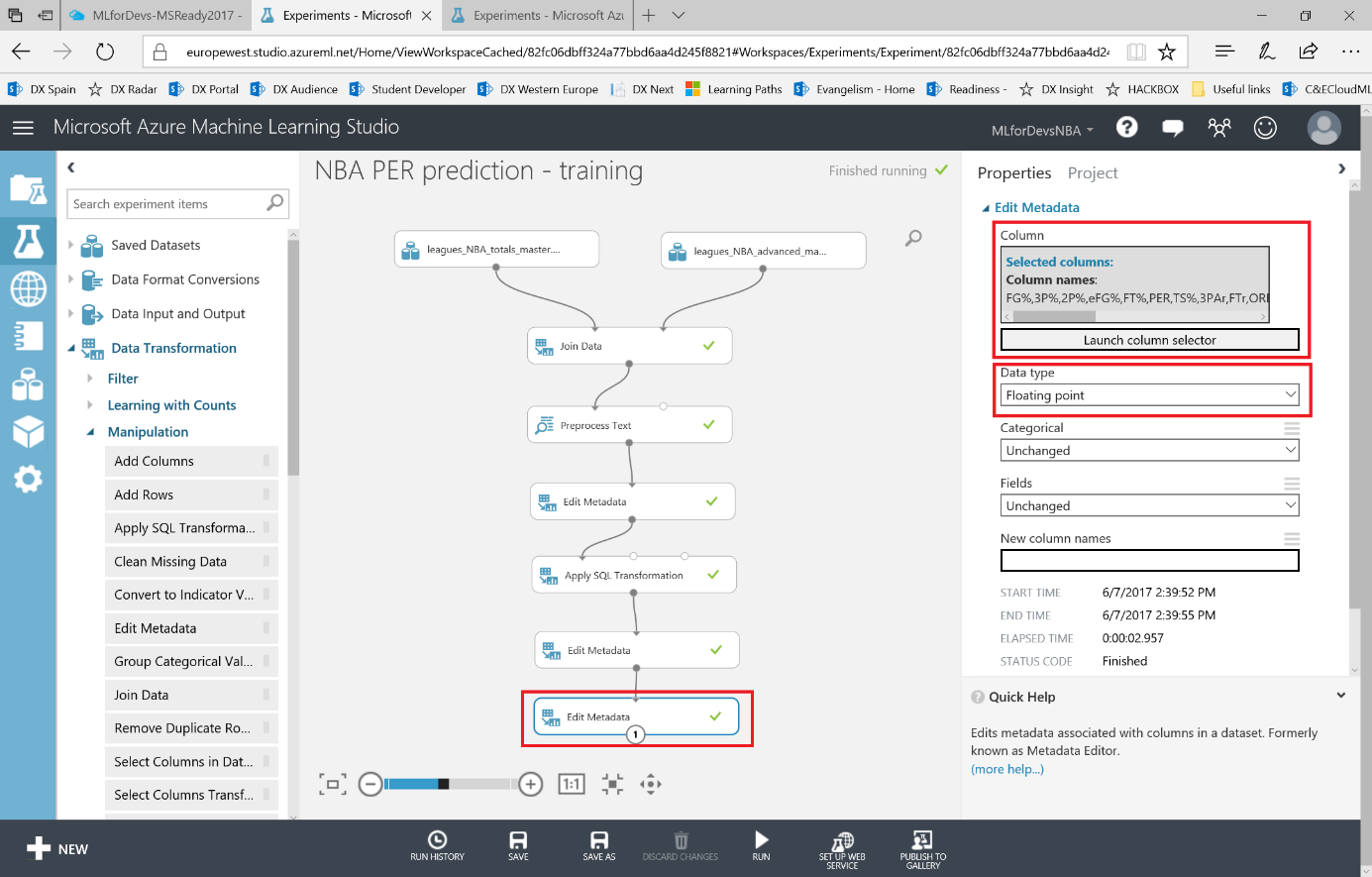
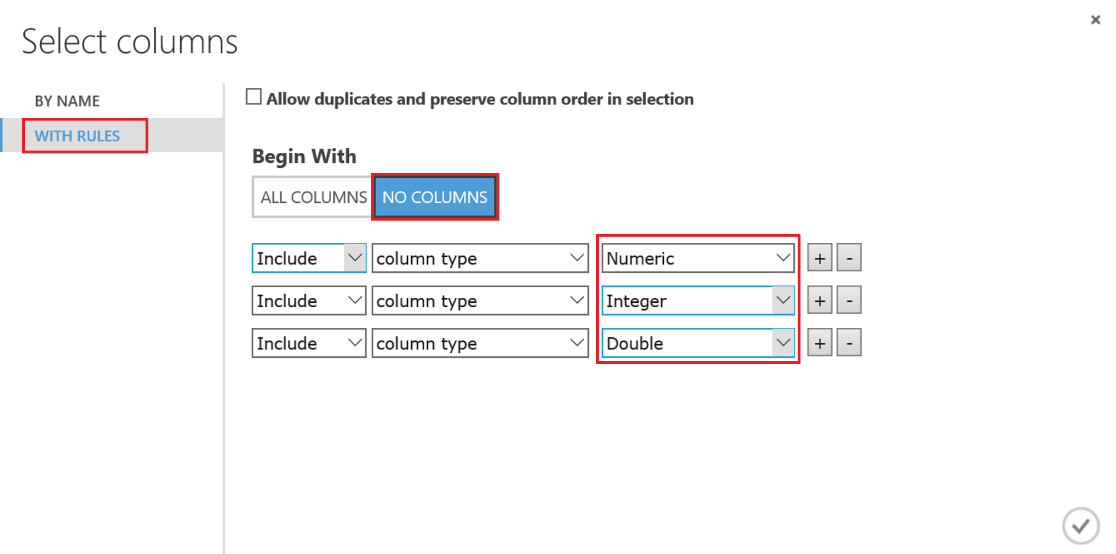
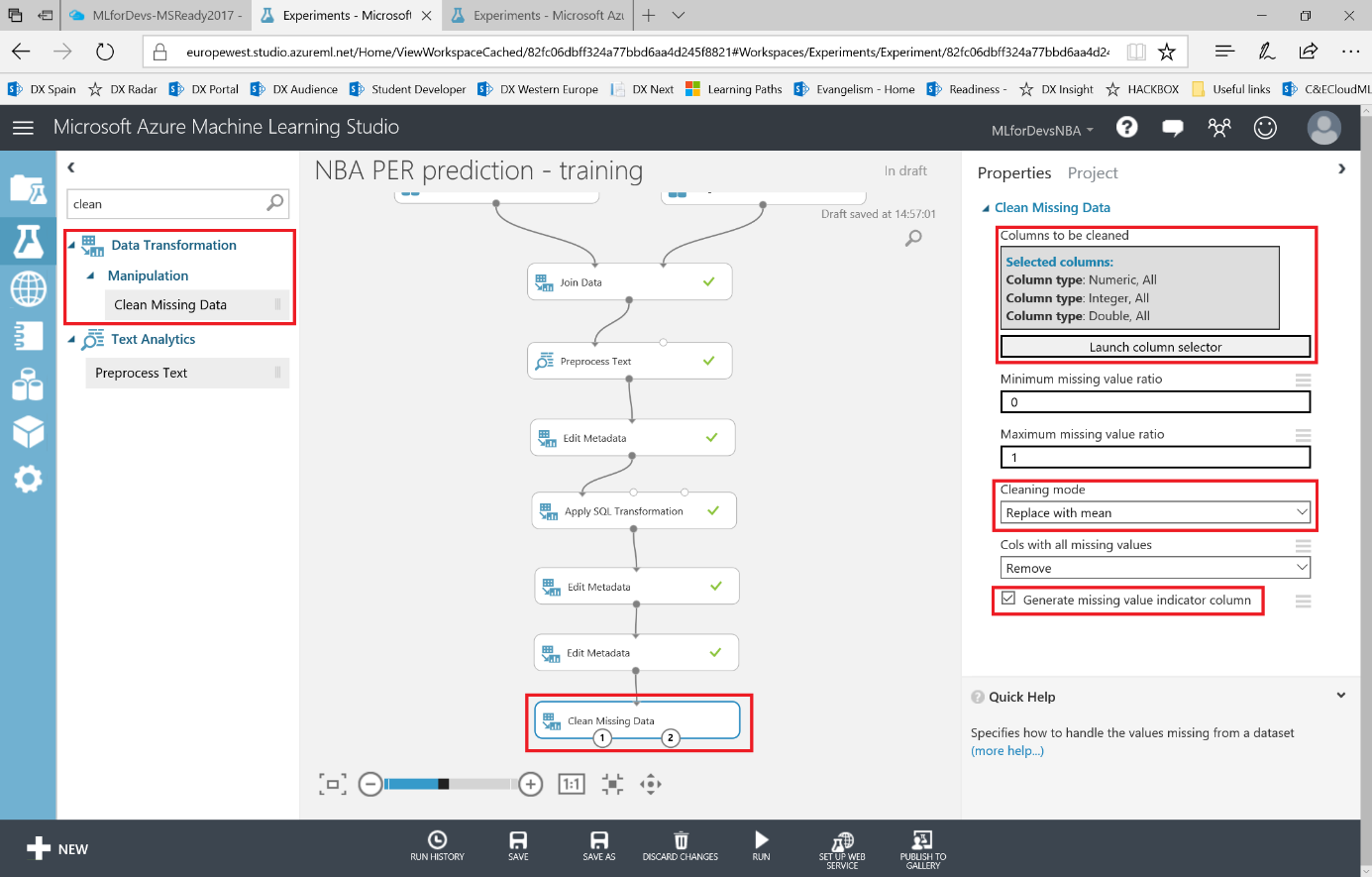
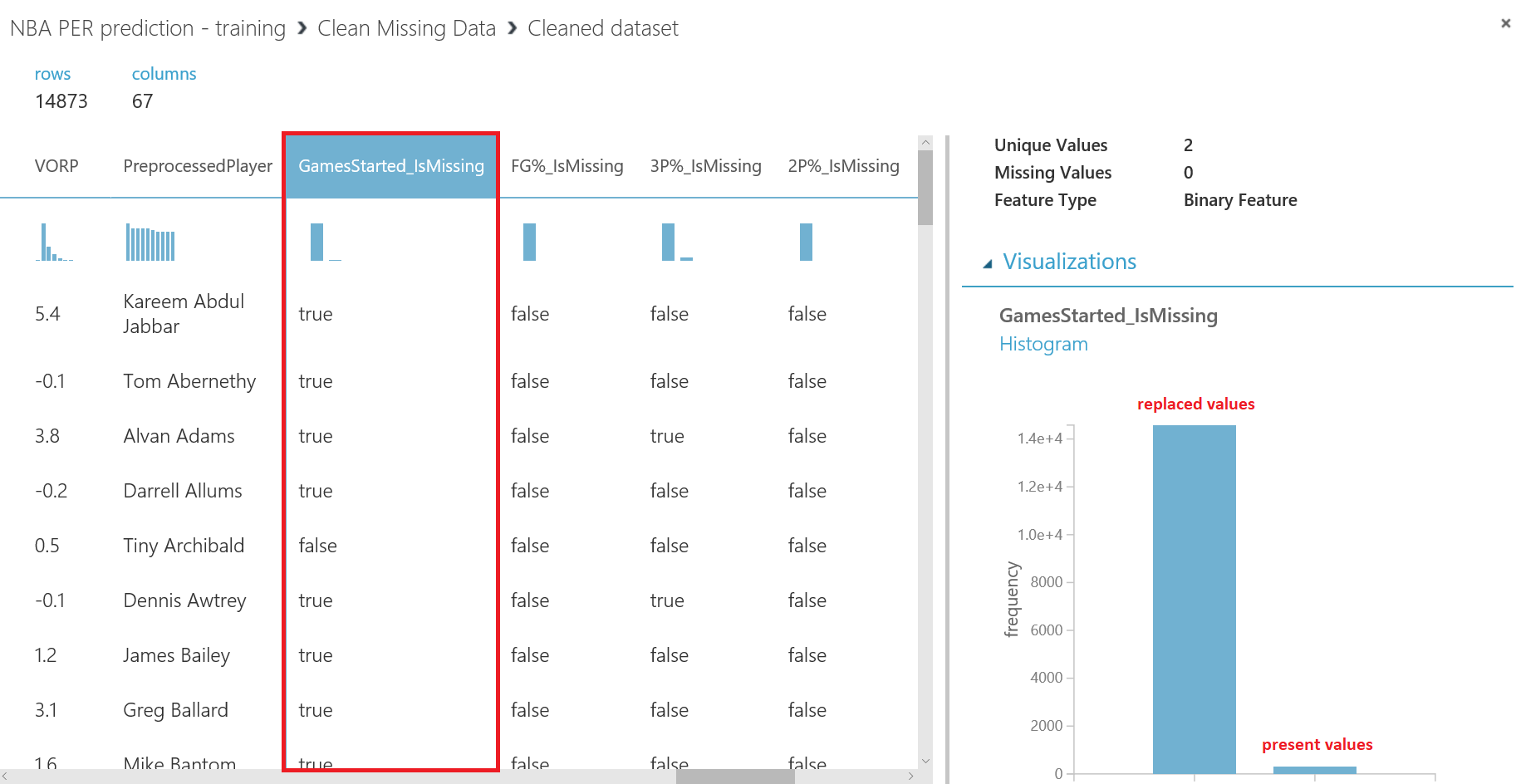
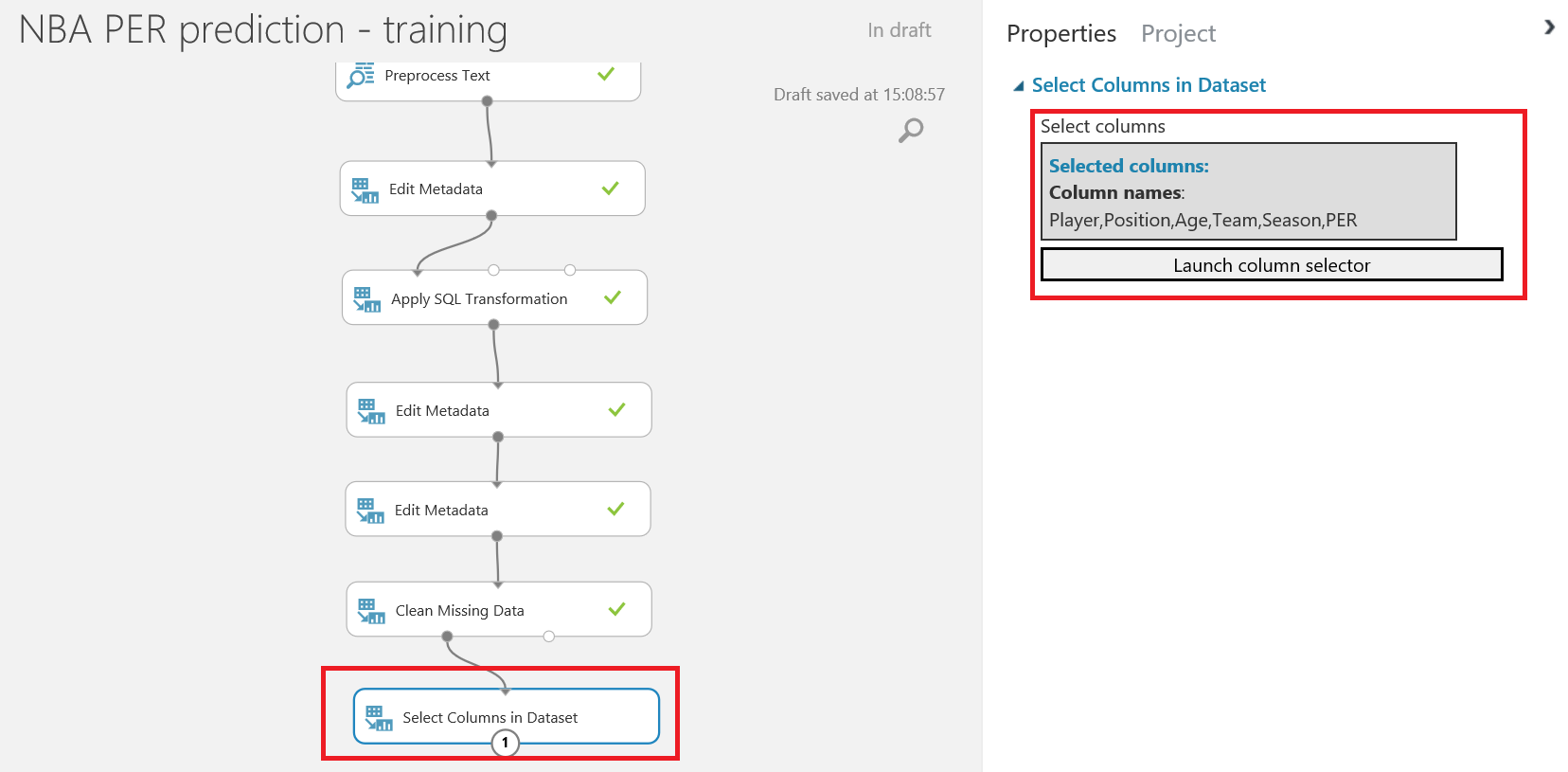
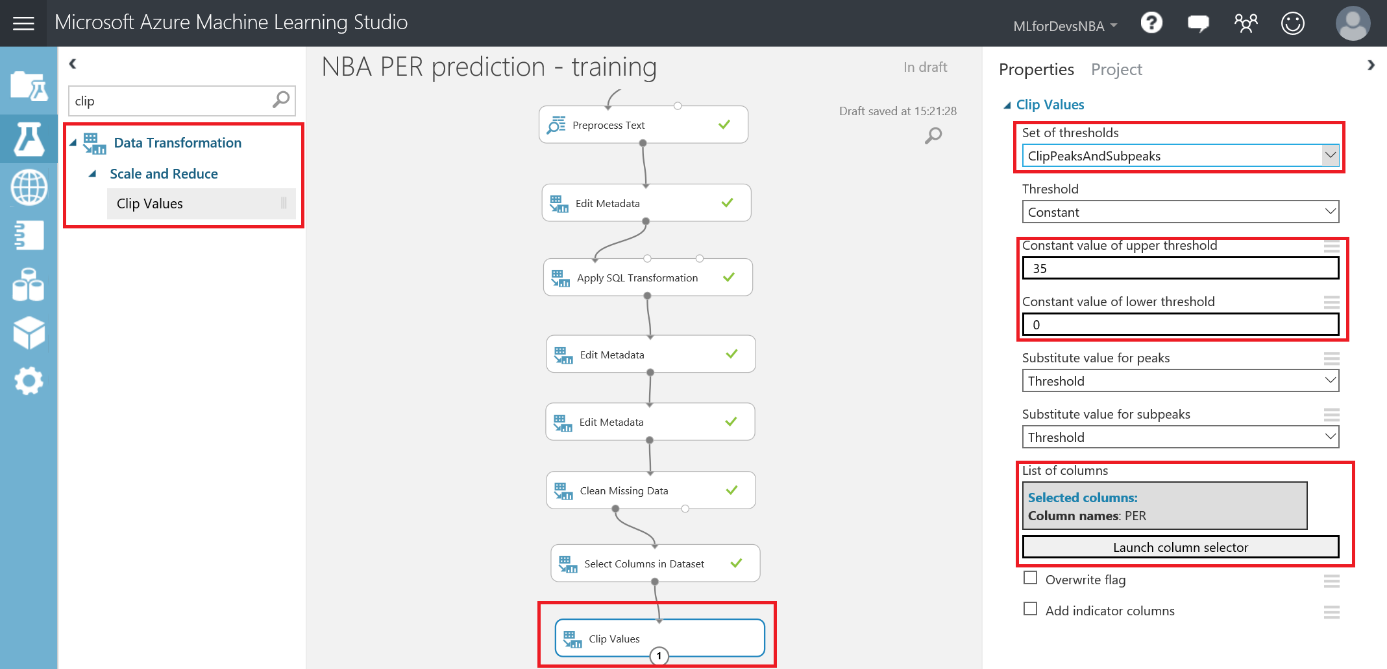
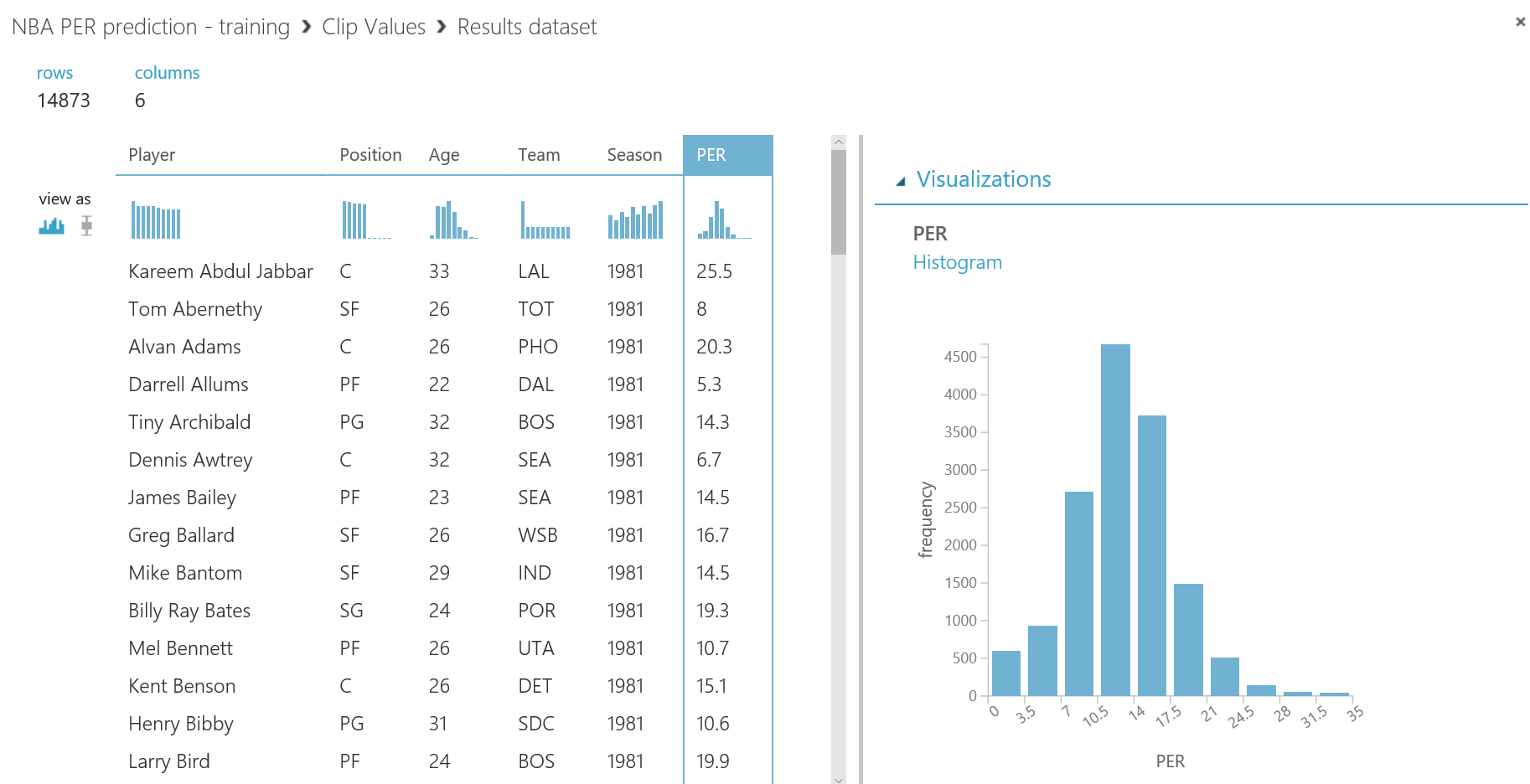
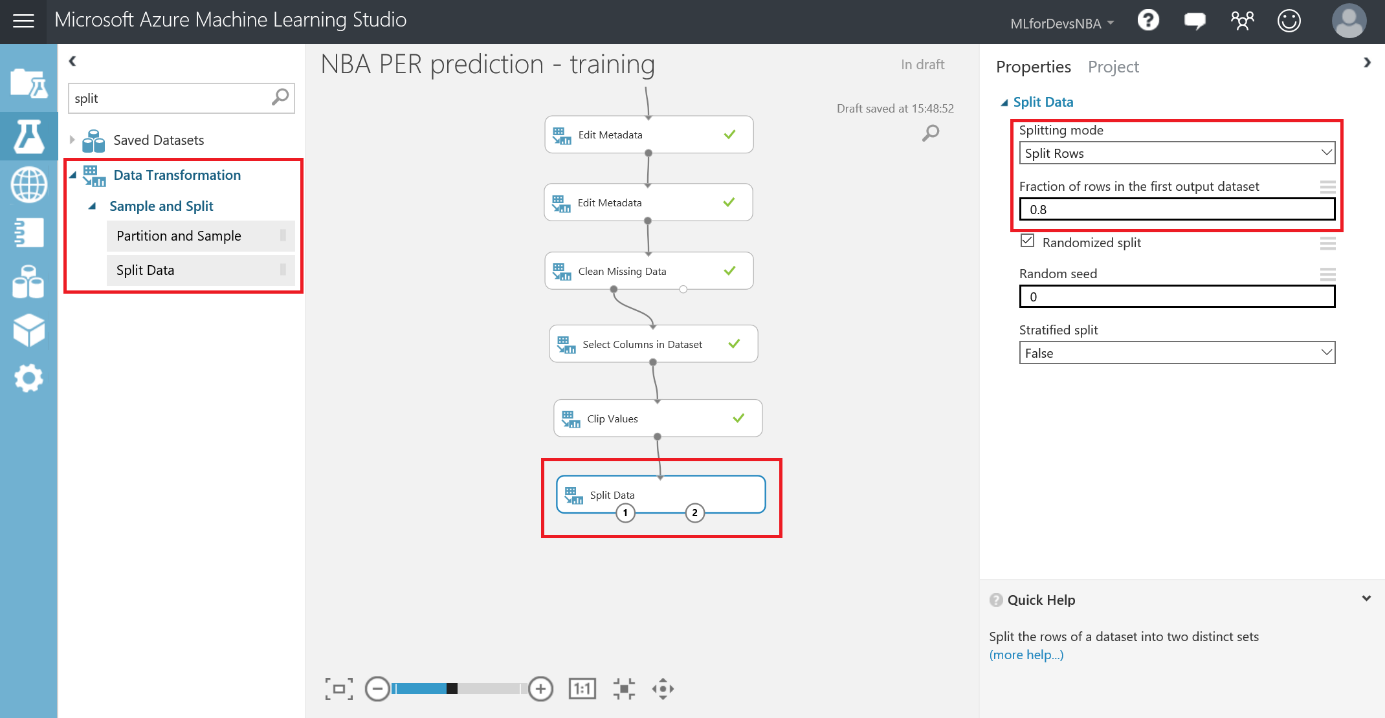
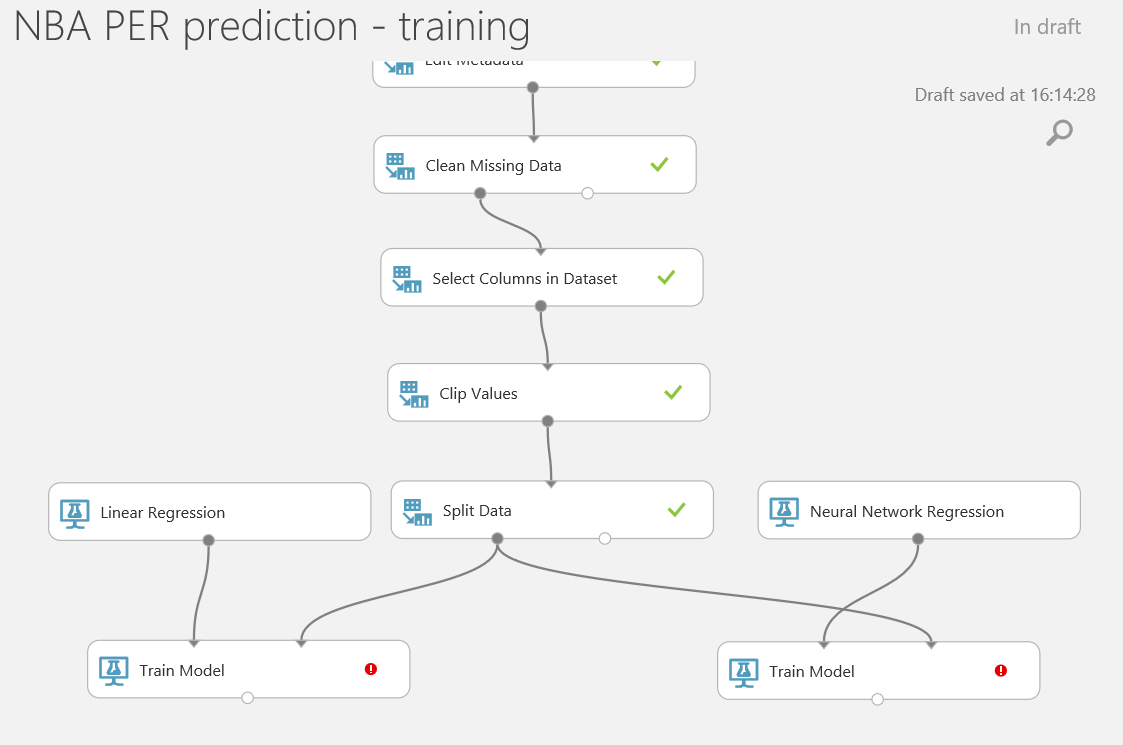
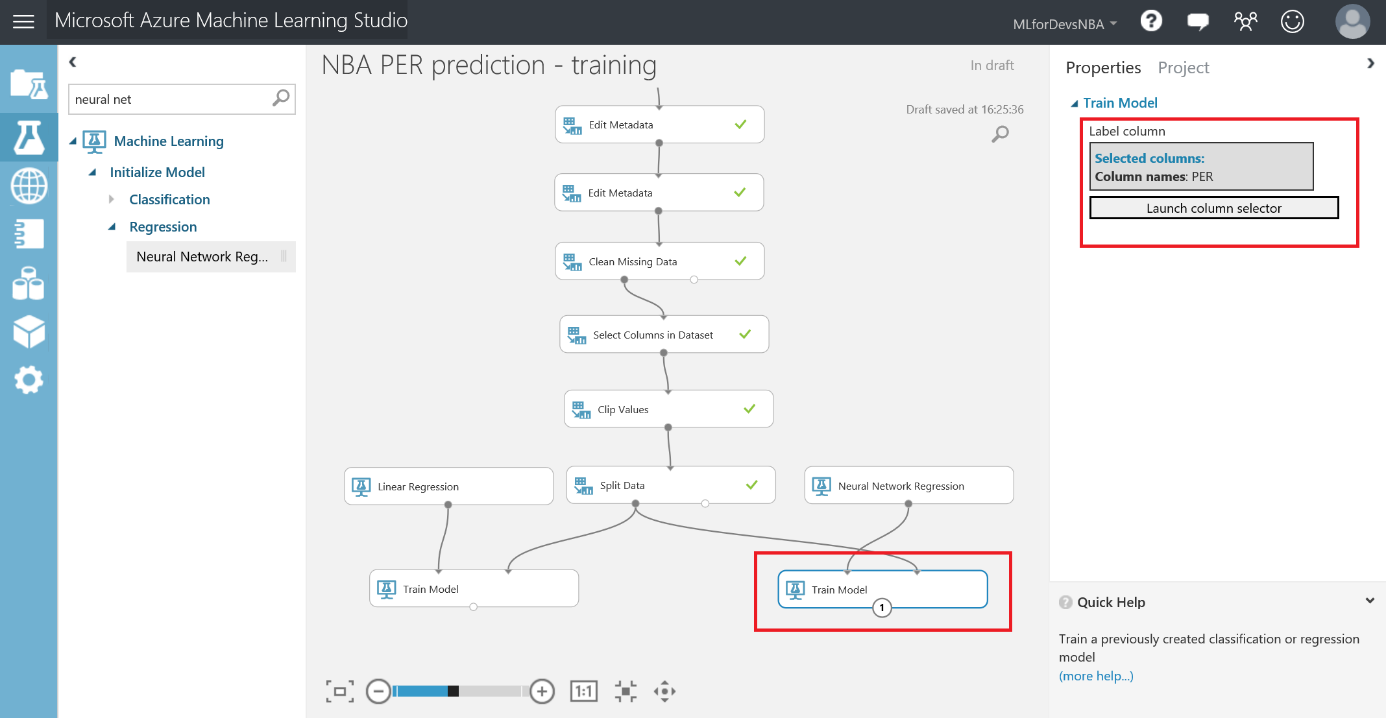
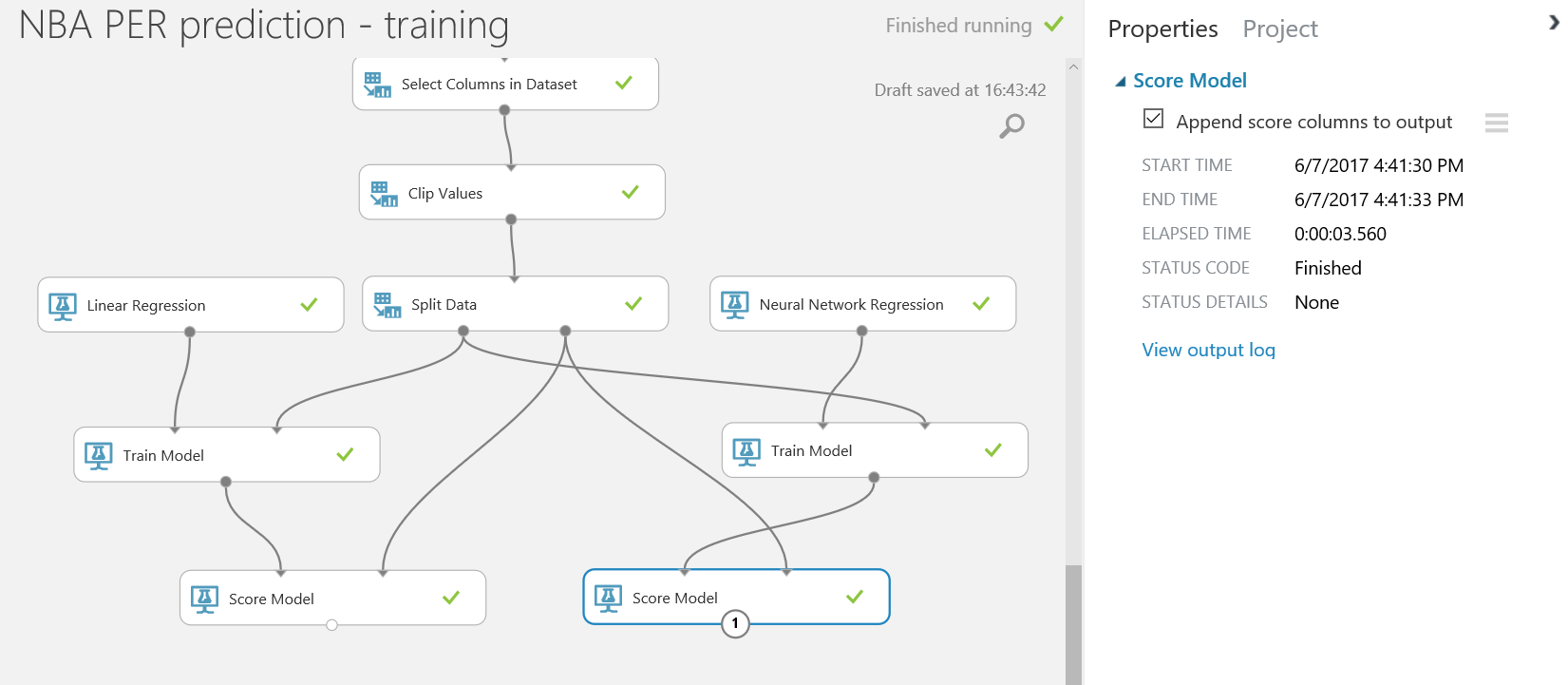
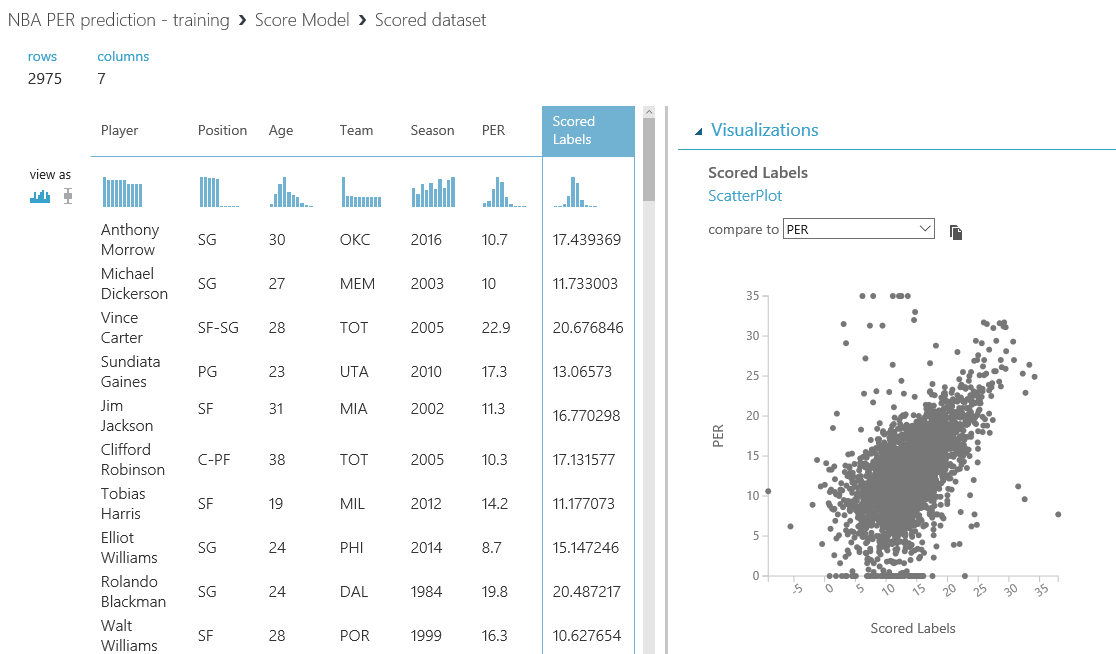
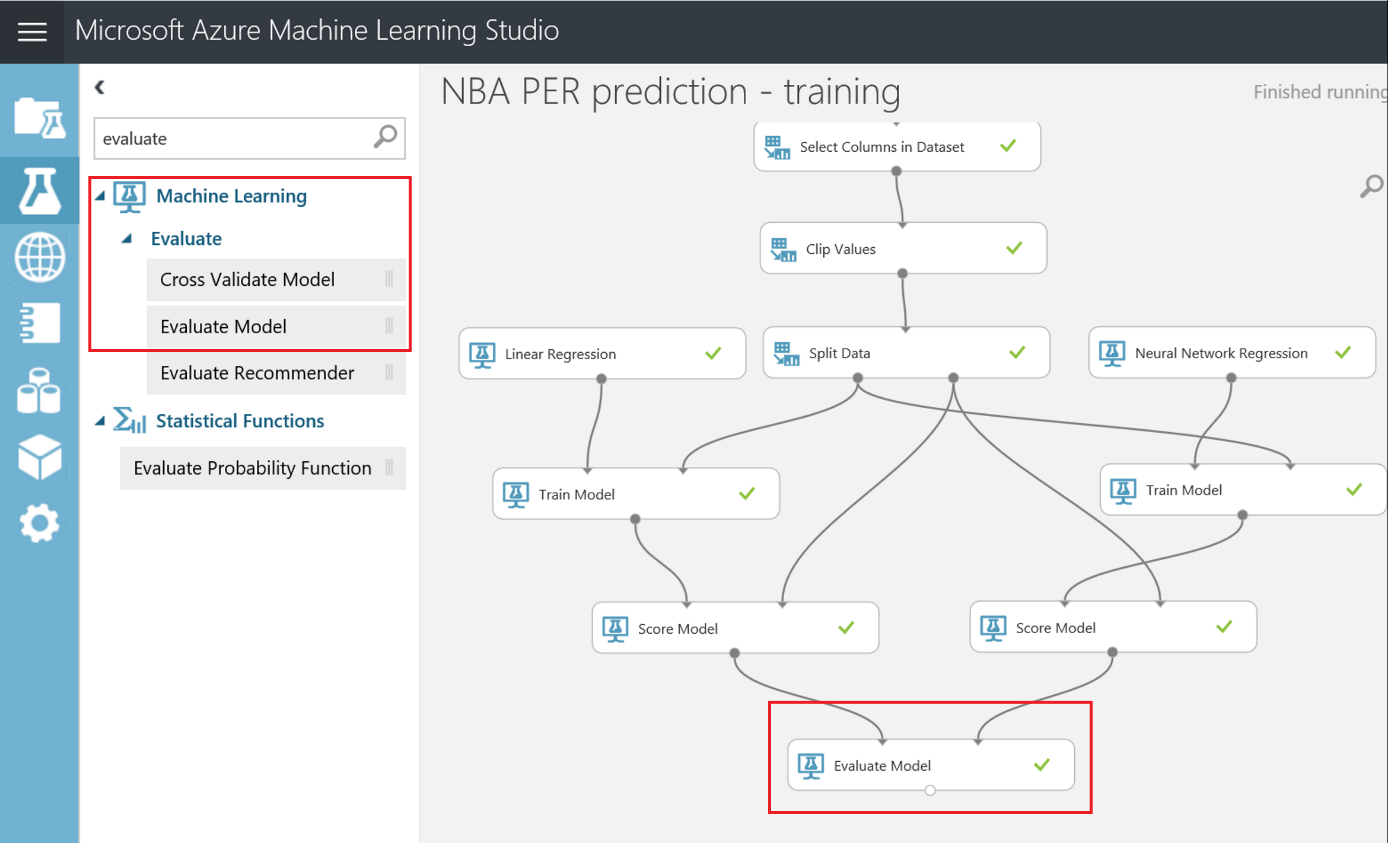
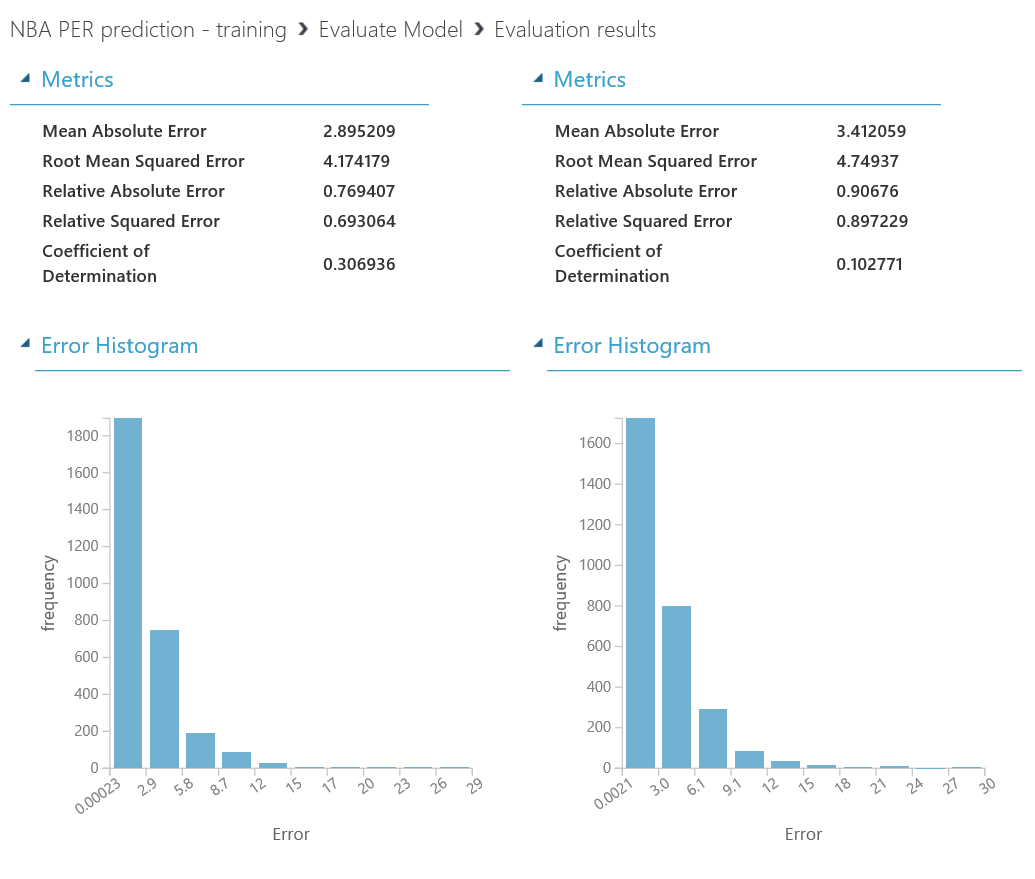
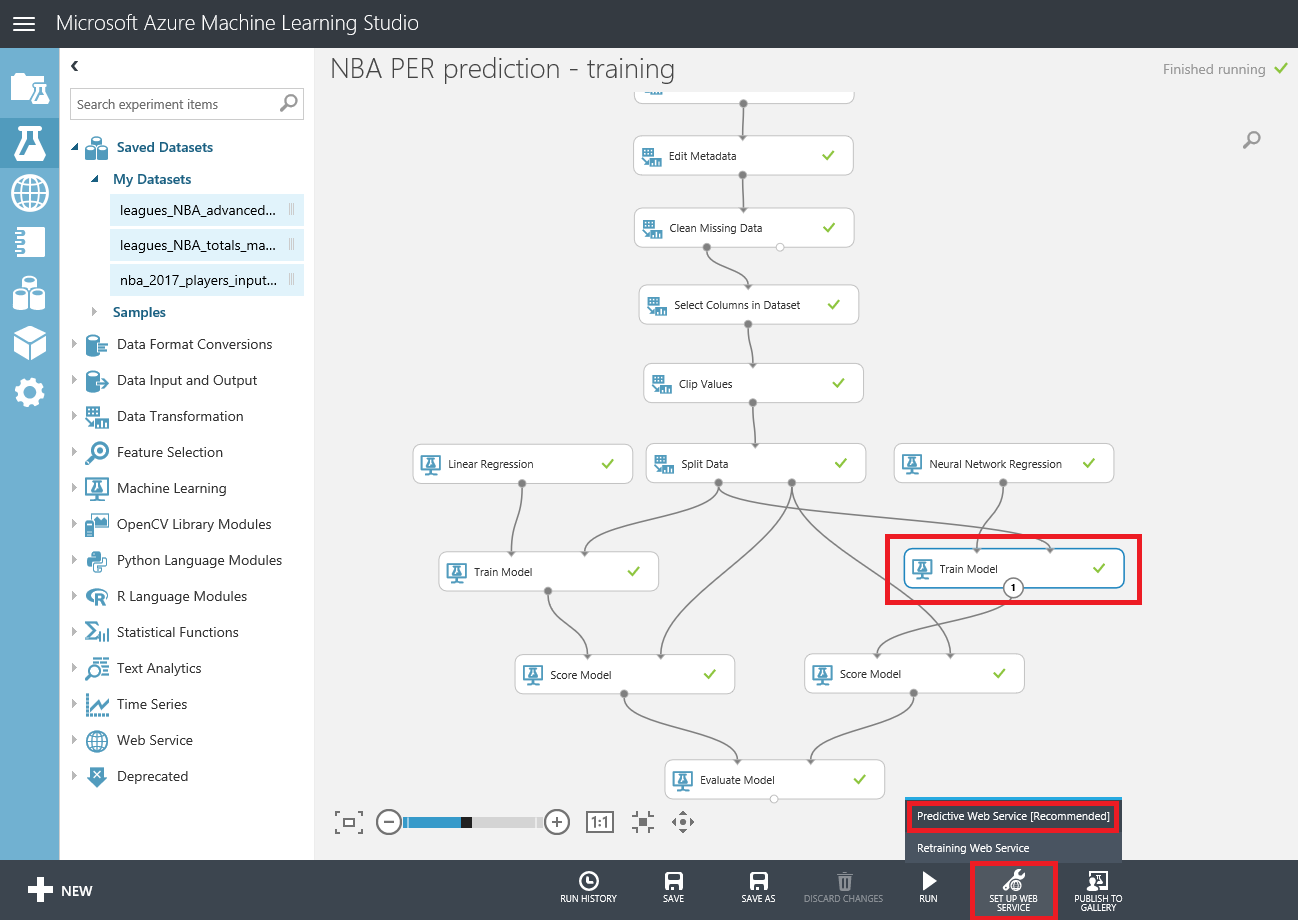
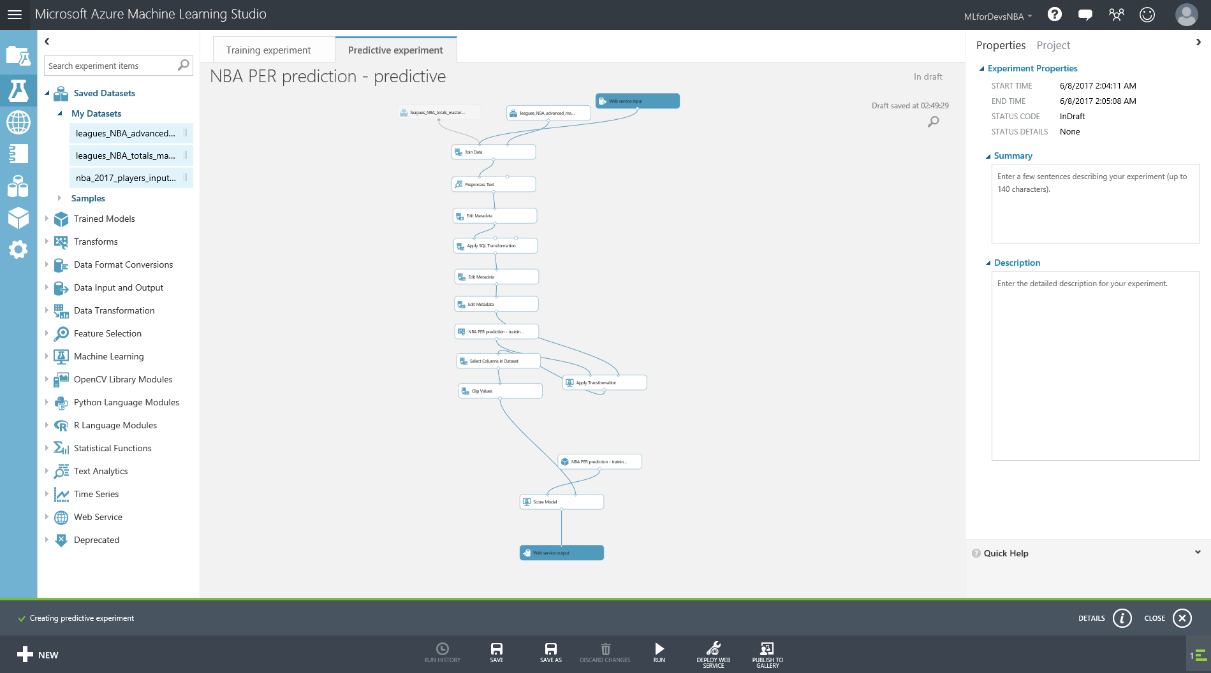
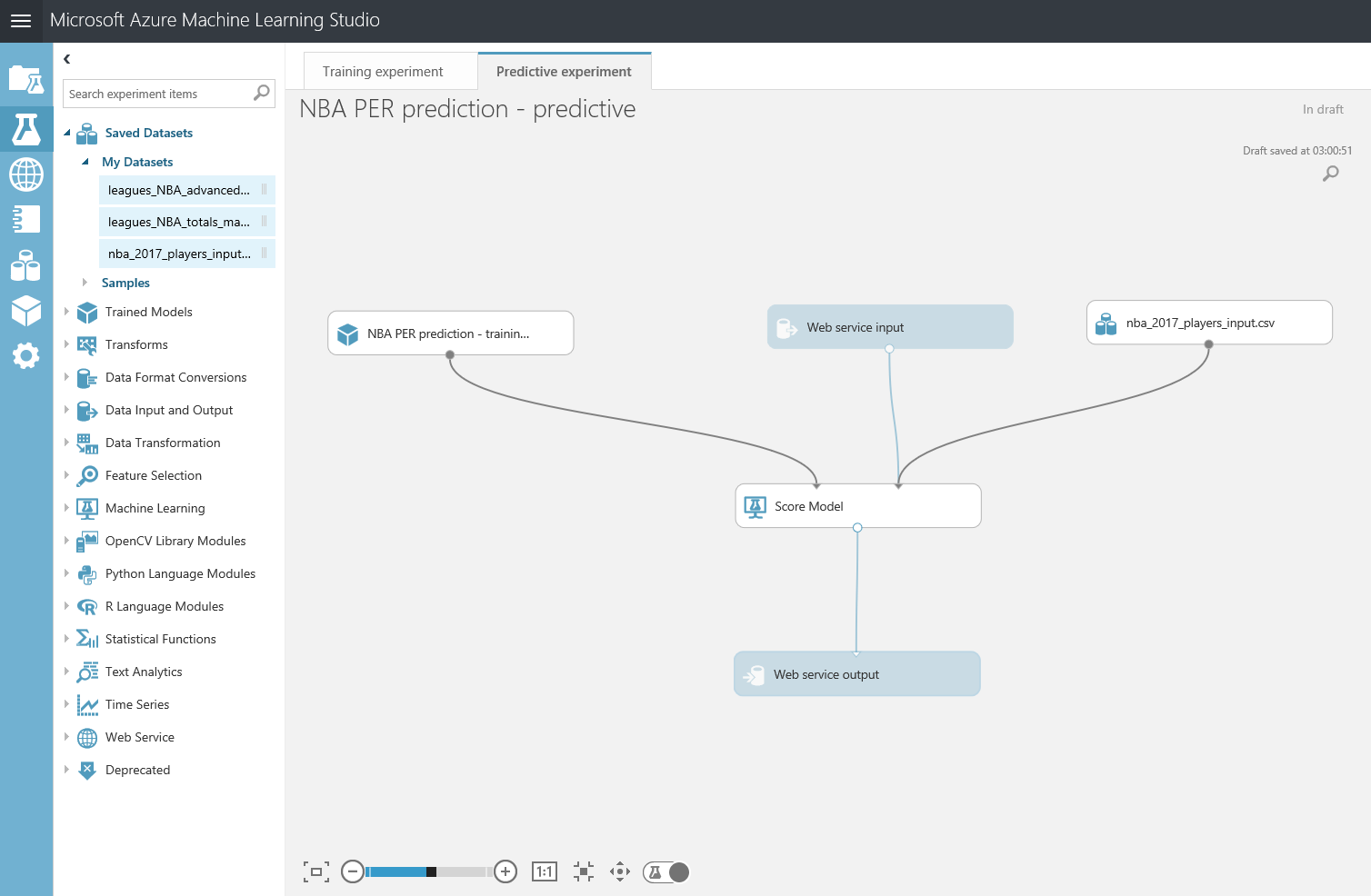
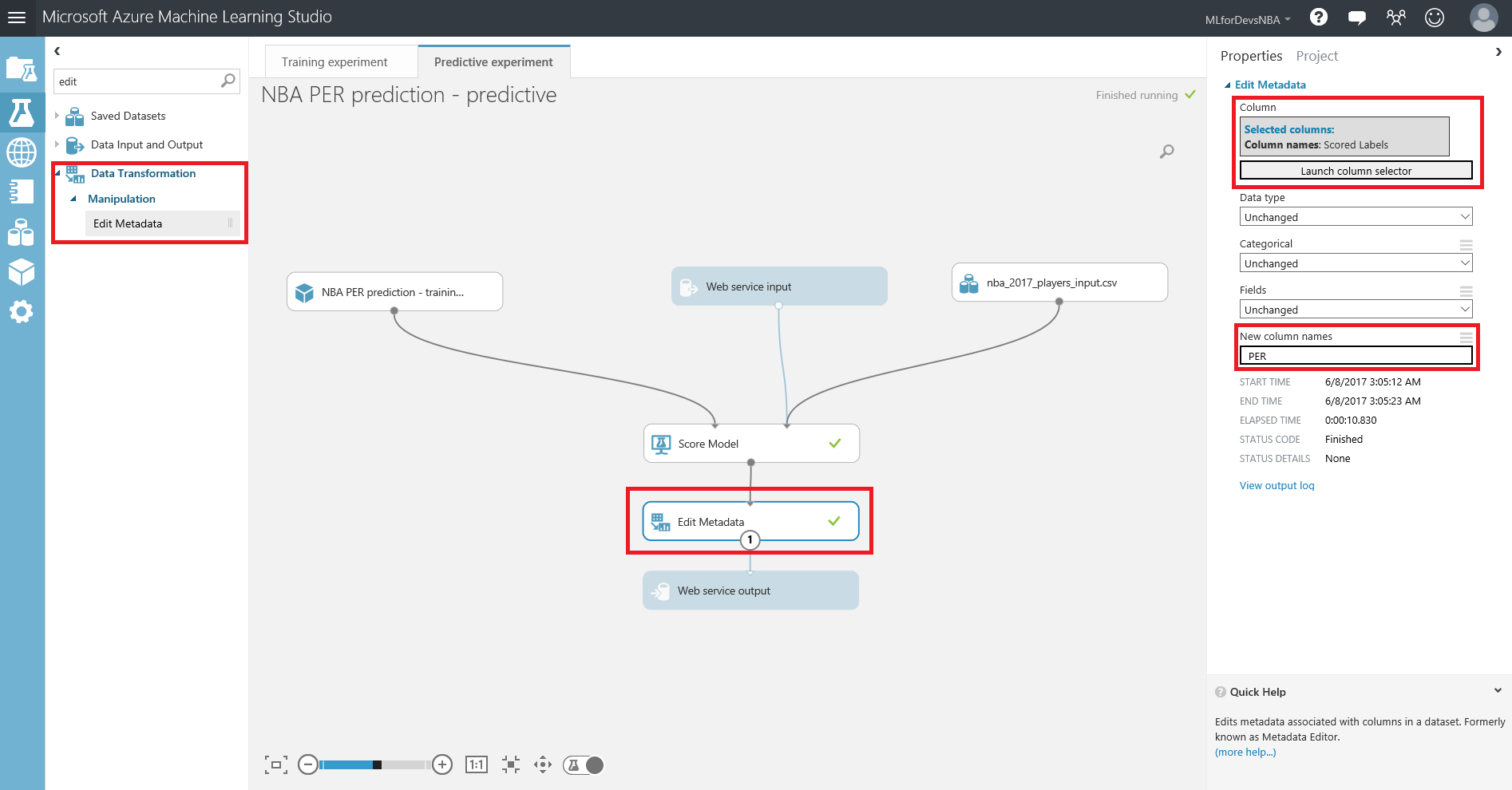



Comments
Post a Comment